

Python爬取全球各国疫情实时动态及数据分析
(一)、选题的背景
由于疫情原因的影响,世界各地都因为新型冠状病毒(简称新冠肺炎)而陷入种种危机。因此,对于现存全球的疫情数据我进行了一个爬取和一些数据分析,并作出数据可视化处理,更加直观的查看出全球现存疫情的情况。
(二)、主题式网络爬虫设计方案
1.主题式网络爬虫名称
全球疫情实施动态爬取
2.主题式网络爬虫爬取的内容与数据特征分析
爬取多国的当日新增确诊,当日新增治愈,当日新增死亡,病死率以及累计治愈,从而作出分析。
3.主题式网络爬虫设计方案概述
使用爬虫爬取【网易新闻 肺炎疫情实时动态播报】页面信息,然后将爬取的数据存储为csv格式文件,再读取csv文件,对数据进行相应的处理,最后对处理后的数据进行可视化分析。
(三)、主题页面的结构特征分析
1.主题页面的结构与特征分析
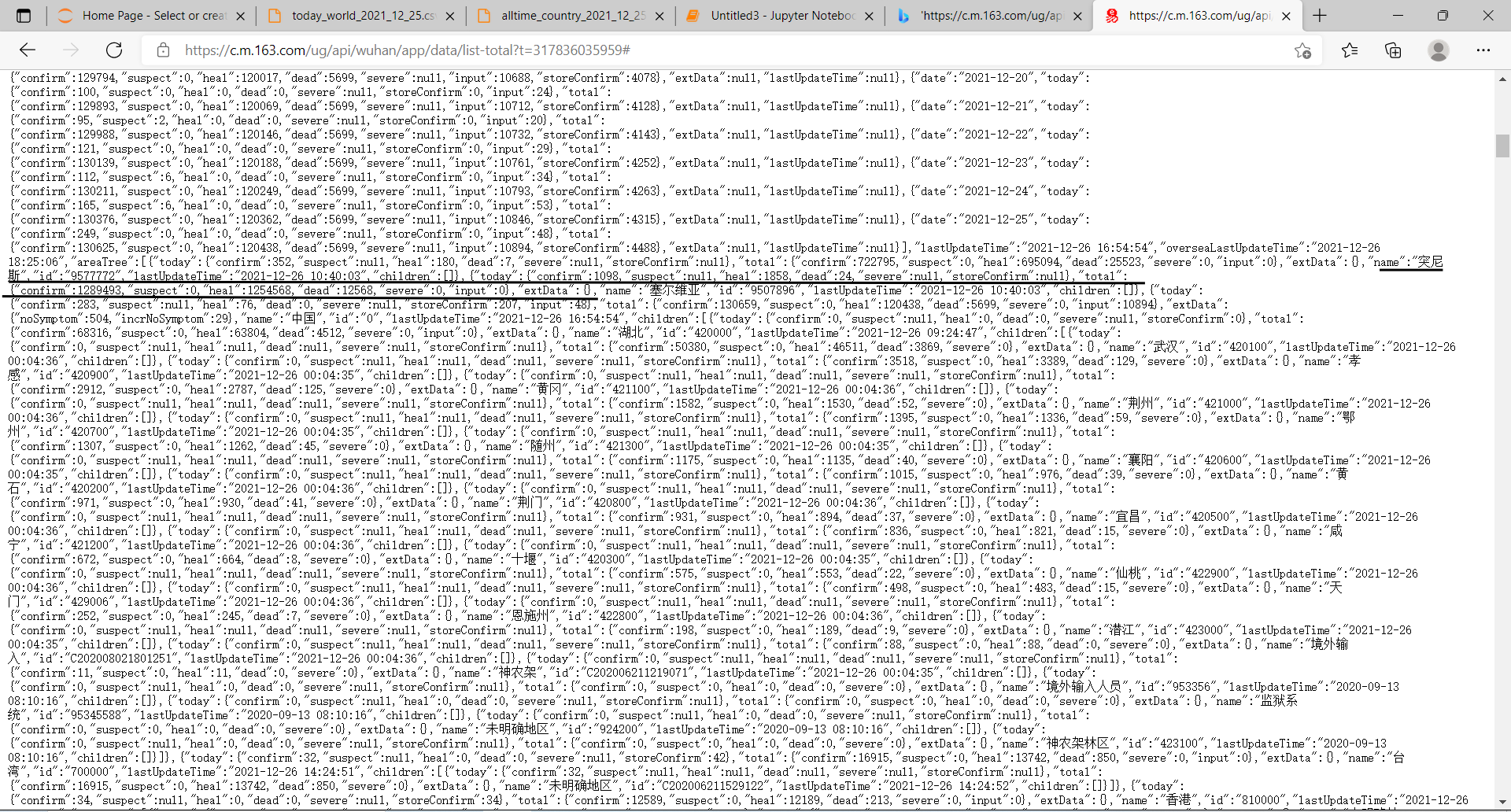
爬取界面josn格式展示:
2.Htmls 页面解析
josn格式可以观察到每个数据都可以通过索引得到。通过字典索引即可得到需要数据
3.节点(标签)查找方法与遍历方法
通过data,keys()获取字典键再对其索引遍历,通过reaTree = data['areaTree'] 获取各国数据,索引前先对data['areaTree'][1]进行分析数据的索引字符串,再通过遍历对需要数据爬取添加。
(四)、网络爬虫程序设计
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
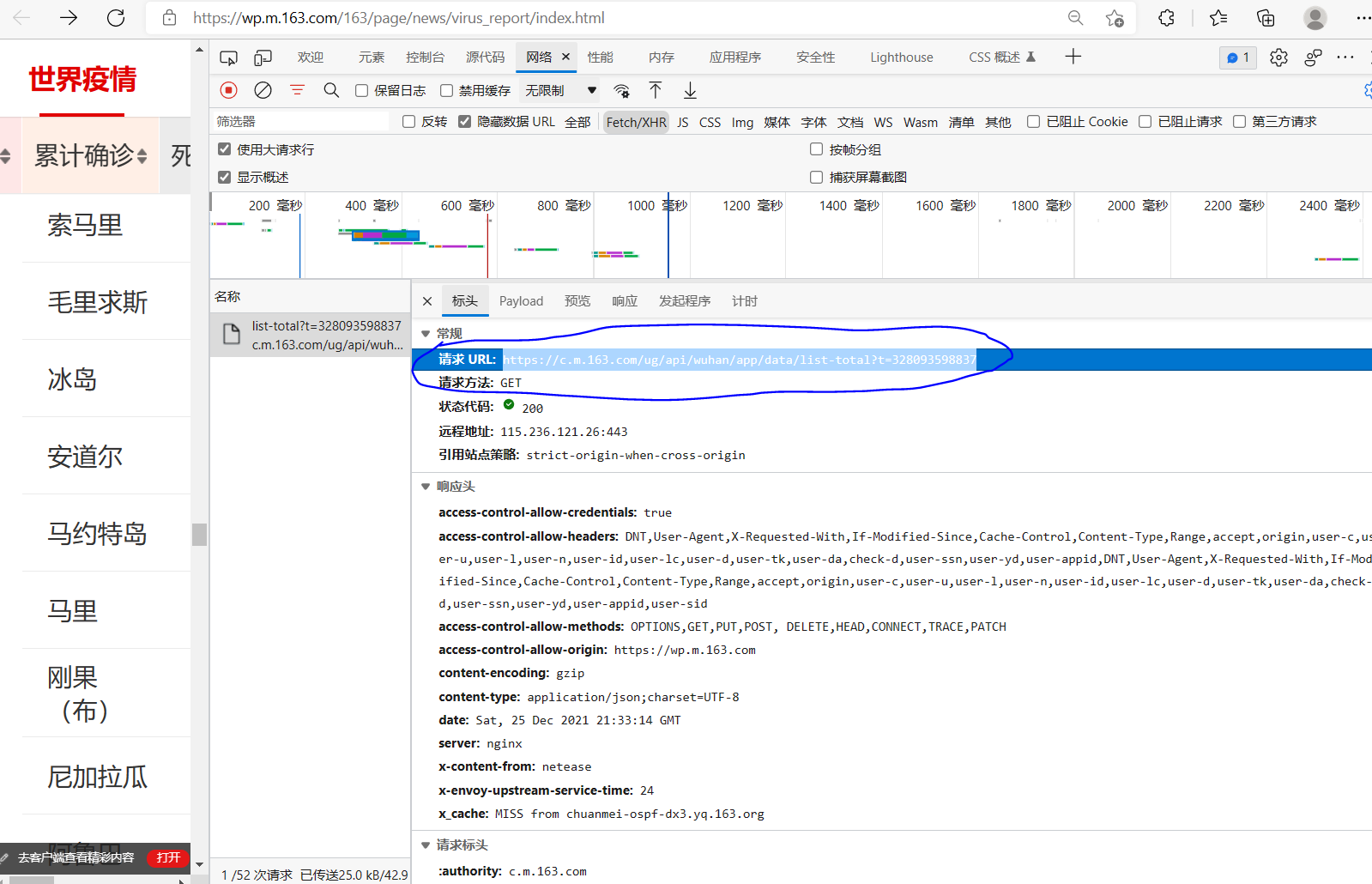
进入需要爬取的目标网址 https://wp.m.163.com/163/page/news/virus_report/index.html
通过响应network找到数据源如下:
(https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=328093598837)

伪装浏览器,headers如下:headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'})
使用requests库对目标网址进行请求,打印响应码:
源码:
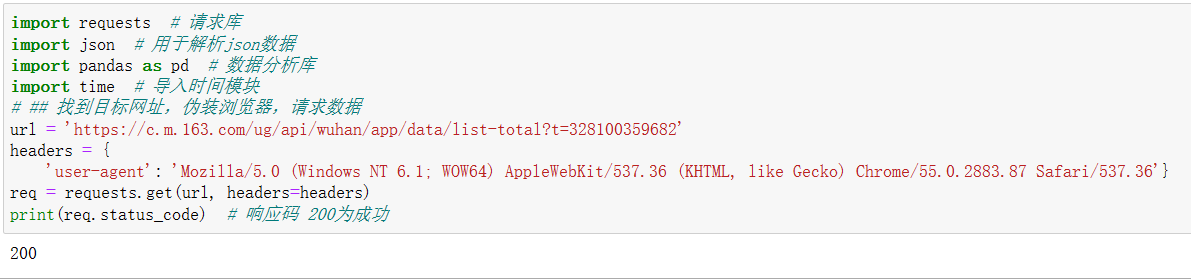
1 import requests # 请求库 2 import json # 用于解析json数据 3 import pandas as pd # 数据分析库 4 import time # 导入时间模块 5 # ## 找到目标网址,伪装浏览器,请求数据 6 url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=328100359682' 7 headers = { 8 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'} 9 req = requests.get(url, headers=headers) 10 print(req.status_code) # 响应码 200为成功
截图展示:
打印响应内容(这里不知道为什么响应内容只显示在一行,但是并不影响操作):
![]()
使用Json模块对响应内容进行初步解析
data_json = json.loads(req.text) #使用json.loads将json字符串转化为字典
打印字典的key值源码: 1 data_json = json.loads(req.text) 2 data_json.keys()
截图展示:
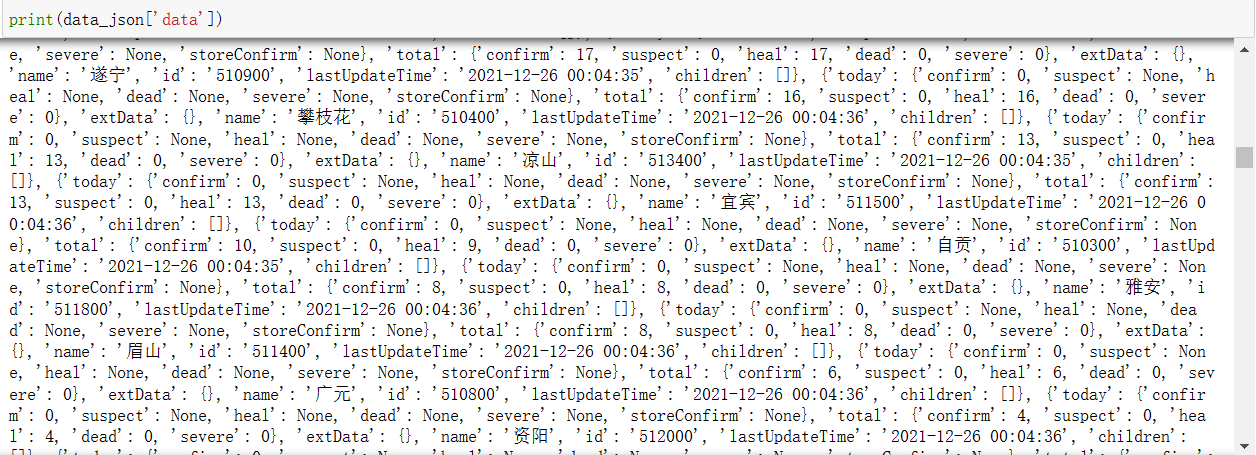
可以看到我们需要的是其中的data数据,再次打印data查看结果。
源码: 1 print(data_json['data'])
截图展示:
有点混乱,可以看到其仍然为字典,再次打印data的key值,得到关键信息。
源码: 1 print(data_json['data'].keys())
截图展示:
前两个和中国有关,第3、4个和更新时间有关,最后一个不太确定是啥,打印再看看。
源码:1 print(data_json['data']['areaTree'])
截图展示:
这次我们可以看到出现了很多国家的名字,按照猜测应该是对应网页这块
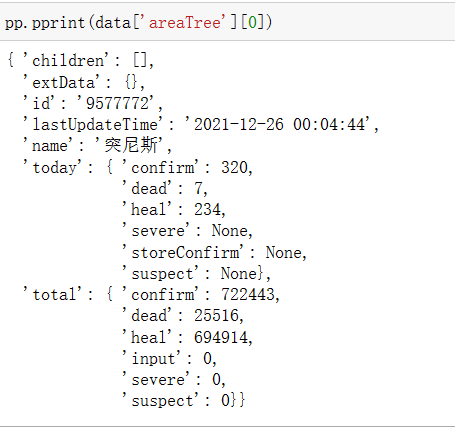
使用PrettyPrinter打印字典(PrettyPrinter格式化输出字典)
源码: 1 pp.pprint(data['areaTree'][0])
截图展示:
可以看到areaTree的数据格式是list,里面每一个国家对应一个字典,而字典中又嵌套着字典。
(1)获取areaTree数据
areaTree = data['areaTree']
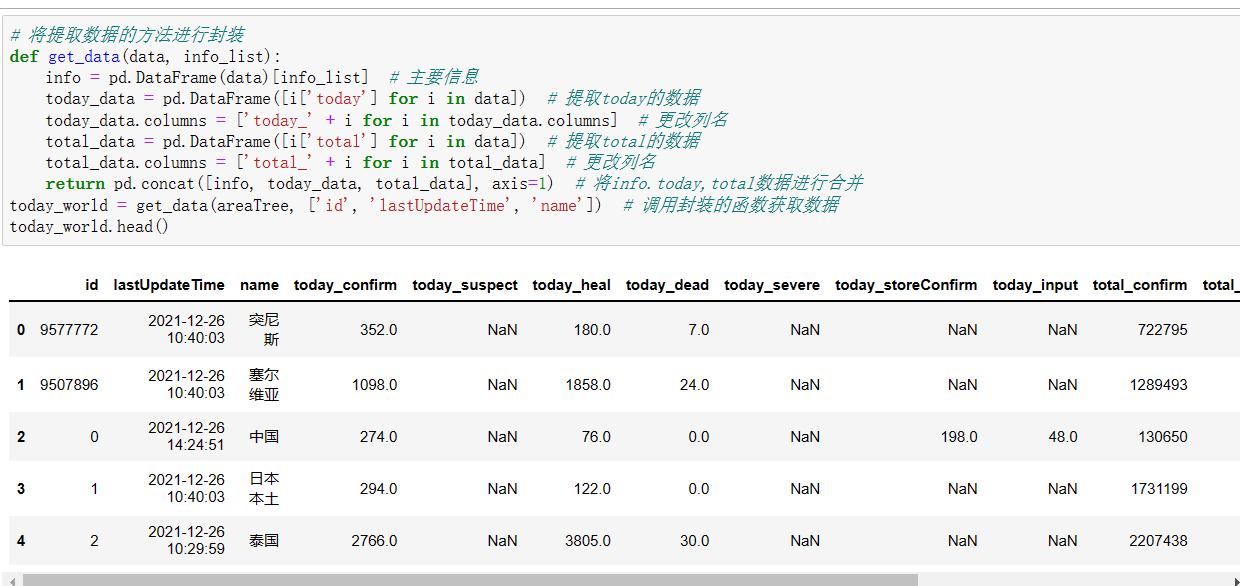
