【Hadoop代码笔记】Hadoop作业提交之TaskTracker获取Task
一、概要描述
在上上一篇博文和上一篇博文中分别描述了jobTracker和其服务(功能)模块初始化完成后,接收JobClient提交的作业,并进行初始化。本文着重描述,JobTracker如何选择作业的Task分发到TaskTracker。本文只是描述一个TaskTracker如何从JobTracker获取Task任务。Task任务在TaskTracker如何执行将在后面博文中描述。
二、 流程描述
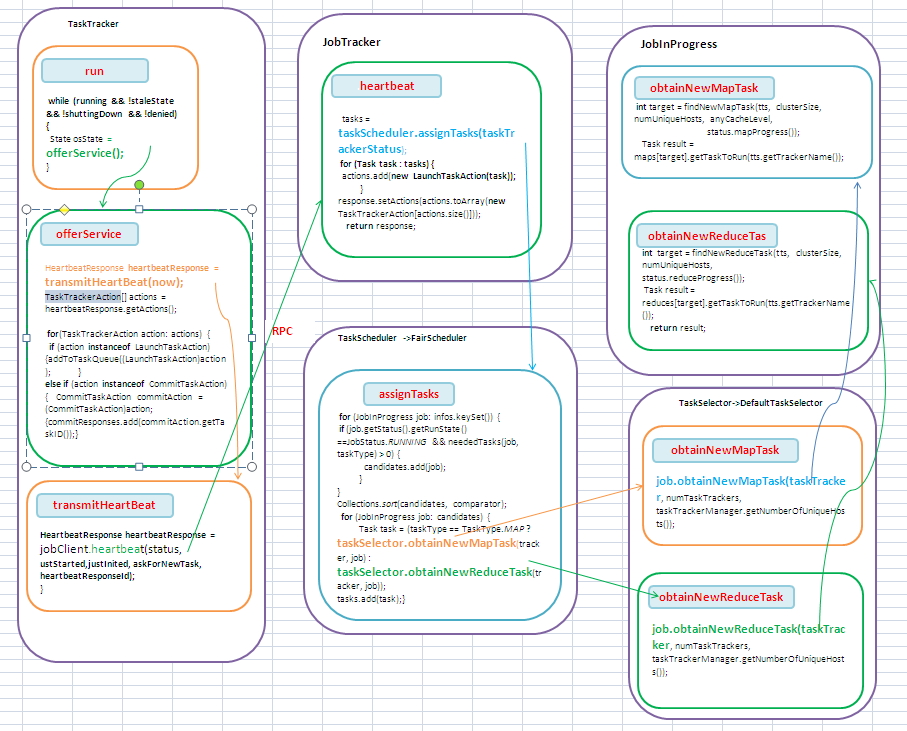
1. TaskTracker在run中调用offerService()方法一直死循环的去连接Jobtracker,先Jobtracker发送心跳,发送自身状态,并从Jobtracker获取任务指令来执行。
2. 在JobTracker的heartbeat方法中,对于来自每一个TaskTracker的心跳请求,根据一定的作业调度策略调用assignTasks方法选择一定Task
3.Scheduler调用对应的LoadManager的canAssignMap方法和canAssignReduce方法以决定是否可以给tasktracker分配任务。默认的是CapBasedLoad,全局平均分配。即根据全局的任务槽数,全局的map任务数的比值得到一个load系数,该系数乘以待分配任务的tasktracker的最大map任务数,即是该tasktracker能分配得到的任务数。如果太tracker当前运行的任务数小于可运行的任务数,则任务可以分配新作业给他。(图中缺失了LoadManager的表达,也画不下了,就不加了。在代码详细分析中有)
3. Scheduler的调用TaskSelector的obtainNewMapTask或者obtainNewReduceTask选择Task。
4. 在DefaultTaskSelector中选择Task的方法其实只是封装了JobInProgress的对应方法。
5. JobTracker根据得到的Task构造TaskTrackerAction设置到到HeartbeatResponse返回给TaskTracker。
6. TaskTracker中将来自JobTracker的任务加入到TaskQueue中等待执行。
三、代码详细
1. TaskTracker的入口函数main
JobConf conf=new JobConf(); // enable the server to track time spent waiting on locks ReflectionUtils.setContentionTracing (conf.getBoolean("tasktracker.contention.tracking", false)); new TaskTracker(conf).run();
2. TaskTracker的构造函数
maxCurrentMapTasks = conf.getInt( "mapred.tasktracker.map.tasks.maximum", 2); maxCurrentReduceTasks = conf.getInt( "mapred.tasktracker.reduce.tasks.maximum", 2); this.jobTrackAddr = JobTracker.getAddress(conf); //启动httpserver 展示tasktracker状态。 this.server = new HttpServer("task", httpBindAddress, httpPort, httpPort == 0, conf); server.start(); this.httpPort = server.getPort(); //初始化方法 initialize();
3. TaskTracker的initialize方法,完成TaskTracker的初始化工作。
主要流程
1) 检查可以创建本地文件夹
2) 清理或者初始化需要用到的实例集合变量
3) 初始化RPC服务器,接受task的请求。
4) 清除临时文件
5) jobtracker的代理,负责处理和jobtracker的交互,通过RPC方式。
6) 一个线程,获取map完成事件。
7) 初始化内存管理
8) 分别启动map和reduce的tasklauncher
synchronized void initialize() { //检查可以创建本地文件夹 checkLocalDirs(this.fConf.getLocalDirs()); fConf.deleteLocalFiles(SUBDIR); //清理或者初始化需要用到的实例集合变量 this.tasks.clear(); this.runningTasks = new LinkedHashMap<TaskAttemptID, TaskInProgress>(); this.runningJobs = new TreeMap<JobID, RunningJob>(); this.jvmManager = new JvmManager(this); //初始化RPC服务器,接受task的请求。 this.taskReportServer = RPC.getServer(this, bindAddress, tmpPort, 2 * max, false, this.fConf); this.taskReportServer.start(); // 清除临时文件 DistributedCache.purgeCache(this.fConf); cleanupStorage(); //jobtracker的代理,负责处理和jobtracker的交互,通过RPC方式。 this.jobClient = (InterTrackerProtocol) RPC.waitForProxy(InterTrackerProtocol.class, InterTrackerProtocol.versionID, jobTrackAddr, this.fConf); //一个线程,获取map完成事件。 this.mapEventsFetcher = new MapEventsFetcherThread(); mapEventsFetcher.setDaemon(true); mapEventsFetcher.setName( "Map-events fetcher for all reduce tasks " + "on " + taskTrackerName); mapEventsFetcher.start(); //初始化内存管理 initializeMemoryManagement(); //分别启动map和reduce的tasklauncher mapLauncher = new TaskLauncher(maxCurrentMapTasks); reduceLauncher = new TaskLauncher(maxCurrentReduceTasks); mapLauncher.start(); reduceLauncher.start(); }
4. TaskTracker 的run方法,在其中一直尝试执行offerService方法
