
OO_Lab0_表达式的展开
BNF描述
BNF描述中去除了所有的空白项便于解析
如下是三次作业总共的BNF图:
工作流程
抽象结构
总体架构
从上面的BNF中,我们可以初步提取出下面的类:
-
表达式类(是一个加法函数,由项类组成)
-
项类(是乘法函数,由表达式组成)
-
因子类
其中因子类又包含:
-
变量因子
-
表达式因子
-
常数因子
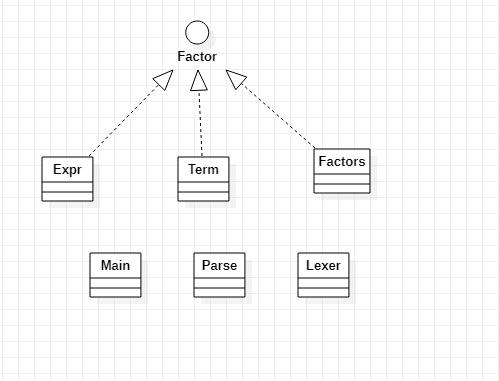
我们发现因子又包含了表达式,表达式又由项组成,因此,我们可以将因子认为是所有类的最顶层模块,可能是接口,可能是父类.
再细看要求,题目要求simpilify这一个动作,simplify可以将其拆分为各个类将自己的组成成分化简,和类之间的合并.因此,对这一个行为进行抽象,因子就是所有类的接口.
另外,对表达式类和项类这两个特殊类进行观察,能发现这两者不仅要合并其他类,还要将自己类包含的项或者因子进行合并.因此我们将这两者抽象出来一个新的父类,该父类有一个属性用来保存该类的组成部分,还要有一个合并因子的函数用于合并因子,另外还要有一个判断是否符合合并要求的方法留给子类自己重写,让子类控制合并行为.
因此我们的基本的UML图如下(Factors指代除了表达式因子的因子们):
但是,其中自定义函数和求和函数是第二次作业提出,这两个函数涉及到形参换成实参,并且函数之间相等的判断也特别复杂,因此我的思路是在解析阶段就完成形参实参替换,并把字符串替换结果交给第一次作业就已经实现的解析函数,将解析函数的返回值返回给上层函数,完成对函数的解析,因此这两个类不放入表达式化简过程,而是将其在解析阶段完成解析.
最终我们的UML图如下(只列出重要的函数):
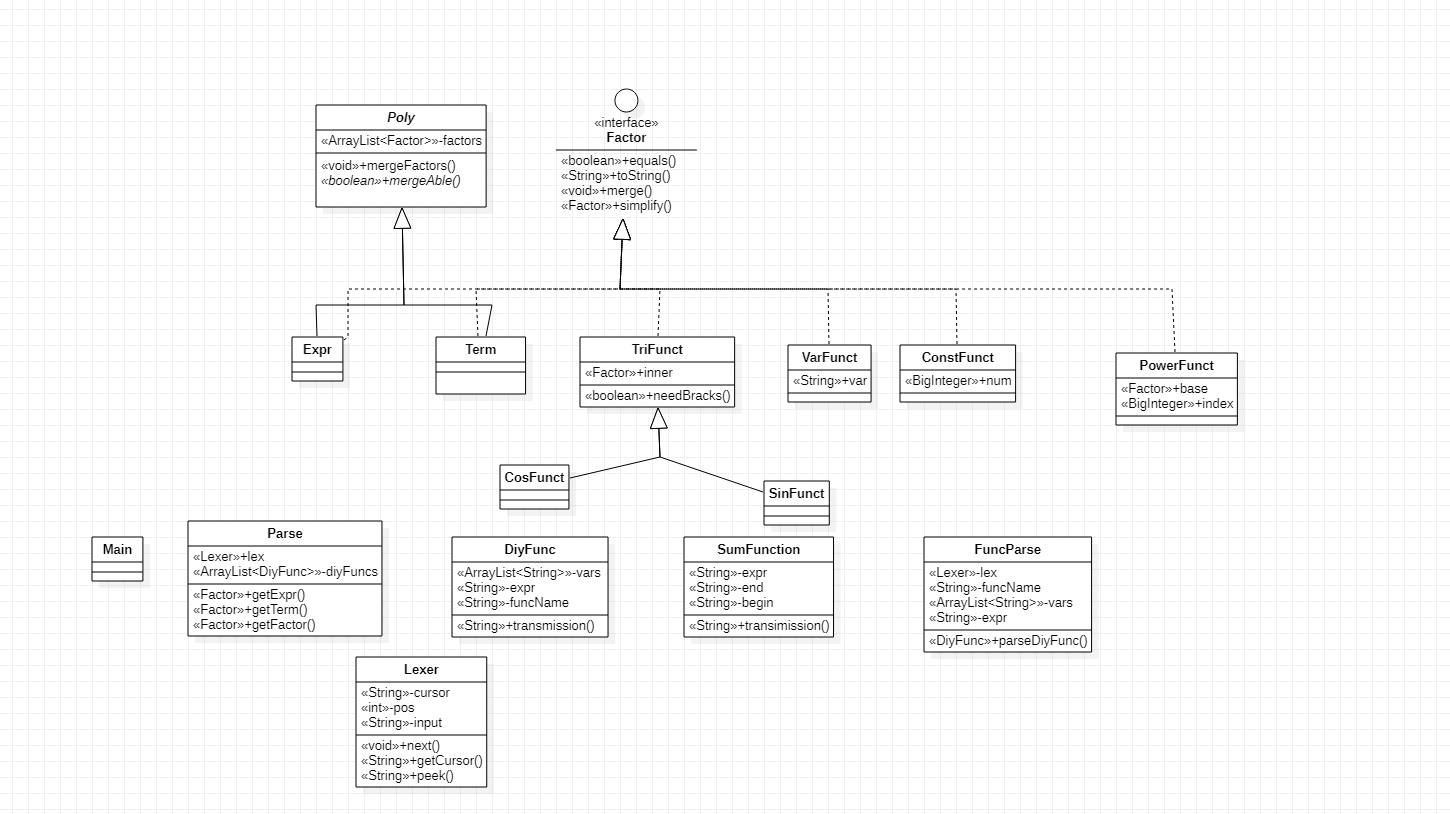
函数解释
FuncParse是解析输入的自定义函数定义的类,parseDiyFunc方法返回一个DiyFunc对象.DiyFunc和SumFunction的transmission方法是处理输入的自定义函数调用或者求和函数,返回替换之后的字符串.Poly的margeAble方法是一个抽象方法,留给Expr和Term类自己重写,自定义什么情况两者算同类相,需要合并.Factor的merge方法是实现接口的类和自己同类型相互合并的方法,该方法不修改对象本身,而是返回一个新的对象.
对于第三次作业提出的嵌套函数,我也在保留原有架构的基础上,使用的是自下而上的递归实现字符串替换.