(2)获取数据源码:
1 # 将提取数据的方法进行封装 2 def get_data(data, info_list): 3 info = pd.DataFrame(data)[info_list] # 主要信息 4 today_data = pd.DataFrame([i['today'] for i in data]) # 提取today的数据 5 today_data.columns = ['today_' + i for i in today_data.columns] # 更改列名 6 total_data = pd.DataFrame([i['total'] for i in data]) # 提取total的数据 7 total_data.columns = ['total_' + i for i in total_data] # 更改列名 8 return pd.concat([info, today_data, total_data], axis=1) # 将info.today,total数据进行合并 9 today_world = get_data(areaTree, ['id', 'lastUpdateTime', 'name']) # 调用封装的函数获取数据 10 today_world.head()截图展示:
存储数据
源码:




1 def save_data(data, name): 2 file_name = name + '_' + time.strftime('%Y_%m_%d', time.localtime(time.time())) + '.csv' 3 data.to_csv(file_name, sep=',', encoding='utf-8-sig') 4 print(file_name + ' 保存成功! ') 5 save_data(today_world, 'today_world')
截图展示:

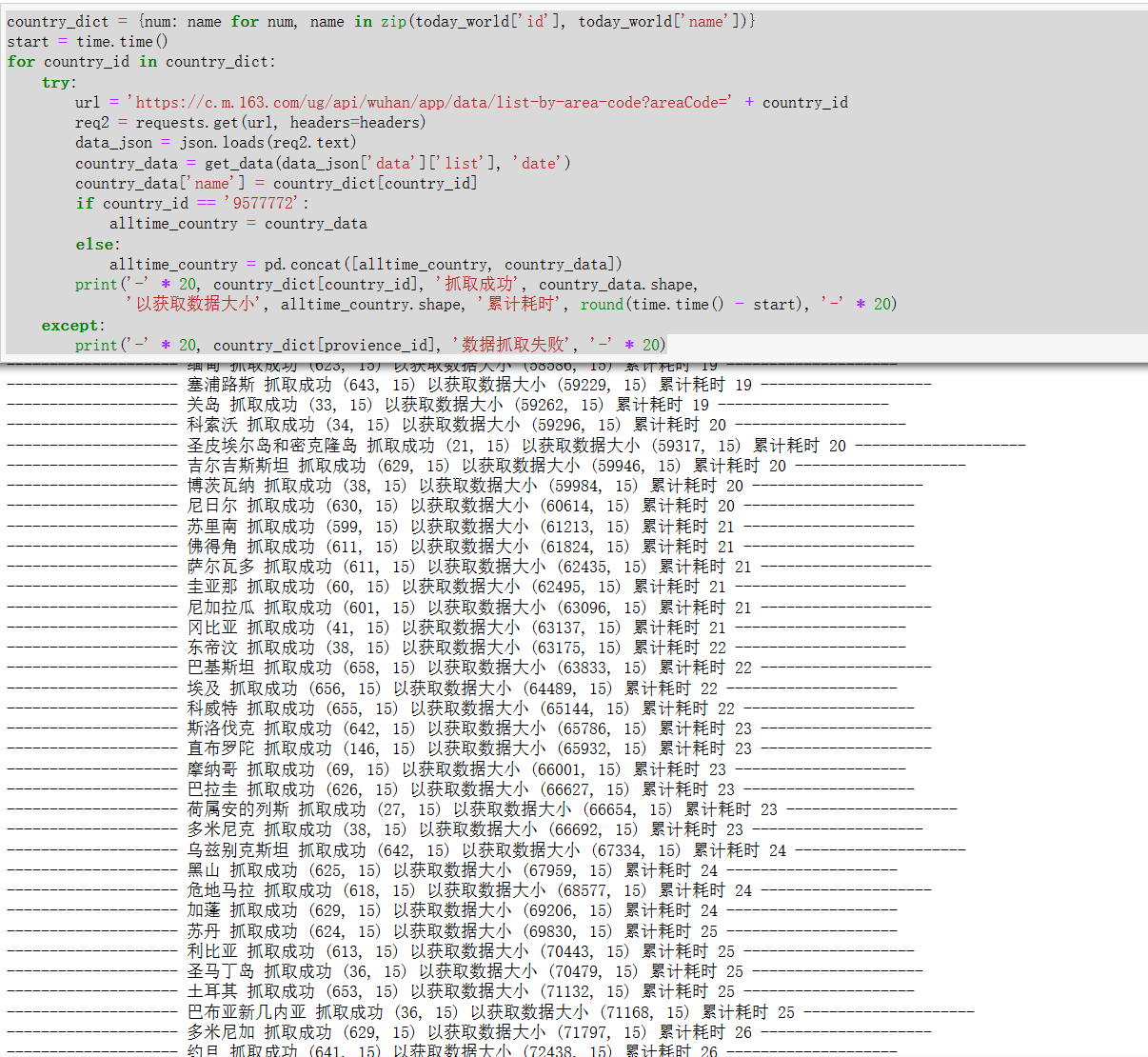
按照各国id,访问各国的数据,并获取json数据,提取各国的数据,然后写入各国的名称,然后合并数据。
源码:
1 country_dict = {num: name for num, name in zip(today_world['id'], today_world['name'])} 2 start = time.time() 3 for country_id in country_dict: 4 try: 5 url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + country_id 6 req2 = requests.get(url, headers=headers) 7 data_json = json.loads(req2.text) 8 country_data = get_data(data_json['data']['list'], 'date') 9 country_data['name'] = country_dict[country_id] 10 if country_id == '9577772': 11 alltime_country = country_data 12 else: 13 alltime_country = pd.concat([alltime_country, country_data]) 14 print('-' * 20, country_dict[country_id], '抓取成功', country_data.shape, 15 '以获取数据大小', alltime_country.shape, '累计耗时', round(time.time() - start), '-' * 20) 16 except: 17 print('-' * 20, country_dict[provience_id], '数据抓取失败', '-' * 20)
截图展示:
2.对数据进行清洗和处理
更换数据列名,将英文列名换为中文列名方便我们理解数据进行处理。
源码:
1 td_wd = pd.read_csv('today_world_2021_12_26.csv') 2 ac = pd.read_csv('alltime_country_2021_12_26.csv') 3 4 name_dict = { 5 'id': '编号', 'lastUpdateTime': '更新时间', 'name': '名称', 'today_confirm': '当日新增确诊', 6 'today_suspect': '当日新增疑似', 'today_heal': '当日新增治愈', 'today_dead': '当日新增死亡', 'today_severe': '当日新增重症', 7 'today_storeConfirm': '当日现存确诊', 'today_input': '当日新增输入', 'total_confirm': '累计确诊', 'total_suspect': '累计疑似', 8 'total_heal': '累计治愈', 'total_dead': '累计死亡', 'total_severe': '累计重症', 'total_input': '累计输入' 9 } 10 11 td_wd.rename(columns=name_dict, inplace=True) 12 ac.rename(columns=name_dict, inplace=True) 13 td_wd.head()