public void run() { while (running && !staleState && !shuttingDown && !denied) { State osState = offerService(); } }
5. TaskTracker 的offerService方法
1) 通过RPC调用获得Jobtracker的系统目录。
2) 发送心跳并且获取Jobtracker的应答
3) 从JobTrackeer的应答中获取指令
4) 不同的指令类型执行不同的动作
5) 对于要launch的task加入到taskQueue中去
6) 对于清理动作,加入待清理的task集合,会有线程自动清理
7) 杀死那些过久未反馈进度的task
8) 当磁盘空间不够时,杀死某些task以腾出空间
State offerService() { //通过RPC调用获得Jobtracker的系统目录。 String dir = jobClient.getSystemDir(); if (dir == null) { throw new IOException("Failed to get system directory"); } systemDirectory = new Path(dir); systemFS = systemDirectory.getFileSystem(fConf); } // 发送心跳并且获取Jobtracker的应答 HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); //从JobTrackeer的应答中获取指令 TaskTrackerAction[] actions = heartbeatResponse.getActions(); //不同的指令类型执行不同的动作 if (actions != null){ for(TaskTrackerAction action: actions) { //对于要launch的task加入到taskQueue中去 if (action instanceof LaunchTaskAction) {addToTaskQueue((LaunchTaskAction)action); } else if (action instanceof CommitTaskAction) { CommitTaskAction commitAction = (CommitTaskAction)action; if (!commitResponses.contains(commitAction.getTaskID())) {commitResponses.add(commitAction.getTaskID());} //加入待清理的task集合,会有线程自动清理 } else {tasksToCleanup.put(action); } } } //杀死那些过久未反馈进度的task markUnresponsiveTasks(); //当磁盘空间不够时,杀死某些task以腾出空间 killOverflowingTasks(); }
6. TaskTracker的 transmitHeartBeat方法,定时向JobTracker发心跳。其实是通过RPC的方式向调用Jobtracker的heartbeat方法。
private HeartbeatResponse transmitHeartBeat(long now) { boolean askForNewTask; long localMinSpaceStart; synchronized (this) { //判断该Tasktracker是否可以接受新的task,依赖于 askForNewTask = (status.countMapTasks() < maxCurrentMapTasks || status.countReduceTasks() < maxCurrentReduceTasks) && acceptNewTasks; localMinSpaceStart = minSpaceStart; } if (askForNewTask) { checkLocalDirs(fConf.getLocalDirs()); //判断本地空间是否足够,以决定是否接受新的task askForNewTask = enoughFreeSpace(localMinSpaceStart); long freeDiskSpace = getFreeSpace(); long totVmem = getTotalVirtualMemoryOnTT(); long totPmem = getTotalPhysicalMemoryOnTT(); status.getResourceStatus().setAvailableSpace(freeDiskSpace); status.getResourceStatus().setTotalVirtualMemory(totVmem); status.getResourceStatus().setTotalPhysicalMemory(totPmem); status.getResourceStatus().setMapSlotMemorySizeOnTT(mapSlotMemorySizeOnTT); status.getResourceStatus().setReduceSlotMemorySizeOnTT(reduceSlotSizeMemoryOnTT); } //通过jobclient通过RPC的方式向调用Jobtracker的heartbeat方法。 HeartbeatResponse heartbeatResponse = jobClient.heartbeat(status, ustStarted,justInited, askForNewTask, heartbeatResponseId); }
6. JobTracker的 heartbeat方法。Jobtracker 接受并处理 tasktracker上报的状态,在返回的应答信息中指示tasktracker完成启停job或启动某个task的动作。
|
动作类型类 |
描述 |
|
CommitTaskAction |
指示Task保存输出,即提交 |
|
KillJobAction |
杀死属于这个Job的任何一个Task |
|
KillTaskAction |
杀死指定的Task |
|
LaunchTaskAction |
开启某个task |
|
ReinitTrackerAction |
重新初始化taskTracker |
主要流程如下:
1) acceptTaskTracker(status)方法通过查询inHostsList(status) && !inExcludedHostsList确认Tasktracker是否在JobTracker的允许列表中。
2) 当得知TaskTracker重启的标记,从jobtracker的潜在故障名单中移除该tasktracker
3) 如果initialContact为否表示这次心跳请求不是该taskTracker第一次连接jobtracker,但是如果在jobtracker的trackerToHeartbeatResponseMap记录中没有之前的响应记录,则说明发生了笔记严重的错误。发送指令给tasktracker要求其重新初始化。
