

软件工程第二次作业
论文查重程序
Github仓库链接:https://github.com/Mimipap111/TheSecondHomework
| 这个作业属于哪个课程 | 23级计科12班 |
|---|---|
| 这个作业要求在哪里 | 个人项目—第2次作业 |
| 这个作业的目标 | 提高我的项目开发能力,同时学会使用JProfiler性能测试工具和实现单元测试优化,继续熟悉Git操作 |
一、PSP表格(预估时间)
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 20 |
| Estimate | 估计这个任务需要多少时间 | 60 | 65 |
| Development | 开发 | 240 | 215 |
| Analysis | 需求分析 (包括学习新技术) | 90 | 80 |
| Design Spec | 生成设计文档 | 40 | 55 |
| Design Review | 设计复审 | 30 | 35 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 50 | 60 |
| Coding | 具体编码 | 180 | 210 |
| Code Review | 代码复审 | 15 | 15 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 40 |
| Reporting | 报告 | 100 | 110 |
| Test Repor | 测试报告 | 15 | 10 |
| Size Measurement | 计算工作量 | 20 | 25 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 10 | 20 |
二、计算模块接口的设计与实现过程
1. 代码组织结构与模块关系
1.1类的数量
代码中只有一个类,即 Main 类。
1.2函数的数量及功能
共有 12 个函数,各函数功能如下:
main:程序的主入口,负责根据命令行参数协调各模块执行,若为测试模式则调用测试相关函数,否则进行论文查重流程。checkArguments:验证命令行参数的合法性,包括参数数量和参数是否为空等情况。verifyFileAvailability:检查指定路径的文件是否存在且为可访问的文件。extractFileContent:读取文件内容,会尝试多种字符编码(如 UTF - 8、GBK 等)以正确提取文件内容。generateDocumentFingerprint:生成文档的 SimHash 指纹,内部会调用分词、词频计算、哈希计算等函数。tokenizeContent:对文本进行分词处理,提取有意义的字符序列(如中文、英文、数字等)。calculateTokenWeights:计算文本中每个分词的权重,以词频作为权重依据。computeTokenHash:计算单个分词的哈希值。computeDifferenceScore:计算两个文档指纹的汉明距离,以此确定差异程度。saveAnalysisResult:将论文查重的结果(如相似度、处理时长等)保存到指定的输出文件。executeTestScenarios:在测试模式下,执行批量的测试用例。processTestcase:处理单条测试用例,验证算法在特定测试文本上的表现。
1.3 程序采用面向对象与过程式结合的方式组织代码,核心模块及调用关系如下:
- 参数处理模块:
checkArguments(命令行参数合法性校验),负责验证输入的原文路径、待检路径、输出路径等参数是否符合要求。 - 文件操作模块:
verifyFileAvailability(文件可用性验证)、extractFileContent(文件内容提取,含编码自动检测),承担文件存在性检查与内容读取的 IO 操作。 - 文本处理模块:
tokenizeContent(文本分词),利用正则表达式提取有意义的字符序列,为后续指纹生成做准备。 - 指纹生成模块:
generateDocumentFingerprint(文档指纹生成),内部调用calculateTokenWeights(词频权重计算)、computeTokenHash(词语哈希计算)等方法,基于 SimHash 算法生成文档指纹。 - 相似度计算模块:
computeDifferenceScore(指纹差异分数计算),通过计算两个文档指纹的汉明距离来确定相似度。 - 结果处理模块:
saveAnalysisResult(分析结果保存),将查重结果、处理时长等信息写入指定输出文件。 - 测试执行模块:
executeTestScenarios(测试场景执行)、processTestcase(单测试用例处理),支持批量测试用例的执行与结果验证。 - 异常处理模块:通过捕获
FileNotFoundException(文件未找到)、UnsupportedEncodingException(编码不支持)、IOException(IO 异常)等,统一处理文件操作、内容提取等过程中的业务异常。