截图展示:

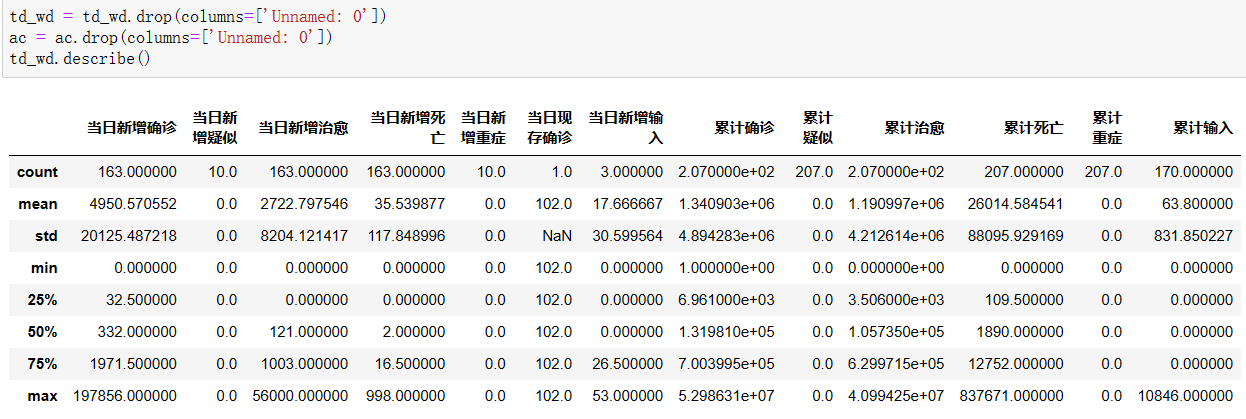
使用drop()方法删除Unnamed: 0列,使用describe()方法查看对数据的描述:
源码:
1 td_wd = td_wd.drop(columns=['Unnamed: 0']) 2 ac = ac.drop(columns=['Unnamed: 0']) 3 td_wd.describe()
截图展示:
计算【当日现存确诊】公式为:累计确诊-累计治愈-累计死亡
计算【病死率】公式为:累计死亡/累计确诊
通过数据描述可以发现NaN值特别多,那么我们可以计算一下每一列NaN值占多少
源码:
1 td_wd['当日现存确诊'] = td_wd['累计确诊'] - td_wd['累计治愈'] - td_wd['累计死亡'] 2 td_wd['病死率'] = (td_wd['累计死亡'] / td_wd['累计确诊']).apply(lambda x: format(x, '.2f')) 3 td_wd['病死率'] = td_wd['病死率'].astype('float') 4 ac['当日现存确诊'] = ac['累计确诊'] - ac['累计治愈'] - ac['累计死亡'] 5 ac['病死率'] = (ac['累计死亡'] / ac['累计确诊']).apply(lambda x: format(x, '.2f')) 6 ac['病死率'] = ac['病死率'].astype('float') 7 print('统计nan值:') 8 td_wd_nan = td_wd.isnull().sum() / len(td_wd) 9 td_wd_nan.apply(lambda x: format(x, '.1%'))
截图展示:

使用isnull()方法查看DataFrame数据的NaN值,并用sum()方法进行求和,除以总大小。
使用sort_values方法对DataFrame进行排序,排序方式以病死率,按降序方式,得到如下结果:
源码: 1 td_wd.sort_values('病死率', ascending=False, inplace=True) 2 td_wd.head()
截图展示:
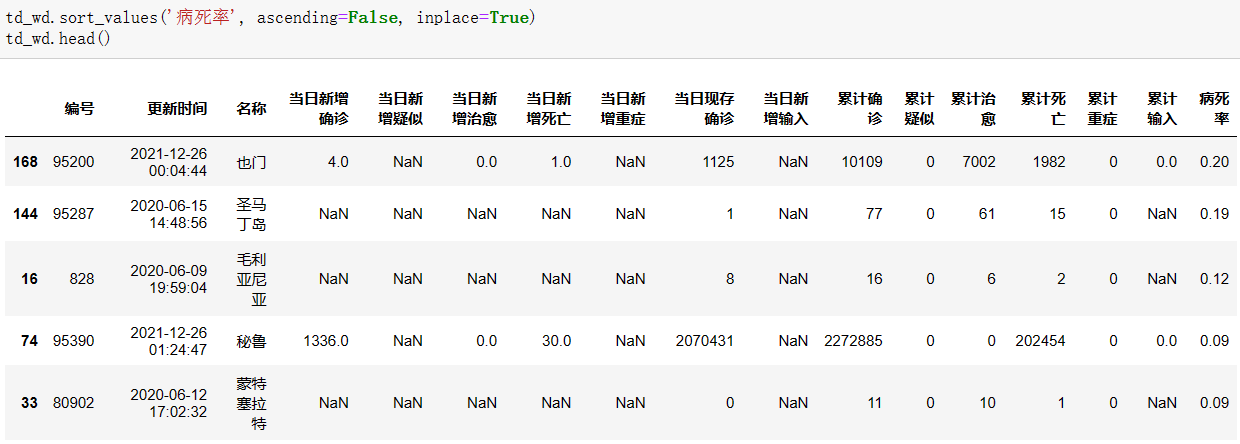
将索引改为国家名称:
td_wd.set_index('名称',inplace=True)
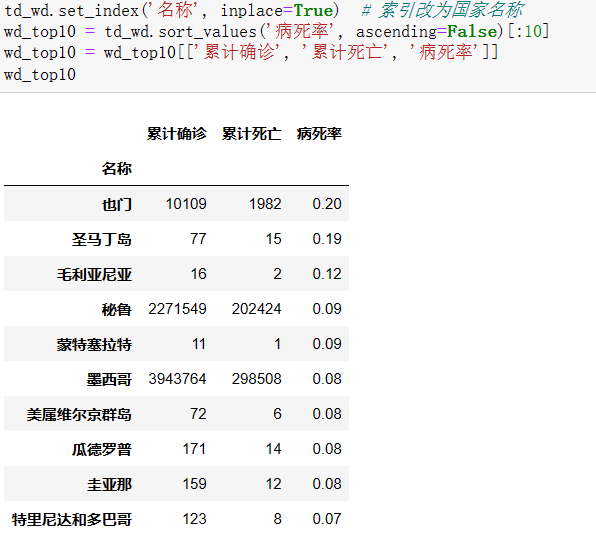
并按累计确诊进行再次排序,取出['累计确诊','累计死亡','病死率']三列前10赋给新的变量:
源码:
1 td_wd.set_index('名称', inplace=True) # 索引改为国家名称 2 wd_top10 = td_wd.sort_values('病死率', ascending=False)[:10] 3 wd_top10 = wd_top10[['累计确诊', '累计死亡', '病死率']] 4 wd_top10
截图展示:
3.数据分析与可视化
(1)从matplotlib可视化库中导入pyplot
(2)指定plt.rcParams['font.sans-serif'] = ['SimHei'] #防止中文乱码
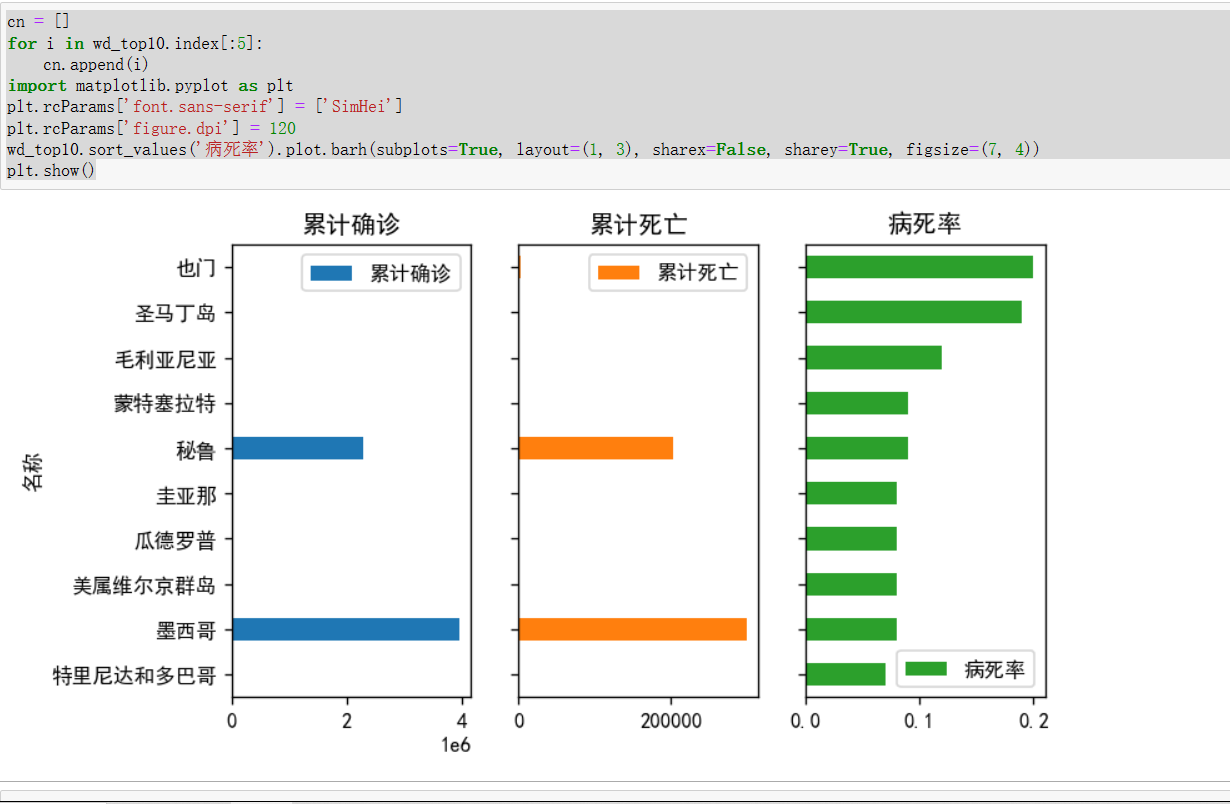
(3)按照病死率对10位数据进行排序,并将['累计确诊','累计死亡','病死率']三列分别作为每一张子图,得到可视化结果源码:
1 cn = [] 2 for i in wd_top10.index[:5]: 3 cn.append(i) 4 import matplotlib.pyplot as plt 5 plt.rcParams['font.sans-serif'] = ['SimHei'] 6 plt.rcParams['figure.dpi'] = 120 7 wd_top10.sort_values('病死率').plot.barh(subplots=True, layout=(1, 3), sharex=False, sharey=True, figsize=(7, 4)) 8 plt.show()
截图展示:
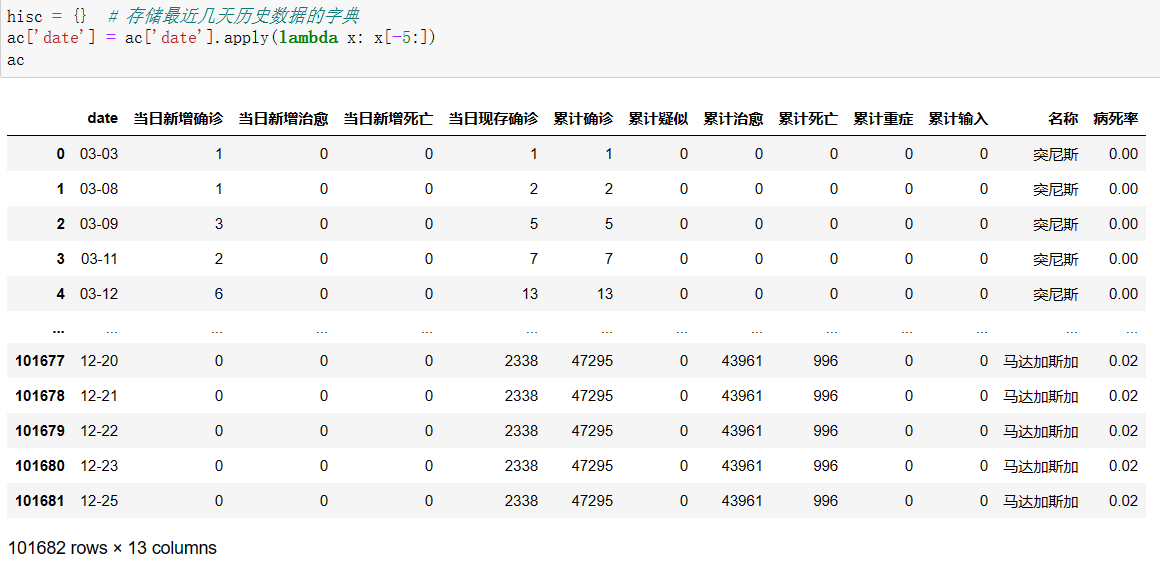
爬取最近几月内历史数据。
经过适当处理后得到如下结果:
源码:
1 hisc = {} 2 ac['date'] = ac['date'].apply(lambda x: x[-5:]) 3 ac
截图展示:
可以看到一个国家对应最近俩月不同的行,这种数据结构不易处理,再将其国家名称作为key值,存储每一天的数据。
源码:
1 for i in ac.index: 2 name = ac['名称'][i] 3 if name not in hisc.keys(): 4 hisc[name] = [] 5 hisc[name].append(list(ac.loc[i])) 6 else: 7 hisc[name].append(list(ac.loc[i])) 8 ds1 = {} 9 q = 0 10 for i in cn: 11 if i not in ds1.keys(): 12 ds1[i] = [] 13 for j in hisc[i]: 14 ds1[i].append(j[0]) 15 else: 16 for j in hisc[i]: 17 ds1[i].append(j[0])
循环读取数据的每一行,判断当前行国家名在此字典key值是否存在,如果存在直接添加数据,不存在则创建值空列表再添加当前行数据。
查看数据以后,发现不同国家之间爬取到的数据是存在缺失值的,我们将不存在的日期去除,只保留当前所有国家存在日期的交集:
源码:
1 d = 0 2 for i in cn: 3 d += 1 4 if d == 1: 5 p_a = ds1[i] 6 continue 7 else: 8 p_b = ds1[i] 9 p_a = set(p_a) & set(p_b) 10 ppd = list(p_a) 11 ds2 = {} 12 ppd.sort()
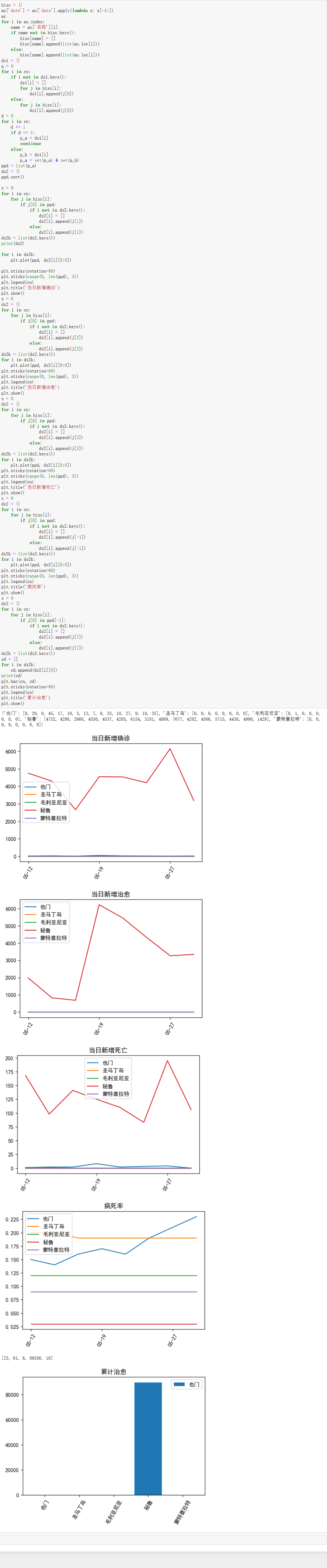
cn为国家名称(由于数据太多,表现效果不是很理想,故只取病死率前5国家作为可视化分析的依据)
由于横坐标轴显示问题,将其文本旋转60°,由于太过密集的原因,再将其设置为间隔显示。
当日新增确诊趋势:
源码:
1 s = 0 2 for i in cn: 3 for j in hisc[i]: 4 if j[0] in ppd: 5 if i not in ds2.keys(): 6 ds2[i] = [] 7 ds2[i].append(j[1]) 8 else: 9 ds2[i].append(j[1]) 10 ds2k = list(ds2.keys()) 11 for i in ds2k: 12 plt.plot(ppd, ds2[i]) 13 plt.xticks(rotation=60) # 横坐标每个值旋转60度 14 plt.xticks(range(0, len(ppd), 3)) 15 plt.legend(cn) 16 plt.title('当日新增确诊') 17 plt.show()
当日新增治愈趋势:
源码:
1 s = 0 2 ds2 = {} 3 for i in cn: 4 for j in hisc[i]: 5 if j[0] in ppd: 6 if i not in ds2.keys(): 7 ds2[i] = [] 8 ds2[i].append(j[2]) 9 else: 10 ds2[i].append(j[2]) 11 ds2k = list(ds2.keys()) 12 for i in ds2k: 13 plt.plot(ppd, ds2[i]) 14 plt.xticks(rotation=60) # 横坐标每个值旋转60度 15 plt.xticks(range(0, len(ppd), 3)) 16 plt.legend(cn) 17 plt.title('当日新增治愈') 18 plt.show()
当日新增死亡趋势:
源码:
1 s = 0 2 ds2 = {} 3 for i in cn: 4 for j in hisc[i]: 5 if j[0] in ppd: 6 if i not in ds2.keys(): 7 ds2[i] = [] 8 ds2[i].append(j[3]) 9 else: 10 ds2[i].append(j[3]) 11 ds2k = list(ds2.keys()) 12 for i in ds2k: 13 plt.plot(ppd, ds2[i]) 14 plt.xticks(rotation=60) # 横坐标每个值旋转60度 15 plt.xticks(range(0, len(ppd), 3)) 16 plt.legend(cn) 17 plt.title('当日新增死亡') 18 plt.show()
病死率趋势:
源码:
1 s = 0 2 ds2 = {} 3 for i in cn: 4 for j in hisc[i]: 5 if j[0] in ppd: 6 if i not in ds2.keys(): 7 ds2[i] = [] 8 ds2[i].append(j[-1]) 9 else: 10 ds2[i].append(j[-1]) 11 ds2k = list(ds2.keys()) 12 for i in ds2k: 13 plt.plot(ppd, ds2[i]) 14 plt.xticks(rotation=60) # 横坐标每个值旋转60度 15 plt.xticks(range(0, len(ppd), 3)) 16 plt.legend(cn) 17 plt.title('病死率') 18 plt.show()
当日累计治愈:
源码:
1 s = 0 2 ds2 = {} 3 for i in cn: 4 for j in hisc[i]: 5 if j[0] in ppd[-1]: 6 if i not in ds2.keys(): 7 ds2[i] = [] 8 ds2[i].append(j[7]) 9 else: 10 ds2[i].append(j[7]) 11 ds2k = list(ds2.keys()) 12 sd = [] 13 for i in ds2k: 14 sd.append(ds2[i][0]) 15 print(sd) 16 plt.bar(cn, sd) 17 plt.xticks(rotation=60) # 横坐标每个值旋转60度 18 plt.legend(cn) 19 plt.title('累计治愈') 20 plt.show()
截图展示如下:
4.将以上各部分的代码汇总,附上完整程序代码
1 import requests # 请求库 2 import json # 用于解析json数据 3 import pandas as pd # 数据分析库 4 import time # 导入时间模块 5 # 找到目标网址,伪装浏览器,请求数据 6 url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=328100359682' 7 8 headers = { 9 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'} 10 11 req = requests.get(url, headers=headers) 12 print(req.status_code) # 响应码 200为成功 13 14 # print(req.text) 15 # ## 使用Json模块对响应内容进行初步解析 16 17 data_json = json.loads(req.text) # 使用json.loads将json字符串转化为字典 18 ata_json.keys() 19 20 data = data_json['data'] 21 data.keys() 22 23 import pprint 24 25 pp = pprint.PrettyPrinter(indent=2) # 2个空格缩进 26 # pp.pprint(data['areaTree']) #查看data数据结构 27 28 # ## 世界各国实时数据爬取 29 30 # ### 获取areaTree数据 31 32 areaTree = data['areaTree'] # 获取各国数据 33 34 pp.pprint(data['areaTree'][0]) # 查看data['areaTree']数据格式 35 36 # ### 封装函数并获取数据 37 38 # 将提取数据的方法进行封装 39 def get_data(data, info_list): 40 info = pd.DataFrame(data)[info_list] # 主要信息 41 42 today_data = pd.DataFrame([i['today'] for i in data]) # 提取today的数据 43 today_data.columns = ['today_' + i for i in today_data.columns] # 更改列名 44 45 total_data = pd.DataFrame([i['total'] for i in data]) # 提取total的数据 46 total_data.columns = ['total_' + i for i in total_data] # 更改列名 47 48 return pd.concat([info, today_data, total_data], axis=1) # 将info.today,total数据进行合并 49 50 today_world = get_data(areaTree, ['id', 'lastUpdateTime', 'name']) # 调用封装的函数获取数据 51 52 today_world.head() 53 54 # ### 封装函数并存储数据 55 56 def save_data(data, name): 57 