4) 如果这是有问题的tasktracker重新接回来的第一个心跳,则通知recoveryManager recoveryManager从的recoveredTrackers列表中移除该tracker以表示该tracker又正常的接回来了。
5) 如果initialContact != true 并且 revHeartbeatResponse != null表示上一个心跳应答存在,但是tasktracker表示第一次请求,则说上一个initialContact请求的应答丢失了,未传送到tasktracker。则只是简单的把原来的应答重发一下即可。
6) 构造应答的Id,是递加的。
7) 处理心跳,其实就是在jobTracker端更新该tasktracker的状态
8) 检查tasktracker可以运行新的task
9) 调用JobTracker配置的taskSceduler来调度task给对应的TaskTracker。从submit到JobTracker的Job列表中选择每个job的每个Task,适合交给该TaskTracker调度的Task
10) 把分配的Task加入到expireLaunchingTasks,监视并处理其是否超时。
11) 根据调度器发获得要启动的task构造LaunchTaskAction,通知taskTracker启动这些task。
12) 把属于该tasktracker的,job已经结束的task加入到killTasksList,发送到tasktracker杀死。即结束那些在tasktracker上已经结束了的作业的task,不管作业是完成还失败。
13) 判定哪些作业需要清理的,构造Action加入到action列表中。trackerToJobsToCleanup是一个结合,当job gc的时候,调用 finalizeJob进而调用 addJobForCleanup 把作业加入到trackerToJobsToCleanup中
14) 判定那些task可以提交输出,构造action加入到action列表。
15) 计算下一次心跳的间隔,设置到应答消息中。
16) 把上面这些Action设置到response中返回。
17) 把本次应答保存到trackerToHeartbeatResponseMap中
1 public synchronized HeartbeatResponse heartbeat(TaskTrackerStatus status, 2 boolean restarted, 3 boolean initialContact, 4 boolean acceptNewTasks, 5 short responseId) 6 throws IOException { 7 8 //1) acceptTaskTracker(status)方法通过查询inHostsList(status) && !inExcludedHostsList确认Tasktracker是否在JobTracker的允许列表中。 9 if (!acceptTaskTracker(status)) { 10 throw new DisallowedTaskTrackerException(status); 11 } 12 String trackerName = status.getTrackerName(); 13 long now = System.currentTimeMillis(); 14 boolean isBlacklisted = false; 15 if (restarted) { 16 //2)当得知TaskTracker重启的标记,从jobtracker的潜在故障名单中移除该tasktracker 17 faultyTrackers.markTrackerHealthy(status.getHost()); 18 } else { 19 isBlacklisted = 20 faultyTrackers.shouldAssignTasksToTracker(status.getHost(), now); 21 } 22 23 HeartbeatResponse prevHeartbeatResponse =trackerToHeartbeatResponseMap.get(trackerName); 24 boolean addRestartInfo = false; 25 26 if (initialContact != true) { 27 //3)如果initialContact为否表示这次心跳请求不是该taskTracker第一次连接jobtracker,但是如果在jobtracker的trackerToHeartbeatResponseMap记录中没有之前的响应记录,则说明发生了笔记严重的错误。发送指令给tasktracker要求其重新初始化。 28 if (prevHeartbeatResponse == null) { 29 // This is the first heartbeat from the old tracker to the newly 30 // started JobTracker 31 //4)如果这是有问题的tasktracker重新接回来的第一个心跳,则通知recoveryManager 32 if (hasRestarted()) { 33 addRestartInfo = true; 34 // recoveryManager从的recoveredTrackers列表中移除该tracker以表示该tracker又正常的接回来了。 35 recoveryManager.unMarkTracker(trackerName); 36 } else { 37 //发送指令让tasktracker重新初始化。 38 return new HeartbeatResponse(responseId, 39 new TaskTrackerAction[] {new ReinitTrackerAction()}); 40 } 41 42 } else { 43 44 //如果initialContact != true 并且 revHeartbeatResponse != null表示上一个心跳应答存在,但是tasktracker表示第一次请求,则说上一个initialContact请求的应答丢失了,未传送到tasktracker。则只是简单的把原来的应答重发一下即可。 45 if (prevHeartbeatResponse.getResponseId() != responseId) { 46 LOG.info("Ignoring 'duplicate' heartbeat from '" + 47 trackerName + "'; resending the previous 'lost' response"); 48 return prevHeartbeatResponse; 49 } 50 } 51 } 52 53 // 应答的Id是递加的。 