原有函数解析架构:
-
读取函数定义,储存函数的形参,函数名和表达式
-
读取函数调用,获得实参
-
建立实参和形参之间的
hashtable -
遍历表达式,将形参转换成实参
自下而上的递归实现就是
在获得实参的时候,调用parseTerm函数去解析,最后将Term的String输出当作实参,这样不论是参数里面的嵌套调用还是求和函数求和因子里面的嵌套调用都能解决.
细节实现
连续正负号
在本题中连续正负号是一个很大的问题,因此我虽然抽象Expr类为加法函数,但我parseExpr并不处理正负号,我把连续正负号当作连续正负1相乘,这样就是带符号整数,变成因子了,交给parseTerm来统一处理
化简
对于简单因子的简化没什么好说的,提一下Term类的合并同类项.
我使用的是Arraylist,没有使用hashmap,所以我合并因子的方法是先将每一个因子化简,其中常量特别提出来,放到第0个位置,这样除此化简之后,我的项结构如下:
其中\(C\)是常量,如果化简后因子中有表达式因子,那么就需要开括号,不然直接就去把同类项相乘.
开括号创建函数unfold.该函数的实现是基于乘法分配律,既
我们可以看到实际就是表达式将自己的项依次拿出来,两个因子合并成为新的因子.
因此整个Term的化简流程如下:
随机数据生成器
前两次作业我写了随机数据生成器和基于python和sympy的对拍工具,第三次作业因为嵌套的引入,使得数据生成时候解析成sympy能使用的格式时工作加大,于是放弃,只将自己的parse结果和最后的输出进行对拍,对化简进行单元测试.三次作业随机数据生成器都是基于递归下降,现在简单总结一下:
-
第一次作业,也是最简单的作业,基于给的BNF还是很好写的,就不赘述了.
-
第二次作业,我原本时在第一次上进行迭代的,但是第二次作业引入了新的自定义函数,自定义函数生成的时候有很多对因子的限制,导致我不得不使用很多变量来限制生成数据时候的选择,比如函数生成时变量的改变,求和函数的求和因子不能时表达式因子等.
-
第三次作业,规则引入更多,而之前的数据生成器已经是300行的屎山代码了,因此我重构代码,引入了DiyFunc和SumFunc两个类来生成自己的数据,做到表达式,自定义函数和求和函数生成的低耦合,再重写__str__方法,直接输出即可.另外对于项的总数和因子总数等也可以定义为全局变量,可以很好的自己控制数据复杂度.