file_name = name + '_' + time.strftime('%Y_%m_%d', time.localtime(time.time())) + '.csv' 58 data.to_csv(file_name, sep=',', encoding='utf-8-sig') 59 print(file_name + ' 保存成功! ') 60 61 save_data(today_world, 'today_world') # 调用函数保存数据 62 63 country_dict = {num: name for num, name in zip(today_world['id'], today_world['name'])} 64 65 start = time.time() 66 for country_id in country_dict: 67 try: 68 # 按照各国id,访问各国的数据,并获取json数据 69 url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + country_id 70 req2 = requests.get(url, headers=headers) 71 data_json = json.loads(req2.text) 72 73 # 提取各国的数据,然后写入各国的名称 74 country_data = get_data(data_json['data']['list'], 'date') 75 country_data['name'] = country_dict[country_id] 76 77 # 合并数据 78 if country_id == '9577772': 79 alltime_country = country_data 80 else: 81 alltime_country = pd.concat([alltime_country, country_data]) 82 print('-' * 20, country_dict[country_id], '抓取成功', country_data.shape, 83 '以获取数据大小', alltime_country.shape, '累计耗时', round(time.time() - start), '-' * 20) 84 # time.sleep(5) 85 except: 86 print('-' * 20, country_dict[provience_id], '数据抓取失败', '-' * 20) 87 88 save_data(alltime_country, 'alltime_country') 89 90 # ## 数据处理 91 92 # ### 更换数据列名 93 94 td_wd = pd.read_csv('today_world_2021_12_26.csv') 95 ac = pd.read_csv('alltime_country_2021_12_26.csv') 96 97 name_dict = { 98 'id': '编号', 'lastUpdateTime': '更新时间', 'name': '名称', 'today_confirm': '当日新增确诊', 99 'today_suspect': '当日新增疑似', 'today_heal': '当日新增治愈', 'today_dead': '当日新增死亡', 'today_severe': '当日新增重症', 100 'today_storeConfirm': '当日现存确诊', 'today_input': '当日新增输入', 'total_confirm': '累计确诊', 'total_suspect': '累计疑似', 101 'total_heal': '累计治愈', 'total_dead': '累计死亡', 'total_severe': '累计重症', 'total_input': '累计输入' 102 } 103 104 td_wd.rename(columns=name_dict, inplace=True) 105 ac.rename(columns=name_dict, inplace=True) 106 td_wd.head() 107 108 # ### 数据描述 109 110 td_wd = td_wd.drop(columns=['Unnamed: 0']) 111 ac = ac.drop(columns=['Unnamed: 0']) 112 td_wd.describe() 113 114 td_wd['当日现存确诊'] = td_wd['累计确诊'] - td_wd['累计治愈'] - td_wd['累计死亡'] 115 td_wd['病死率'] = (td_wd['累计死亡'] / td_wd['累计确诊']).apply(lambda x: format(x, '.2f')) 116 