54 short newResponseId = (short)(responseId + 1); 55 status.setLastSeen(now); 56 //处理心跳,其实就是在jobTracker端更新该tasktracker的状态 57 if (!processHeartbeat(status, initialContact)) { 58 if (prevHeartbeatResponse != null) { 59 trackerToHeartbeatResponseMap.remove(trackerName); 60 } 61 return new HeartbeatResponse(newResponseId, 62 new TaskTrackerAction[] {new ReinitTrackerAction()}); 63 } 64 65 // 检查tasktracker可以运行新的task 66 if (recoveryManager.shouldSchedule() && acceptNewTasks && !isBlacklisted) { 67 TaskTrackerStatus taskTrackerStatus = getTaskTracker(trackerName); 68 if (taskTrackerStatus == null) { 69 } else { 70 List<Task> tasks = getSetupAndCleanupTasks(taskTrackerStatus); 71 if (tasks == null ) { 72 //2调用JobTracker配置的taskSceduler来调度task给对应的TaskTracker。从submit到JobTracker的Job列表中选择每个job的每个Task,适合交给该TaskTracker调度的Task 73 74 tasks = taskScheduler.assignTasks(taskTrackerStatus);} 75 if (tasks != null) { 76 //把分配的Task加入到expireLaunchingTasks,监视并处理其是否超时。 77 for (Task task : tasks) { 78 Object expireLaunchingTasks; 79 expireLaunchingTasks.addNewTask(task.getTaskID()); 80 actions.add(new LaunchTaskAction(task)); 81 } 82 } 83 } 84 } 85 86 //把属于该tasktracker的,job已经结束的task加入到killTasksList,发送到tasktracker杀死。即结束那些在tasktracker上已经结束了的作业的task,不管作业是完成还失败。 87 List<TaskTrackerAction> killTasksList = getTasksToKill(trackerName); 88 if (killTasksList != null) { 89 actions.addAll(killTasksList); 90 } 91 92 //判定哪些作业需要清理。finalizeJob-> addJobForCleanup 当gc一个job的时候,会调用以上方法把其加入到trackerToJobsToCleanup中 93 List<TaskTrackerAction> killJobsList = getJobsForCleanup(trackerName); 94 if (killJobsList != null) { 95 actions.addAll(killJobsList); 96 97 //判定那些task可以提交输出。 98 List<TaskTrackerAction> commitTasksList = getTasksToSave(status); 99 if (commitTasksList != null) { 100 actions.addAll(commitTasksList); 101 } 102 103 //calculate next heartbeat interval and put in heartbeat response 104 //计算下一次心跳的间隔,设置到应答消息中。 105 int nextInterval = getNextHeartbeatInterval(); 106 response.setHeartbeatInterval(nextInterval); 107 108 //把上面这些Action设置到response中返回。 109 response.setActions(actions.toArray(new TaskTrackerAction[actions.size()])); 110 //把本次应答保存到trackerToHeartbeatResponseMap中 111 trackerToHeartbeatResponseMap.put(trackerName, response); 112 return response; 113 114 }
7.FairScheduler的assignTasks方法。JobTracker就是调用该方法来实现作业的分配的。
主要流程如下:
1) 分别计算可运行的maptask和reducetask总数
2) ClusterStatus 维护了当前Map/Reduce作业框架的总体状况。根据ClusterStatus计算得到获得map task的槽数,reduce task的槽数。
3) 调用LoadManager方法决定是否可以为该tasktracker分配任务(默认CapBasedLoadManager方法根据全局的任务槽数,全局的map任务数的比值得到一个load系数,该系数乘以待分配任务的tasktracker的最大map任务数,即是该tasktracker能分配得到的任务数。如果太tracker当前运行的任务数小于可运行的任务数,则任务可以分配新作业给他)
4) 从job列表中找出那些job需要运行map或reduce任务,加到List<JobInProgress> candidates集合中
5) 对candidates集合中的job排序,对每个job调用taskSelector的obtainNewMapTask或者obtainNewReduceTask方法获取要执行的task。把所以的task放到task集合中返回。从而实现了作业Job的任务Task分配。
6) 并对candidates集合中的每个job,更新Jobinfo信息,即其正在运行的task数,需要运行的task数,以便其后续调度用。
