
作业3
数据采集与融合技术作业3
实验一
(1)实验过程
要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
核心代码及思路
单线程爬取(crawl_single_thread)
def crawl_single_thread(self, max_pages=10):
"""单线程爬取"""
print("开始单线程爬取...")
start_time = time.time()
urls_to_visit = [self.base_url]
self.visited_urls.add(self.base_url)
page_count = 0
while urls_to_visit and page_count < max_pages:
current_url = urls_to_visit.pop(0)
print(f"正在爬取页面: {current_url}")
# 提取图片URL
image_urls = self.extract_image_urls(current_url)
for img_url in image_urls:
if img_url not in self.image_urls:
self.image_urls.add(img_url)
self.download_image(img_url)
# 提取其他页面链接
if page_count < max_pages:
new_urls = self.extract_page_urls(current_url)
for url in new_urls:
if url not in self.visited_urls:
self.visited_urls.add(url)
urls_to_visit.append(url)
page_count += 1
end_time = time.time()
核心思路:采用队列(FIFO)实现广度优先爬取,依次处理每个页面,同步提取图片和新链接
多线程爬取(crawl_multithread)
def crawl_multithread(self, max_pages=10, max_workers=5):
def process_page(url):
image_urls = self.extract_image_urls(url)
with self.lock:
self.image_urls.update(image_urls)
...
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
urls_to_visit = [self.base_url]
self.visited_urls.add(self.base_url)
futures = {} # 存储线程任务
while (urls_to_visit or futures) and page_count < max_pages:
# 提交新任务到线程池
while urls_to_visit and len(futures) < max_workers:
url = urls_to_visit.pop(0)
future = executor.submit(process_page, url)
futures[future] = url
page_count += 1
done, _ = concurrent.futures.wait(futures, timeout=1, return_when=FIRST_COMPLETED)
for future in done:
new_urls = future.result()
urls_to_visit.extend(new_urls) # 添加新发现的链接
# 单独用多线程下载所有图片
self.download_images_multithread(max_workers)
核心思路:
用线程池并发处理页面爬取,提高效率
通过线程锁(Lock)保证共享集合(visited_urls、image_urls)的线程安全
分两步:先多线程爬取所有图片 URL,再多线程下载图片
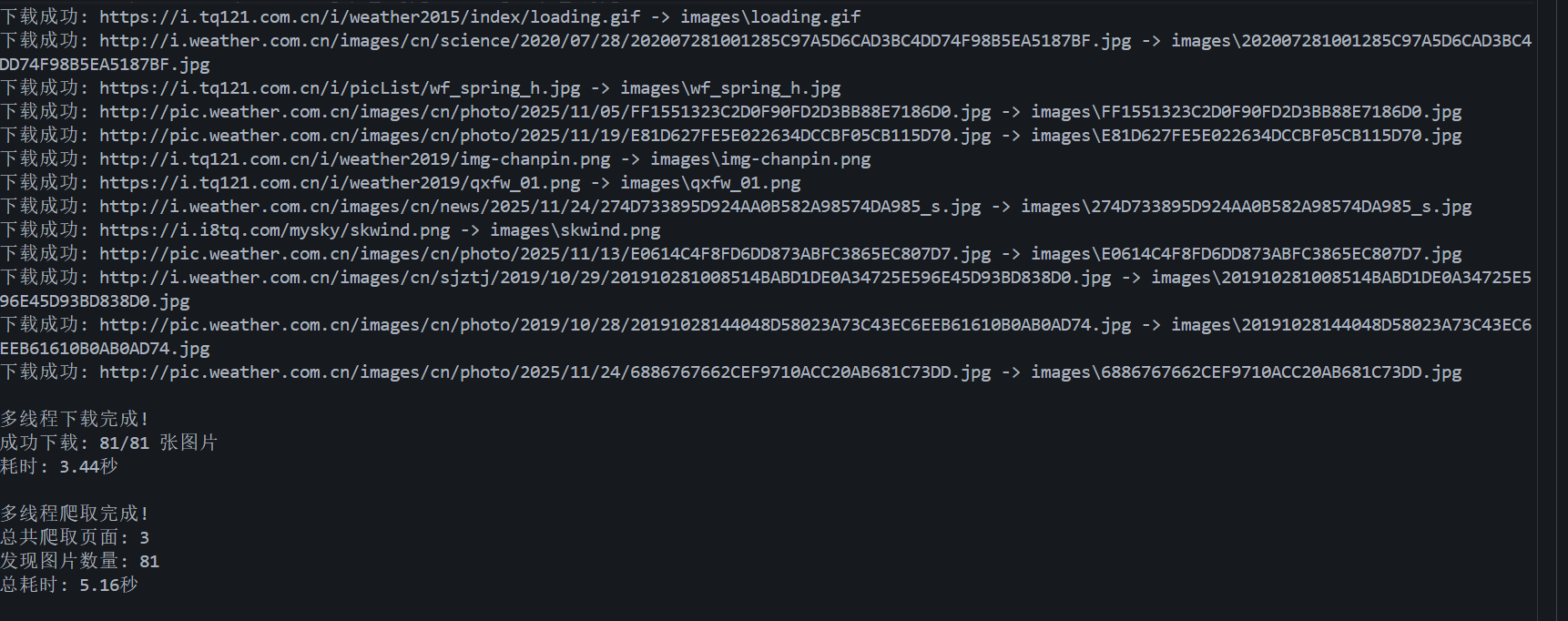
输出信息:
