pairwise损失_triplet损失_提升精排模型的trick
01标签
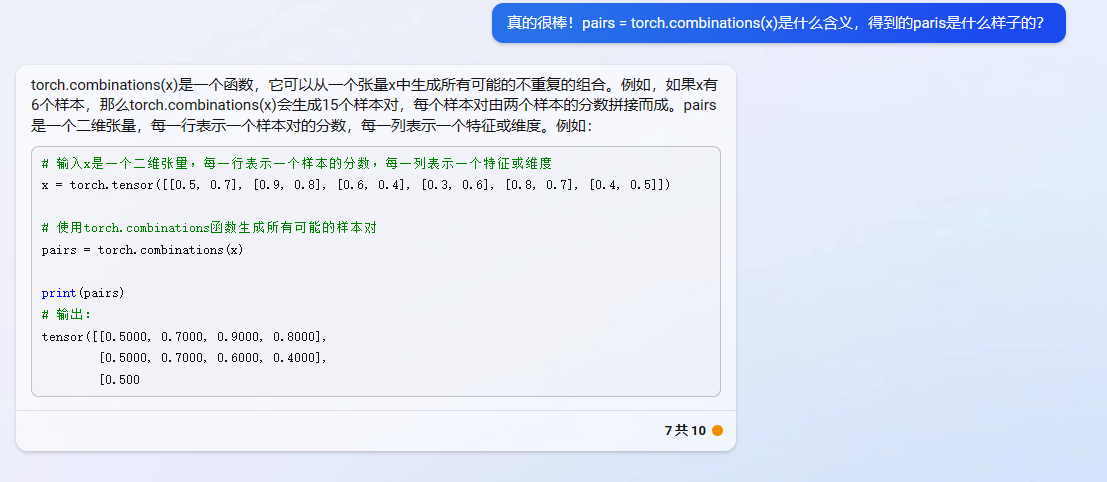
import torch
import torch.nn as nn
# 输入x是一个二维张量,每一行表示一个样本的分数,每一列表示一个特征或维度
x = torch.tensor([[0.5, 0.7], [0.9, 0.8], [0.6, 0.4], [0.3, 0.6], [0.8, 0.7], [0.4, 0.5]])
# 标签y是一个一维张量,表示样本之间的顺序关系(-1或1)
y = torch.tensor([1, -1, 1, -1, -1, 1])
# 创建一个marginRankingLoss对象,设置边界为0.2
loss_fn = nn.MarginRankingLoss(margin=0.2)
# 使用torch.combinations函数生成所有可能的样本对
pairs = torch.combinations(x)
# 将pairs分成两个张量,分别表示第一个和第二个样本的分数
x1 = pairs[:, :2]
x2 = pairs[:, 2:]
# 计算损失值
loss = loss_fn(x1, x2, y)
print(loss) # 输出:tensor(3.)
多标签
import torch
import torch.nn as nn
# 定义一个batch内数据的大小和维度
batch_size = 16
input_dim = 128
# 随机生成一个batch内数据的特征向量
x = torch.randn(batch_size, input_dim)
# 随机生成一个batch内数据的标签(0,1,2,3或4)
y = torch.randint(0, 5, (batch_size,))
# 定义一个预测模型,比如一个线性层
model = nn.Linear(input_dim, 1)
# 得到预测分数
scores = model(x)
# 定义pairwise loss函数,比如MarginRankingLoss
loss_fn = nn.MarginRankingLoss(margin=1.0)
# 初始化pairwise loss为0
loss = 0
# 对于每个query,从batch中选择两个document,一个正例(标签大于0),一个负例(标签等于0)
for i in range(batch_size):
# 找到正例和负例的索引
pos_idx = (y > 0) & (y != y[i])
neg_idx = (y == 0) & (y != y[i])
# 如果找不到正例或负例,则跳过该query
if not pos_idx.any() or not neg_idx.any():
continue
# 随机选择一个正例和一个负例
pos_score = scores[pos_idx].squeeze()[torch.randint(0, pos_idx.sum(), (1,))]
neg_score = scores[neg_idx].squeeze()[torch.randint(0, neg_idx.sum(), (1,))]
# 计算正例和负例之间的边缘损失,并累加到pairwise loss中
target = torch.tensor([1.0])
loss += loss_fn(pos_score, neg_score, target)
# 对所有query和document对求平均,得到最终的pairwise loss
loss /= batch_size
print(loss)
import torch
# 定义pairwise_loss损失函数
def pairwise_loss(scores, labels):
"""
计算一个batch内数据的pairwise损失
:param scores: tensor类型,表示模型输出的分数,shape为(batch_size, num_items)
:param labels: tensor类型,表示每个样本的真实标签,shape为(batch_size, num_items)
:return: pairwise损失
"""
# 计算每个正样本和负样本之间的得分差
pos_scores = scores.unsqueeze(2) # (batch_size, num_items, 1)
neg_scores = scores.unsqueeze(1) # (batch_size, 1, num_items)
diff_scores = pos_scores - neg_scores # (batch_size, num_items, num_items)
# 构造一个mask,排除掉无效的比较
pos_mask = (labels.unsqueeze(2) > 0) # (batch_size, num_items, 1)
neg_mask = (labels.unsqueeze(1) < 1) # (batch_size, 1, num_items)
mask = pos_mask & neg_mask # (batch_size, num_items, num_items)
# 计算pairwise损失
loss = torch.log(1 + torch.exp(-diff_scores)) # (batch_size, num_items, num_items)
loss = loss * mask.float() # (batch_size, num_items, num_items)
loss = loss.sum(dim=(1, 2)) # (batch_size,)