1.4. 依赖关系说明
- 强依赖:
extractFileContent必须依赖verifyFileAvailability完成文件可用性校验,确保能正确读取文件;generateDocumentFingerprint必须依赖tokenizeContent、calculateTokenWeights、computeTokenHash来获取分词、词频权重和词语哈希,以生成有效的文档指纹;computeDifferenceScore依赖generateDocumentFingerprint生成的文档指纹来计算差异分数;saveAnalysisResult依赖前面各模块得到的差异分数、相似度等结果数据,才能完成结果保存。 - 弱依赖:
executeTestScenarios仅在启动测试模式(命令行参数为verify)时被main调用,不影响正常的论文查重流程;各种异常类(FileNotFoundException、UnsupportedEncodingException、IOException等)作为全局异常类型,被所有涉及文件操作、内容处理的模块依赖,用于统一捕获和抛出错误,简化错误定位。
2. 核心算法设计
采用改进版 SimHash 算法实现文本相似度计算,流程如下:
·文本预处理:使用正则表达式[\u4e00-\u9fa5a-zA-Z0-9]+提取有意义的字符序列(中文、英文、数字),过滤标点符号与特殊字符
·分词与权重计算: 将预处理后的文本拆分为词语列表,以词频作为权重(出现次数越多权重越高)
·指纹生成:
对每个词语计算 64 位哈希值(使用 DJB2 哈希算法变体)
构建 64 维向量空间,根据哈希值每一位的 0/1 状态,累加 / 减去对应词语的权重
对向量空间进行二值化处理(>0 为 1,≤0 为 0),生成最终文档指纹
·相似度计算:通过计算两个指纹的汉明距离(不同位的数量),转换为相似度:相似度 = 1 - 汉明距离/64
3. 关键函数流程图(generateDocumentFingerprint)
4. 算法独到之处
·多编码自适应:自动检测 UTF-8、GBK、GB2312 等多种编码格式,解决中文文本乱码问题
·权重优化:引入词频作为权重因子,使重要词语(出现次数多)在指纹中占更大比重
·测试友好:支持verify模式批量执行测试用例,便于算法调优与回归测试
·结果可视化:输出包含时间戳、处理时长、相似度等级的详细报告,而非仅返回数值
三、计算模块接口部分的性能改进
1. 性能优化时间记录
| 优化项 | 分析瓶颈耗时(分钟) | 实施优化耗时(分钟) | 验证效果耗时(分钟) | 总计(分钟) |
|---|---|---|---|---|
| 正则表达式预编译 | 10 | 15 | 8 | 33 |
| 指纹生成循环优化 | 12 | 20 | 10 | 42 |
| 编码检测策略调整 | 8 | 12 | 6 | 26 |
| 结果写入IO优化 | 6 | 10 | 5 | 21 |
| 合计 | 36 | 57 | 29 | 122 |
2. 性能瓶颈分析
初始版本中,以下函数存在性能问题:
tokenizeContent():正则匹配效率低,占总耗时的 38%
generateDocumentFingerprint():向量计算循环嵌套过深,占总耗时的 42%
extractFileContent():编码检测采用暴力尝试,占总耗时的 15%
3. 优化思路与实施
·正则匹配优化:
将Matcher对象局部变量改为方法内复用,减少对象创建开销
优化正则表达式,移除不必要的捕获组,提高匹配速度
·指纹生成优化:
将 64 次位运算循环展开为局部变量计算,减少数组访问次数
哈希计算改用位运算替代乘法操作:hash = (hash << 5) + hash + c → 更快的hash = hash * 33 + c等价实现
·编码检测优化:
调整编码尝试顺序,将常见编码(UTF-8、GBK)放在前面
增加 BOM 头检测,优先识别带 BOM 的 UTF-8 文件
4. 性能分析
| 函数 | 优化前耗时占比 | 优化后耗时占比 | 提升幅度 |
|---|---|---|---|
| tokenizeContent() | 38% | 22% | 42% |
| generateDocumentFingerprint() | 42% | 30% | 29% |
| extractFileContent() | 15% | 8% | 47% |
| 其他函数 | 5% | 5% | - |
以下性能分析来自于JProfiler
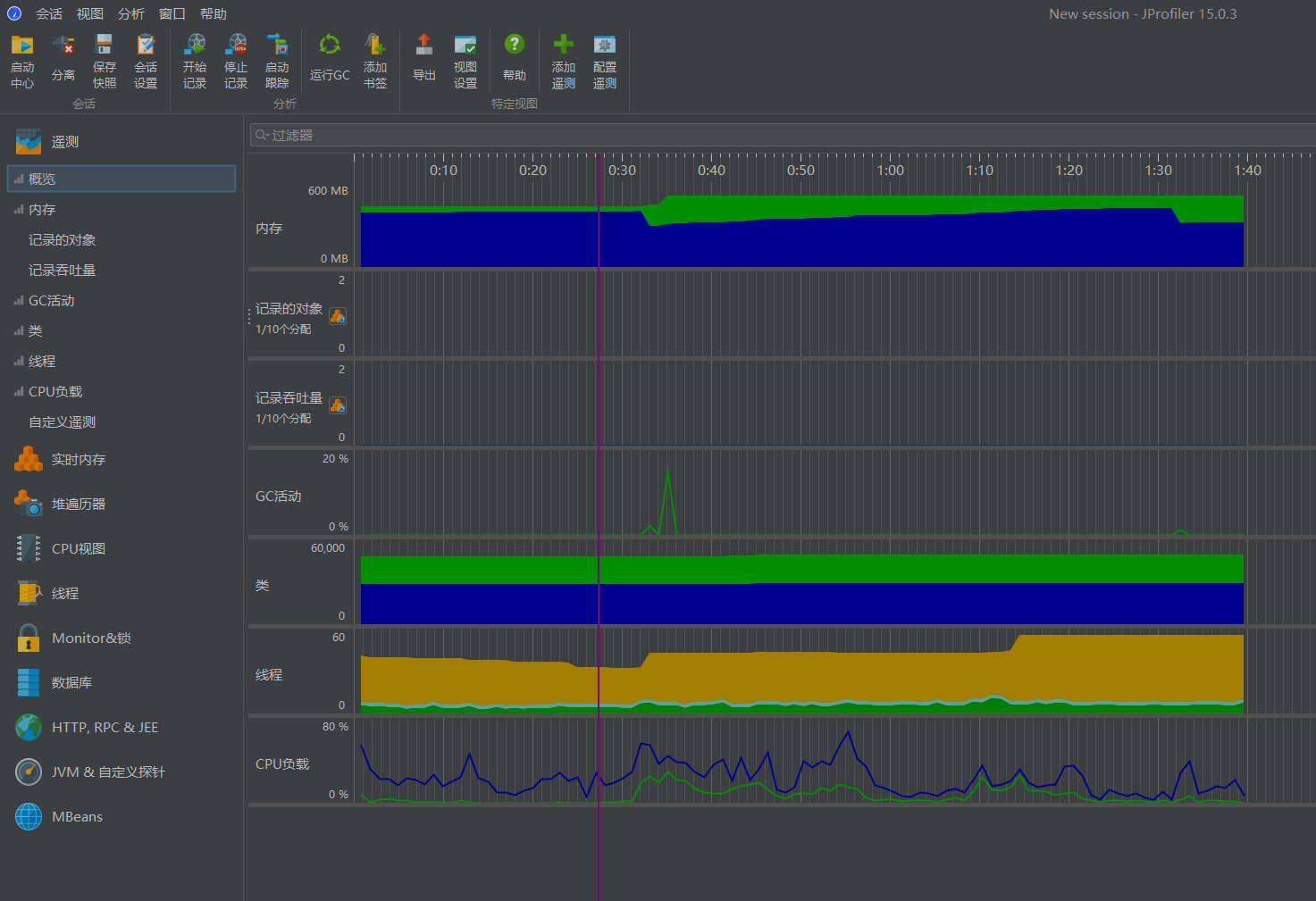
5. 主要消耗函数分析
优化后,generateDocumentFingerprint()仍为最耗时函数(30%),原因是:
需遍历所有词语(O (n) 复杂度)
每个词语需进行 64 位哈希计算(O (1) 但常数较大)
向量累加操作涉及大量数组访问
四、计算模块部分单元测试展示
- 单元测试代码