1 public synchronized List<Task> assignTasks(TaskTrackerStatus tracker) 2 throws IOException { 3 if (!initialized) // Don't try to assign tasks if we haven't yet started up 4 return null; 5 6 oolMgr.reloadAllocsIfNecessary(); 7 8 // 分别计算可运行的maptask和reducetask总数 9 int runnableMaps = 0; 10 int runnableReduces = 0; 11 for (JobInProgress job: infos.keySet()) { 12 runnableMaps += runnableTasks(job, TaskType.MAP); 13 runnableReduces += runnableTasks(job, TaskType.REDUCE); 14 } 15 16 // ClusterStatus 维护了当前Map/Reduce作业框架的总体状况。 17 ClusterStatus clusterStatus = taskTrackerManager.getClusterStatus(); 18 //计算得到获得map task的槽数,reduce task的槽数。 19 int totalMapSlots = getTotalSlots(TaskType.MAP, clusterStatus); 20 int totalReduceSlots = getTotalSlots(TaskType.REDUCE, clusterStatus); 21 22 //从job列表中找出那些job需要运行map或reduce任务,加到List<JobInProgress> candidates集合中 23 ArrayList<Task> tasks = new ArrayList<Task>(); 24 TaskType[] types = new TaskType[] {TaskType.MAP, TaskType.REDUCE}; 25 for (TaskType taskType: types) { 26 boolean canAssign = (taskType == TaskType.MAP) ? 27 //CapBasedLoadManager方法根据全局的任务槽数,全局的map任务数的比值得到一个load系数,该系数乘以待分配任务的tasktracker的最大map任务数,即是该tasktracker能分配得到的任务数。如果太tracker当前运行的任务数小于可运行的任务数,则任务可以分配新作业给他 28 loadMgr.canAssignMap(tracker, runnableMaps, totalMapSlots) : 29 loadMgr.canAssignReduce(tracker, runnableReduces, totalReduceSlots); 30 if (canAssign) { 31 List<JobInProgress> candidates = new ArrayList<JobInProgress>(); 32 for (JobInProgress job: infos.keySet()) { 33 if (job.getStatus().getRunState() == JobStatus.RUNNING && 34 neededTasks(job, taskType) > 0) { 35 candidates.add(job); 36 } 37 } 38 //对candidates集合中的job排序,对每个job调用taskSelector的obtainNewMapTask或者obtainNewReduceTask方法获取要执行的task。把所以的task放到task集合中返回。 39 // Sort jobs by deficit (for Fair Sharing) or submit time (for FIFO) 40 Comparator<JobInProgress> comparator = useFifo ? 41 new FifoJobComparator() : new DeficitComparator(taskType); 42 Collections.sort(candidates, comparator); 43 for (JobInProgress job: candidates) { 44 Task task = (taskType == TaskType.MAP ? 45 taskSelector.obtainNewMapTask(tracker, job) : 46 taskSelector.obtainNewReduceTask(tracker, job)); 47 if (task != null) { 48 //并对candidates集合中的每个job,更新Jobinfo信息,即其正在运行的task数,需要运行的task数。 49 JobInfo info = infos.get(job); 50 if (taskType == TaskType.MAP) { 51 info.runningMaps++; 52 info.neededMaps--; 53 } else { 54 info.runningReduces++; 55 info.neededReduces--; 56 } 57 tasks.add(task); 58 if (!assignMultiple) 59 return tasks; 60 break; 61 } 62 } 63 } 64 } 65 66 // If no tasks were found, return null 67 return tasks.isEmpty() ? null : tasks; 68 }
8.CapBasedLoadManager的canAssignMap方法和canAssignReduce方法。一种简单的算法在FairScheduler中用来决定是否可以给某个tasktracker分配maptask或者reducetask。总体思路是对于某种类型的task,map或者reduce,考虑jobtracker管理的mapreduce集群全部的任务数,和全部的任务槽数,和该tasktracker上面当前的任务数,以决定是否给他分配任务。如对于maptask,根据全局的任务槽数,全局的map任务数的比值得到一个load系数,该系数乘以待分配任务的tasktracker的最大map任务数,即是该tasktracker能分配得到的任务数。如果太tracker当前运行的任务数小于可运行的任务数,则任务可以分配新作业给他。reducetask同理。即尽量做到全局平均。
int getCap(int totalRunnableTasks, int localMaxTasks, int totalSlots) { double load = ((double)totalRunnableTasks) / totalSlots; return (int) Math.ceil(localMaxTasks * Math.min(1.0, load)); } @Override public boolean canAssignMap(TaskTrackerStatus tracker, int totalRunnableMaps, int totalMapSlots) { return tracker.countMapTasks() < getCap(totalRunnableMaps, tracker.getMaxMapTasks(), totalMapSlots); } @Override public boolean canAssignReduce(TaskTrackerStatus tracker, int totalRunnableReduces, int totalReduceSlots) { return tracker.countReduceTasks() < getCap(totalRunnableReduces, tracker.getMaxReduceTasks(), totalReduceSlots); }