td_wd['病死率'] = td_wd['病死率'].astype('float') 117 118 ac['当日现存确诊'] = ac['累计确诊'] - ac['累计治愈'] - ac['累计死亡'] 119 ac['病死率'] = (ac['累计死亡'] / ac['累计确诊']).apply(lambda x: format(x, '.2f')) 120 ac['病死率'] = ac['病死率'].astype('float') 121 122 print('统计nan值:') 123 124 td_wd_nan = td_wd.isnull().sum() / len(td_wd) 125 126 td_wd_nan.apply(lambda x: format(x, '.1%')) 127 128 td_wd.sort_values('病死率', ascending=False, inplace=True) 129 td_wd.head() 130 131 td_wd.set_index('名称', inplace=True) # 索引改为国家名称 132 wd_top10 = td_wd.sort_values('病死率', ascending=False)[:10] 133 wd_top10 = wd_top10[['累计确诊', '累计死亡', '病死率']] 134 wd_top10 135 136 cn = [] 137 for i in wd_top10.index[:5]: 138 cn.append(i) 139 140 # ## 数据可视化 141 142 import matplotlib.pyplot as plt 143 144 plt.rcParams['font.sans-serif'] = ['SimHei'] 145 plt.rcParams['figure.dpi'] = 120 146 147 wd_top10.sort_values('病死率').plot.barh(subplots=True, layout=(1, 3), sharex=False, sharey=True, figsize=(7, 4)) 148 plt.show() 149 150 ac.describe() 151 152 print('统计nan值:') 153 154 ac_nan = ac.isnull().sum() / len(ac) 155 156 ac_nan.apply(lambda x: format(x, '.1%')) 157 158 hisc = {} # 存储最近几天历史数据的字典 159 ac['date'] = ac['date'].apply(lambda x: x[-5:]) 160 ac 161 162 for i in ac.index: 163 name = ac['名称'][i] 164 if name not in hisc.keys(): 165 hisc[name] = [] 166 hisc[name].append(list(ac.loc[i])) 167 else: 168 hisc[name].append(list(ac.loc[i])) 169 170 # cn = list(hisc.keys()) 171 172 ds1 = {} 173 174 q = 0 175 for i in cn: 176 if i not in ds1.keys(): 177 ds1[i] = [] 178 for j in hisc[i]: 179 ds1[i].append(j[0]) 180 else: 181 for j in hisc[i]: 182 ds1[i].append(j[0]) 183 184 d = 0 185 for i in cn: 186 d += 1 187 if d == 1: 188 p_a = ds1[i] 189 continue 190 else: 191 p_b = ds1[i] 192 p_a = set(p_a) & set(p_b) 193 194 ppd = list(p_a) 195 ds2 = {} 196 ppd.sort() 197 198 s = 0 199 for i in cn: 200 for j in hisc[i]: 201 if j[0] in ppd: 202 if i not in ds2.keys(): 203 ds2[i] = [] 204 ds2[i].append(j[1]) 205 else: 206 ds2[i].append(j[1]) 207 208 ds2k = list(ds2.keys()) 209 210 for i in ds2k: 211 plt.plot(ppd, ds2[i]) 212 plt.xticks(rotation=60) # 横坐标每个值旋转60度 213 plt.xticks(range(0, len(ppd), 3)) 214 plt.legend(cn) 215 