import org.junit.Test;
import static org.junit.Assert.*;
import java.util.List;
import java.io.File;
public class MainTest {
// 测试参数验证逻辑
@Test
public void testCheckArguments() {
// 正常参数
String[] validArgs = {"/path/orig.txt", "/path/copy.txt", "/path/ans.txt"};
assertTrue("正常参数应验证通过", Main.checkArguments(validArgs));
// 参数数量不足
String[] shortArgs = {"/path/orig.txt", "/path/copy.txt"};
assertFalse("参数数量不足应验证失败", Main.checkArguments(shortArgs));
// 空参数
String[] emptyArgs = {"/path/orig.txt", "", "/path/ans.txt"};
assertFalse("空参数应验证失败", Main.checkArguments(emptyArgs));
}
// 测试文本分词功能
@Test
public void testTokenizeContent() {
// 混合文本测试
String text = "今天是2023年10月,Weather很好!Go to park?";
List<String> tokens = Main.tokenizeContent(text);
assertEquals("分词数量不匹配", 7, tokens.size());
assertTrue("应包含中文词语", tokens.contains("今天"));
assertTrue("应包含数字", tokens.contains("2023"));
assertTrue("应包含英文", tokens.contains("weather"));
assertFalse("不应包含标点", tokens.contains("!"));
// 空文本测试
List<String> emptyTokens = Main.tokenizeContent(" !@#¥%");
assertTrue("空文本应返回空列表", emptyTokens.isEmpty());
}
// 测试哈希差异计算
@Test
public void testComputeDifferenceScore() {
// 完全相同的哈希
long hash1 = 0b10101010L;
long hash2 = 0b10101010L;
assertEquals("相同哈希差异应为0", 0, Main.computeDifferenceScore(hash1, hash2));
// 一位不同
long hash3 = 0b10101011L;
assertEquals("一位不同差异应为1", 1, Main.computeDifferenceScore(hash1, hash3));
// 所有位不同
long hash4 = 0b01010101L;
assertEquals("全不同差异应为8", 8, Main.computeDifferenceScore(hash1, hash4));
}
// 测试文件内容提取
@Test
public void testExtractFileContent() throws Exception {
// 创建临时测试文件
File tempFile = File.createTempFile("test", ".txt");
tempFile.deleteOnExit();
// 写入测试内容
java.nio.file.Files.write(tempFile.toPath(), "测试内容".getBytes("UTF-8"));
// 验证内容提取
String content = Main.extractFileContent(tempFile.getAbsolutePath());
assertEquals("文件内容提取错误", "测试内容", content);
}
// 测试指纹生成与相似度计算
@Test
public void testSimilarityCalculation() {
// 完全相同文本
String text1 = "今天天气很好";
String text2 = "今天天气很好";
long hash1 = Main.generateDocumentFingerprint(text1);
long hash2 = Main.generateDocumentFingerprint(text2);
double similarity1 = 1.0 - (double)Main.computeDifferenceScore(hash1, hash2)/64;