代码仓库地址:https://gitee.com/oozyt/datacollecting/tree/master/作业3/实验任务一
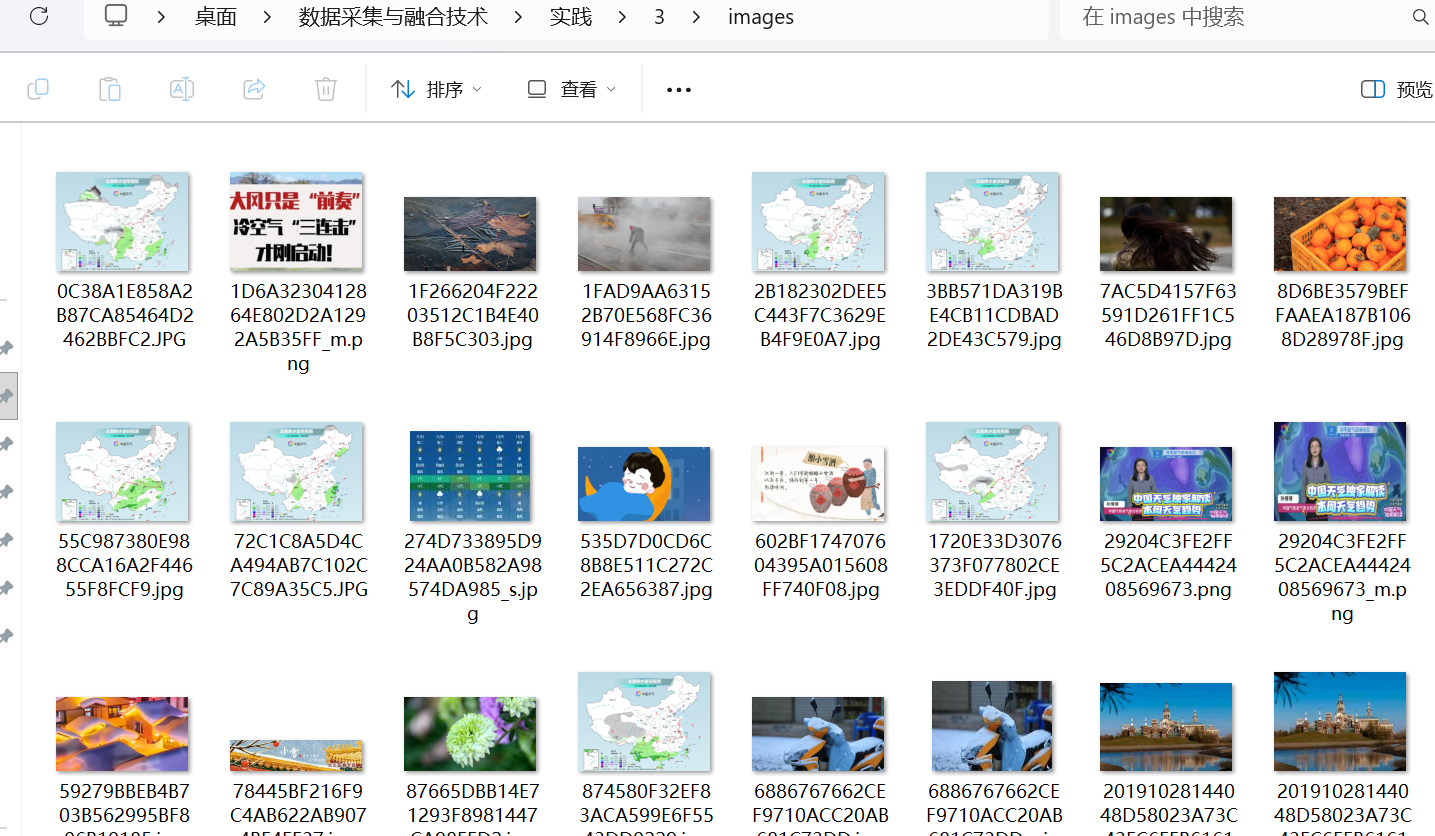
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
(2)心得体会
将 URL 处理、页面解析、图片下载等功能拆分为独立方法,不仅让代码结构清晰,也便于后续维护和扩展。同时,单线程与多线程模式的对比实践,直观展现了并发编程在提升效率上的优势,但也需注意线程安全问题,通过锁机制保护共享资源能有效避免数据混乱。此外,异常处理和去重逻辑的完善,让爬虫更健壮,能应对网络波动、重复链接等常见问题,这些细节处理对程序的稳定性至关重要。
实验二
(1)实验过程
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
核心代码及思路
items.py 数据结构定义
import scrapy
class StockItem(scrapy.Item):
serial_num = scrapy.Field() # 序号
stock_code = scrapy.Field() # 股票代码
stock_name = scrapy.Field() # 股票名称
last_price = scrapy.Field() # 最新价
change_rate = scrapy.Field() # 涨跌幅(%)
change_amt = scrapy.Field() # 涨跌额
volume = scrapy.Field() # 成交量
turnover = scrapy.Field() # 成交额
amplitude = scrapy.Field() # 振幅(%)
high = scrapy.Field() # 最高价
low = scrapy.Field() # 最低价
open_today = scrapy.Field() # 今开盘价
prev_close = scrapy.Field() # 昨收盘价
crawl_time = scrapy.Field() # 爬取时间
eastmoney.py 爬虫核心
import scrapy
import json
from datetime import datetime
from stock_crawler.items import StockItem
class EastMoneySpider(scrapy.Spider):
name = "eastmoney"
allowed_domains = ["eastmoney.com"] # 允许爬取的域名,限制爬虫范围
base_url = "https://push2.eastmoney.com/api/qt/clist/get?np=1&fltt=1&invt=2&cb=jQuery3710842672203006353_1762259275768&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A81%2Bs%3A262144%2Bf%3A!2&fields=f12%2Cf13%2Cf14%2Cf2%2Cf4%2Cf3%2Cf152%2Cf5%2Cf6%2Cf7%2Cf15%2Cf18%2Cf16%2Cf17%2Cf10%2Cf8%2Cf9%2Cf23&fid=f3&pn={page}&pz={page_size}&po=1&dect=1&ut=fa5fd1943c7b386f172d6893dbfba10b&wbp2u=%7C0%7C0%7C0%7Cweb&_=1762259275772"
def start_requests(self):
total_pages = getattr(self, "pages", 3)
page_size = getattr(self, "page_size", 20)
for page in range(1, int(total_pages) + 1):
# 格式化URL,替换分页参数
url = self.base_url.format(page=page, page_size=page_size)
yield scrapy.Request(
url=url,
headers=self.get_headers(),