plt.title('当日新增确诊') 216 plt.show() 217 218 s = 0 219 ds2 = {} 220 for i in cn: 221 for j in hisc[i]: 222 if j[0] in ppd: 223 if i not in ds2.keys(): 224 ds2[i] = [] 225 ds2[i].append(j[2]) 226 else: 227 ds2[i].append(j[2]) 228 ds2k = list(ds2.keys()) 229 for i in ds2k: 230 plt.plot(ppd, ds2[i]) 231 plt.xticks(rotation=60) # 横坐标每个值旋转60度 232 plt.xticks(range(0, len(ppd), 3)) 233 plt.legend(cn) 234 plt.title('当日新增治愈') 235 plt.show() 236 237 s = 0 238 ds2 = {} 239 for i in cn: 240 for j in hisc[i]: 241 if j[0] in ppd: 242 if i not in ds2.keys(): 243 ds2[i] = [] 244 ds2[i].append(j[3]) 245 else: 246 ds2[i].append(j[3]) 247 ds2k = list(ds2.keys()) 248 for i in ds2k: 249 plt.plot(ppd, ds2[i]) 250 plt.xticks(rotation=60) # 横坐标每个值旋转60度 251 plt.xticks(range(0, len(ppd), 3)) 252 plt.legend(cn) 253 plt.title('当日新增死亡') 254 plt.show() 255 256 s = 0 257 ds2 = {} 258 for i in cn: 259 for j in hisc[i]: 260 if j[0] in ppd: 261 if i not in ds2.keys(): 262 ds2[i] = [] 263 ds2[i].append(j[-1]) 264 else: 265 ds2[i].append(j[-1]) 266 ds2k = list(ds2.keys()) 267 for i in ds2k: 268 plt.plot(ppd, ds2[i]) 269 plt.xticks(rotation=60) # 横坐标每个值旋转60度 270 plt.xticks(range(0, len(ppd), 3)) 271 plt.legend(cn) 272 plt.title('病死率') 273 plt.show() 274 275 s = 0 276 ds2 = {} 277 for i in cn: 278 for j in hisc[i]: 279 if j[0] in ppd[-1]: 280 if i not in ds2.keys(): 281 ds2[i] = [] 282 ds2[i].append(j[7]) 283 else: 284 ds2[i].append(j[7]) 285 ds2k = list(ds2.keys()) 286 sd = [] 287 for i in ds2k: 288 sd.append(ds2[i][0]) 289 print(sd) 290 plt.bar(cn, sd) 291 plt.xticks(rotation=60) # 横坐标每个值旋转60度 292 plt.legend(cn) 293 plt.title('累计治愈') 294 plt.show()
(五)、总结
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
从以上数据可以看到也门人口基数少,但却是病死率最高的国家。秘鲁的新增确诊和新增治愈波动都比较大,有可能是因为人口基数的原因,同时可能是由于政策上的原因导致疫情二次扩散,不过及时解决了问题,同时也说明了秘鲁治疗肺炎的能力也不差,好在病死率不高。
圣马丁岛的病死率也不低。从累计治愈人数来看 秘鲁>圣马丁岛>也门>蒙特塞拉特>毛利亚尼亚。总的来说,对主题数据的分析与可视化,还是达到了预期目标。
(89556>61>23>10>6)
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
通过本次Python爬虫设计,掌握了许多编程技巧。在不断进步的过程中,收获了许多新的知识,实用性也非常好,对于以后不懂编程很难混有极大的科普价值,当然也有一定的实用性!
数据处理过程中,DataFrame虽然好用但不是非常灵活,配合字典和列表构成新的数据格式,可以绘制出想要的可视化效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号