loss = loss.mean() # scalar
return loss
其中,scores和labels分别是模型输出的分数和每个样本的真实标签,batch_size表示batch的大小,num_items表示每个样本中的物品数。具体实现过程如下:
- 首先,我们计算每个正样本和负样本之间的得分差。由于pytorch的broadcast机制,
pos_scores和neg_scores的shape都是(batch_size, num_items, num_items),表示将得分向量复制成矩阵的形式。 - 接着,我们构造一个mask,排除掉无效的比较。
pos_mask表示每个样本中真实标签为正的物品,neg_mask表示每个样本中真实标签为负的物品,两者相交得到的mask表示可以进行比较的物品对。 - 然后,我们计算pairwise损失。
torch.log和torch.exp分别表示取对数和指数操作,-diff_scores表示将得分差取负数,torch.log(1 + torch.exp(-diff_scores))表示计算logistic函数的损失,即logistic loss。最后,我们将mask和损失相乘并在dim=(1, 2)的维度上求和,得到每个样本的损失,最终求取batch的平均损失。
01标签
@豆子君 如果精排数据的标签只有0和1,可以将原有的pairwise loss稍作修改得到新的代码。具体来说,只需要将原有的`pos_mask`中大于0的条件改成等于1的条件即可。下面是修改后的代码:
``` python
import torch
# 定义pairwise_loss损失函数
def pairwise_loss(scores, labels):
"""
计算一个batch内数据的pairwise损失
:param scores: tensor类型,表示模型输出的分数,shape为(batch_size, num_items)
:param labels: tensor类型,表示每个样本的真实标签,shape为(batch_size, num_items)
:return: pairwise损失
"""
# 计算每个正样本和负样本之间的得分差
pos_scores = scores.unsqueeze(2) # (batch_size, num_items, 1)
neg_scores = scores.unsqueeze(1) # (batch_size, 1, num_items)
diff_scores = pos_scores - neg_scores # (batch_size, num_items, num_items)
# 构造一个mask,排除掉无效的比较
pos_mask = (labels.unsqueeze(2) == 1) # (batch_size, num_items, 1)
neg_mask = (labels.unsqueeze(1) == 0) # (batch_size, 1, num_items)
mask = pos_mask & neg_mask # (batch_size, num_items, num_items)
# 计算pairwise损失
loss = torch.log(1 + torch.exp(-diff_scores)) # (batch_size, num_items, num_items)
loss = loss * mask.float() # (batch_size, num_items, num_items)
loss = loss.sum(dim=(1, 2)) # (batch_size,)
loss = loss.mean() # scalar
return loss
这里我们只需要将pos_mask和neg_mask中原有的大于0的条件改成等于1和等于0的条件即可。这样修改后,当标签只有0和1时,计算pairwise loss的方法依然适用。
Pairwise Ranking Loss的变体
Pairwise Ranking Loss是训练排序模型的经典损失函数,但它也存在一些缺陷,比如无法处理等级差异较大的样本,以及对负样本的采样要求较高等问题。为了解决这些问题,可以对Pairwise Ranking Loss进行改进。例如,采用N-pair Loss、Smooth Ranking Loss等变体,这些损失函数可以更好地处理等级差异和不同数量级的负样本。
下面是使用pytorch实现N-pair Loss的代码:
import torch
def npair_loss(scores, labels):
"""
计算N-pair Loss
:param scores: tensor类型,表示模型输出的分数,shape为(batch_size, num_items)
:param labels: tensor类型,表示每个样本的真实标签,shape为(batch_size, num_items)
:return: N-pair Loss
"""
batch_size, num_items = scores.shape
# 计算相似度矩阵
sim_mat = torch.matmul(scores, scores.t())
# 构造mask矩阵
mask = labels.unsqueeze(1).eq(labels.unsqueeze(0)).float()
# 排除掉相同的样本
mask = mask.fill_diagonal_(0)
# 计算N-pair Loss
neg_sim = sim_mat.masked_fill(mask.bool(), float('-inf'))
neg_sim = torch.logsumexp(neg_sim, dim=1, keepdim=True)