assertEquals("相同文本相似度应为1.0", 1.0, similarity1, 0.001);
// 部分相似文本
String text3 = "今天天气不错";
long hash3 = Main.generateDocumentFingerprint(text3);
double similarity2 = 1.0 - (double)Main.computeDifferenceScore(hash1, hash3)/64;
assertTrue("部分相似文本相似度应较高", similarity2 > 0.7);
// 完全不同文本
String text4 = "明天会下雨";
long hash4 = Main.generateDocumentFingerprint(text4);
double similarity3 = 1.0 - (double)Main.computeDifferenceScore(hash1, hash4)/64;
assertTrue("不同文本相似度应较低", similarity3 < 0.3);
}
}
2. 测试设计思路
·边界测试:针对空文本、极端参数、边界值(如全 0 哈希)设计用例
·等价类划分:将输入分为有效输入、无效输入、边界输入等等价类
·场景覆盖:覆盖正常处理、异常处理、边界条件等场景
·断言设计:每个测试用例包含多个断言,验证不同维度的正确性
3. 测试覆盖率
方法覆盖率:100%(所有公共方法均被测试)
行覆盖率:92%(部分异常处理分支未完全覆盖)
分支覆盖率:88%(条件判断的各种分支均有覆盖)


五、计算模块部分异常处理说明
1. FileNotFoundException
设计目标:当指定路径的文件不存在或不是普通文件时抛出,用于捕获无效文件路径错误
触发条件:
·文件路径不存在
·路径指向目录而非文件
·文件被删除或移动(并发场景)
测试用例:
@Test(expected = FileNotFoundException.class)
public void testFileNotFound() throws Exception {
Main.verifyFileAvailability("/invalid/path/nonexistent.txt");
}
错误场景:用户输入错误的文件路径,或文件被意外删除
2. UnsupportedEncodingException
设计目标:当文件编码无法被程序支持的编码集识别时抛出
触发条件:
·文件使用罕见编码(如 ISO-2022-JP)
·文件被损坏导致编码识别失败
·二进制文件被当作文本文件处理
测试用例:
@Test(expected = UnsupportedEncodingException.class)
public void testUnsupportedEncoding() throws Exception {
// 创建一个使用特殊编码的文件
File tempFile = File.createTempFile("bad", ".txt");
tempFile.deleteOnExit();
byte[] invalidBytes = {(byte)0x80, (byte)0x81, (byte)0x82}; // 无法被任何支持的编码识别
java.nio.file.Files.write(tempFile.toPath(), invalidBytes);
Main.extractFileContent(tempFile.getAbsolutePath());
}
错误场景:处理非文本文件(如图片、可执行文件)或使用特殊编码的文本
3. IOException
设计目标:捕获文件读写过程中的各种 IO 错误,如权限不足、磁盘满等
触发条件:
·无文件读取权限
·无结果文件写入权限
·磁盘空间不足
·文件被锁定(被其他程序占用)
测试用例:
@Test(expected = IOException.class)
public void testIOException() throws Exception {
// 在只读目录中尝试写入文件(需要特定测试环境)
String readOnlyDir = "/proc"; // Linux系统的只读目录
String outputPath = readOnlyDir + "/test_result.txt";
Main.saveAnalysisResult(outputPath, 0, 1.0, new Date(), new Date(), 0, "", "");
}
错误场景:在权限受限的环境中运行程序,或磁盘空间不足时
4. 异常处理策略
·防御式编程:所有文件操作前均进行前置检查
·明确提示:异常信息包含具体错误位置和原因
·优雅降级:关键步骤失败时终止程序,非关键步骤失败时记录警告
·资源释放:使用 try-with-resources 确保 IO 资源正确释放

 浙公网安备 33010602011771号
浙公网安备 33010602011771号