基本架构如下:(对于递归深度的控制并没有写入,但难度并不大,请读者自行思考)
from random import randint
def getExpr(numofTerm = 0):
ret = ""
if(numofTerm == 0):
ret = getAddorSub(0)
ret += getTerm()
if(numofTerm< maxTerm and randint(1,100) < 50+numofTerm*10):
ret += getAddorSub(0)
ret += getExpr(numofTerm=numofTerm+1)
return ret
def getTerm(numoFactor = 0):
ret = ""
if (numoFactor == 0):
ret += getAddorSub(1)
ret += getFactor()
if(numoFactor< maxFactor and randint(1,100) < 50+numoFactor*10):
ret += "*"
ret += getTerm(numoFactor=numoFactor+1)
return ret
def getFactor():
op = randint(0,2)
if(op == 0): ##常数因子
return str(randint(-10,10))
elif(op == 1): ##变量因子
return getVar()
elif(op == 2): ## 表达式因子
ret = "(" + getExpr() + ")"
ret += getIndex()
return ret
对于对拍,我使用的了subprocess(),这样就不需要额外生成文件也能获得程序输出,大概用法如下
import subprocess
sb = subprocess.Popen(command,stdout=subprocess.PIPE,stdin=subprocess.PIPE)
sb.stdin.write(bytes("3\n",encoding = 'utf-8'))
sb.stdin.write(bytes("f(x,y,z)="+F.expr+"\n",encoding='utf-8'))
sb.stdin.write(bytes("g(x,y,z)="+G.expr+"\n",encoding='utf-8'))
sb.stdin.write(bytes("h(x,y,z)="+H.expr+"\n",encoding='utf-8'))
sb.stdin.write(bytes(ExprToJava,encoding = 'utf-8'));
sb.stdin.close();
outText = sb.stdout.read().decode("utf-8").replace("Mode: Normal\r"," ");
sb.stdout.close();
最后正确性检验,sympy检验代码如下
if sympify(expr1 - expr2):
print("True")
else :
print("Wrong Answer")
print("Answer" + simplify(expr1))
debug总结
个人bug发现
个人整个作业完成下来,最严重的两个bug分别是对象引用的问题和-1这个因子解析的问题,下面做分析
- 类引用的问题:
java对于对象是引用,所以如果两个变量实际是指向同一个对象,那么就会出现神奇的bug.比如(sin(x)**2+cos(x)*sin(x))**2,本来按照乘法分配律展开是
式中\(sin(x)**2\)都指向的是同一个对象,所以第一个\(sin(x)**2*sin(x)**2\)化简的时候,后面所有的\(sin(x)**2\)全部变成了\(sin(x)**4\),对此我的方法是把所有因子变成不可变对象,merge方法得返回值不是原本得对象,而是重新new了一个,每一个因子都没有set方法,这样因子的状态就不会改变了.
- -1的解析:在我的架构中
-1解析成了-1*1,也就是说输入的每一个带符号整数,在定义中是属于因子,到我的架构里面其实是一个项,但是在后续作业中我忘记了这一个区别,导致抛出了异常.
互测bug发现
在互测中发现了一些很有意思的bug,先列举几个很有意思的.
-
过度优化导致牺牲正确性:后面作业互测中发现了有同学优化了
cos(x)**2+sin(x)**2 = 1,这本来是一个很厉害的优化,但是在实际互测中发现有同学的优化是基于原有架构上的拆东墙补西墙,把原本架构的一些细节改变,但没有填补.比如第三次作业,三角函数中可以放表达式因子,那么在判断是否能优化的时候就要判断三角函数里面的因子是否相等,因此有人又修改了表达式因子的equals方法,但这又导致了在项合并同类项中表达式因子合并出现了bug.因此,我认为优化应该是基于能完成需求的基础上,不能为了优化而去优化. -
放弃优化导致牺牲时间复杂度:我也碰见了有的同学放弃了合并同类项,导致输出巨长,放一个比较复杂的数据,因为没有合并同类项,导致在开括号的时候项一级的因子越来越多,如果指数大一点就直接跑不出结果了.
总体总结
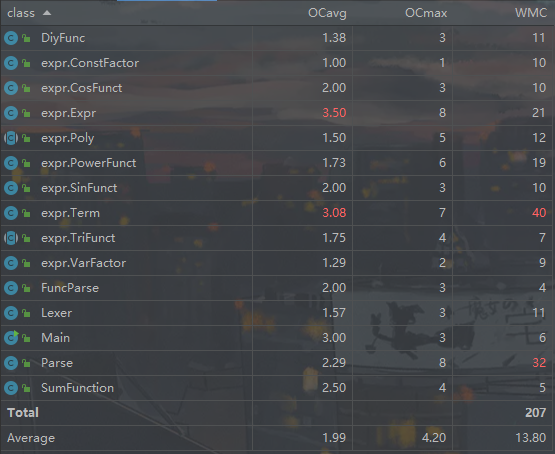
总结之前先来一张全家福
复杂度分析
可见我的复杂度还行(),项和表达式因为组成复杂,优化有一点难度,至于parse,因为因子太多不得不塞很多函数进去,能做成这样还是比较满意的.
整个作业自我感觉除了第一次比较艰难,后面都挺轻松.可能是我第一次在架构上拓展性比较强,没有仅为了实现第一次的需求而去建立架构,而是留了很多可拓展的地方,
比如:
-
第一次作业我就已经能解决嵌套括号的问题
-
对于新增加的因子我也有了一套比较完整的实现模型
-
对于新增因子的合并我在项和表达式一级也解开了耦合,让这两个类能更好的自己控制合并同类项这一个行为.
可见架构的可拓展性对于后续开发的重要性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号