9. DefaultTaskSelector继承自TaskSelector,其两个方法其实只是对jobInprogress得封装,没有做什么特别的事情。
@Override public Task obtainNewMapTask(TaskTrackerStatus taskTracker, JobInProgress job) throws IOException { ClusterStatus clusterStatus = taskTrackerManager.getClusterStatus(); int numTaskTrackers = clusterStatus.getTaskTrackers(); return job.obtainNewMapTask(taskTracker, numTaskTrackers, taskTrackerManager.getNumberOfUniqueHosts()); } @Override public Task obtainNewReduceTask(TaskTrackerStatus taskTracker, JobInProgress job) throws IOException { ClusterStatus clusterStatus = taskTrackerManager.getClusterStatus(); int numTaskTrackers = clusterStatus.getTaskTrackers(); return job.obtainNewReduceTask(taskTracker, numTaskTrackers, taskTrackerManager.getNumberOfUniqueHosts()); }
10. JobInProgress的obtainNewMapTask方法。其实主要逻辑是在findNewMapTask方法中实现。
public synchronized Task obtainNewMapTask(TaskTrackerStatus tts, int clusterSize, int numUniqueHosts ) throws IOException { int target = findNewMapTask(tts, clusterSize, numUniqueHosts, anyCacheLevel, status.mapProgress()); Task result = maps[target].getTaskToRun(tts.getTrackerName()); if (result != null) { addRunningTaskToTIP(maps[target], result.getTaskID(), tts, true); } return result; }
11 JobInProgress的findNewMapTask方法。
根据待派发Task的TaskTracker根据集群中的TaskTracker数量(clusterSize),运行TraskTracker的服务器数(numUniqueHosts),该Job中map task的平均进度(avgProgress),可以调度map的最大水平(距离其实),选择一个task执行。考虑到map的本地化。
private synchronized int findNewMapTask(final TaskTrackerStatus tts, final int clusterSize, final int numUniqueHosts, final int maxCacheLevel, final double avgProgress) { String taskTracker = tts.getTrackerName(); TaskInProgress tip = null; //1)更新TaskTracker总数。 this.clusterSize = clusterSize; //2)如果这个TraskTracker上面之前有很多map都会失败,则返回标记,不分配给他。 if (!shouldRunOnTaskTracker(taskTracker)) { return -1; //3) 检查该TaskTracker有足够的资源运行。估算output的方法有点意思,根据(job现有的map数+当前job的map数)*已完成map数*2*已完成的map的输出size/已经完成map的输入size,即根据完成估算总数。 long outSize = resourceEstimator.getEstimatedMapOutputSize(); long availSpace = tts.getResourceStatus().getAvailableSpace(); if(availSpace < outSize) { LOG.warn("No room for map task. Node " + tts.getHost() + " has " + availSpace + " bytes free; but we expect map to take " + outSize); return -1; } // For scheduling a map task, we have two caches and a list (optional) // I) one for non-running task // II) one for running task (this is for handling speculation) // III) a list of TIPs that have empty locations (e.g., dummy splits), // the list is empty if all TIPs have associated locations // First a look up is done on the non-running cache and on a miss, a look // up is done on the running cache. The order for lookup within the cache: // 1. from local node to root [bottom up] // 2. breadth wise for all the parent nodes at max level // We fall to linear scan of the list (III above) if we have misses in the // above caches //4)获得jobTracker所在的Node Node node = jobtracker.getNode(tts.getHost()); // I) Non-running TIP : //5) 从未运行的作业集合中选择一个nonRunningMapCache 加入到运行集合runningMapCache中。