pos_sim = sim_mat.diag().unsqueeze(1)
loss = neg_sim - pos_sim + math.log(num_items - 1)
return loss.mean()
特征交叉
特征交叉是指将不同的特征进行组合,生成新的特征。这样做可以使模型更好地学习复杂的特征组合,提高排序的性能。常用的特征交叉方法包括:FM、FFM、DeepFM等。其中,FM可以看做是特征交叉的一种简单形式。
下面是使用pytorch实现FM的代码:
import torch
class FM(torch.nn.Module):
def __init__(self, num_features, embedding_dim):
super().__init__()
self.num_features = num_features
self.embedding_dim = embedding_dim
self.linear = torch.nn.Linear(num_features, 1)
self.embedding = torch.nn.Embedding(num_features, embedding_dim)
def forward(self, x):
# 计算一阶特征
linear_terms = self.linear(x).squeeze()
# 计算二阶特征
interactions = self.embedding(x)
square_of_sum = interactions.sum(dim=1).pow(2)
sum_of_square = interactions.pow(2).sum(dim=1)
quadratic_terms = 0.5 * (square_of_sum - sum_of_square).sum(dim=1)
# 合并一阶特征和二阶特征
y = linear_terms + quadratic_terms
return y
多任务学习
多任务学习是指在一个模型中同时学习多个任务,可以提高模型的泛化能力,减少过拟合的风险,同时也可以提高模型的效率。应用到精排模型中,可以在排序任务的同时,学习一些辅助任务,比如CTR预估、相关性预测等。多任务学习的关键在于如何设计合适的损失函数,常用的方法包括:Joint Learning、Multi-Task Learning、Distillation等。
下面是使用pytorch实现Joint Learning的代码:
import torch
class JointRankingCTRModel(torch.nn.Module):
def __init__(self, num_items, num_features, embedding_dim, hidden_dims):
super().__init__()
self.num_items = num_items
self.num_features = num_features
self.embedding_dim = embedding_dim
self.hidden_dims = hidden_dims
# 点击率预测部分
self.ctrs = torch.nn.Sequential(
torch.nn.Linear(num_features, hidden_dims[0]),
torch.nn.ReLU(),
torch.nn.Linear(hidden_dims[0], hidden_dims[1]),
torch.nn.ReLU(),
torch.nn.Linear(hidden_dims[1], 1)
)
# 排序部分
self.item_embedding = torch.nn.Embedding(num_items, embedding_dim)
self.user_embedding = torch.nn.Embedding(num_items, embedding_dim)
def forward(self, x, item_ids):
# 点击率预测部分
ctr_scores = self.ctrs(x)
# 排序部分
item_embeds = self.item_embedding(item_ids)
user_embeds = self.user_embedding(torch.zeros_like(item_ids))
scores = (item_embeds * user_embeds).sum(dim=1)
return scores, ctr_scores
def joint_loss(self, scores, ctr_scores, labels, ctr_labels, alpha=0.5):
ranking_loss = pairwise_loss(scores, labels)
ctr_loss = torch.nn.BCEWithLogitsLoss()(ctr_scores, ctr_labels.unsqueeze(1).float())
loss = alpha * ranking_loss + (1 - alpha) * ctr_loss
return loss
这里我们定义了一个继承自torch.nn.Module的模型,包含两部分:排序部分和点击率预测部分。其中,排序部分采用了item embedding和user embedding进行特征交叉,得到每个物品的打分。点击率预测部分则是一个基于MLP的CTR模型,用于预测用户对每个物品的点击概率。在训练时,我们将排序损失和CTR损失进行加权得到总损失。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号