加入时根据待添加的Task的split的位置信息,在runningMapCache中保存Node和Task集合的对应关系。 // 1. check from local node to the root [bottom up cache lookup] // i.e if the cache is available and the host has been resolved // (node!=null) if (node != null) { Node key = node; int level = 0; // maxCacheLevel might be greater than this.maxLevel if findNewMapTask is // called to schedule any task (local, rack-local, off-switch or speculative) // tasks or it might be NON_LOCAL_CACHE_LEVEL (i.e. -1) if findNewMapTask is // (i.e. -1) if findNewMapTask is to only schedule off-switch/speculative // tasks //从taskTracker本地开始由近至远查找要加入的Task 到runningMapCache中。 int maxLevelToSchedule = Math.min(maxCacheLevel, maxLevel); for (level = 0;level < maxLevelToSchedule; ++level) { List <TaskInProgress> cacheForLevel = nonRunningMapCache.get(key); if (cacheForLevel != null) { tip = findTaskFromList(cacheForLevel, tts, numUniqueHosts,level == 0); if (tip != null) { // 把该map任务加入到runningMapCache scheduleMap(tip); return tip.getIdWithinJob(); } } key = key.getParent(); } // Check if we need to only schedule a local task (node-local/rack-local) if (level == maxCacheLevel) { return -1; } } //2. Search breadth-wise across parents at max level for non-running // TIP if // - cache exists and there is a cache miss // - node information for the tracker is missing (tracker's topology // info not obtained yet) // collection of node at max level in the cache structure Collection<Node> nodesAtMaxLevel = jobtracker.getNodesAtMaxLevel(); // get the node parent at max level Node nodeParentAtMaxLevel = (node == null) ? null : JobTracker.getParentNode(node, maxLevel - 1); for (Node parent : nodesAtMaxLevel) { // skip the parent that has already been scanned if (parent == nodeParentAtMaxLevel) { continue; } List<TaskInProgress> cache = nonRunningMapCache.get(parent); if (cache != null) { tip = findTaskFromList(cache, tts, numUniqueHosts, false); if (tip != null) { // Add to the running cache scheduleMap(tip); // remove the cache if empty if (cache.size() == 0) { nonRunningMapCache.remove(parent); } LOG.info("Choosing a non-local task " + tip.getTIPId()); return tip.getIdWithinJob(); } } } //搜索非本地Map tip = findTaskFromList(nonLocalMaps, tts, numUniqueHosts, false); if (tip != null) { // Add to the running list scheduleMap(tip); LOG.info("Choosing a non-local task " + tip.getTIPId()); return tip.getIdWithinJob(); } // // II) Running TIP : // if (hasSpeculativeMaps) { long currentTime = System.currentTimeMillis(); // 1. Check bottom up for speculative tasks from the running cache if (node != null) { Node key = node; for (int level = 0; level < maxLevel; ++level) { Set<TaskInProgress> cacheForLevel = runningMapCache.get(key); if (cacheForLevel != null) { tip = findSpeculativeTask(cacheForLevel, tts, avgProgress, currentTime, level == 0); if (tip != null) { if (cacheForLevel.size() == 0) { runningMapCache.remove(key); } return tip.getIdWithinJob(); } } key = key.getParent(); } } // 2. Check breadth-wise for speculative tasks for (Node parent : nodesAtMaxLevel) { // ignore the parent which is already scanned if (parent == nodeParentAtMaxLevel) { continue; } Set<TaskInProgress> cache = runningMapCache.get(parent); if (cache != null) { tip = findSpeculativeTask(cache, tts, avgProgress, currentTime, false); if (tip != null) { // remove empty cache entries if (cache.size() == 0) { runningMapCache.remove(parent); } LOG.info("Choosing a non-local task " + tip.getTIPId() + " for speculation"); return tip.getIdWithinJob(); } } } // 3. Check non-local tips for speculation tip = findSpeculativeTask(nonLocalRunningMaps, tts, avgProgress, currentTime, false); if (tip != null) { LOG.info("Choosing a non-local task " + tip.getTIPId() + " for speculation"); return tip.getIdWithinJob(); } } return -1; }
12 JobInProgress的obtainNewReduceTask方法返回一个ReduceTask,实际调用的是findNewReduceTask方法。
public synchronized Task obtainNewReduceTask(TaskTrackerStatus tts, int clusterSize, int numUniqueHosts ) throws IOException { //判定有足够的map已经完成。, if (!scheduleReduces()) { return null; } int target = findNewReduceTask(tts, clusterSize, numUniqueHosts, status.reduceProgress()); Task result = reduces[target].getTaskToRun(tts.getTrackerName()); if (result != null) { addRunningTaskToTIP(reduces[target], result.getTaskID(), tts, true); } return result; }
13 JobInProgress的findNewReduceTask方法,为指定的TaskTracker选择Reduce task。不用考虑本地化。
private synchronized int findNewReduceTask(TaskTrackerStatus tts, int clusterSize, int numUniqueHosts, double avgProgress) { String taskTracker = tts.getTrackerName(); TaskInProgress tip = null; // Update the last-known clusterSize this.clusterSize = clusterSize; // 该taskTracker可用性符合要求 if (!shouldRunOnTaskTracker(taskTracker)) { return -1; } //估算Reduce的输入,根据map的总输出来和reduce的个数来计算。 long outSize = resourceEstimator.getEstimatedReduceInputSize(); long availSpace = tts.getResourceStatus().getAvailableSpace(); if(availSpace < outSize) { LOG.warn("No room for reduce task. Node " + taskTracker + " has " + availSpace + " bytes free; but we expect reduce input to take " + outSize); return -1; //see if a different TIP might work better. } // 1. check for a never-executed reduce tip // reducers don't have a cache and so pass -1 to explicitly call that out tip = findTaskFromList(nonRunningReduces, tts, numUniqueHosts, false); if (tip != null) { scheduleReduce(tip); return tip.getIdWithinJob(); } // 2. check for a reduce tip to be speculated if (hasSpeculativeReduces) { tip = findSpeculativeTask(runningReduces, tts, avgProgress, System.currentTimeMillis(), false); if (tip != null) { scheduleReduce(tip); return tip.getIdWithinJob(); } } return -1; }
14 TaskTracker 的addToTaskQueue方法。对于要launch的task加入到taskQueue中去,不同类型的Task有不同类型额launcher。
private void addToTaskQueue(LaunchTaskAction action) { if (action.getTask().isMapTask()) { mapLauncher.addToTaskQueue(action); } else { reduceLauncher.addToTaskQueue(action); } }
完。
为了转载内容的一致性、可追溯性和保证及时更新纠错,转载时请注明来自:http://www.cnblogs.com/douba/p/hadoop_mapreduce_tasktracker_retrieve_task.html。谢谢!
posted on 2014-01-19 22:13 idouba.net 阅读(2154) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号