meta={"page": page, "page_size": page_size},
callback=self.parse # 指定响应处理函数
)
def get_headers(self):
return {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Referer": "https://www.eastmoney.com/",
"Accept": "text/javascript, application/javascript"
}
def parse(self, response):
page = response.meta["page"]
page_size = response.meta["page_size"]
start_index = (page - 1) * page_size + 1
try:
data_str = response.text.strip() # 获取响应文本并去除首尾空白
json_start = data_str.index("({") + 1 # 定位JSON数据起始位置
json_end = data_str.rindex("})") + 1 # 定位JSON数据结束位置
pure_json = data_str[json_start:json_end] # 提取纯JSON字符串
result = json.loads(pure_json) # 解析为JSON对象
except (ValueError, json.JSONDecodeError) as e:
self.logger.error(f"第{page}页解析失败:{e}")
return
# 检查JSON数据结构是否包含股票列表
if "data" in result and "diff" in result["data"]:
stock_list = result["data"]["diff"] # 提取股票数据列表
# 遍历每条股票数据
for idx, stock in enumerate(stock_list):
item = StockItem() # 创建数据项对象
item["serial_num"] = start_index + idx # 计算当前股票的序号
item["stock_code"] = stock.get("f12", "") # f12字段对应股票代码
item["stock_name"] = stock.get("f14", "") # f14字段对应股票名称
# 价格类字段需要除以100(接口返回单位为分),并保留2位小数
item["last_price"] = round(stock.get("f2", 0)/100, 2) if stock.get("f2") else 0.00 # f2对应最新价
item["change_rate"] = round(stock.get("f3", 0)/100, 2) if stock.get("f3") else 0.00 # f3对应涨跌幅(%)
item["change_amt"] = round(stock.get("f4", 0)/100, 2) if stock.get("f4") else 0.00 # f4对应涨跌额
item["volume"] = stock.get("f5", 0) if stock.get("f5") else 0 # f5对应成交量(单位:股)
# 成交额处理
turnover_original = stock.get("f6", 0)/100 if stock.get("f6") else 0 # f6对应成交额原始值
item["turnover"] = f"{turnover_original/100000000:.1f}亿" if turnover_original >=1e8 else f"{turnover_original/10000:.1f}万"
# 其他字段映射
item["amplitude"] = round(stock.get("f7", 0)/100, 2) if stock.get("f7") else 0.00 # f7对应振幅(%)
item["high"] = round(stock.get("f15", 0)/100, 2) if stock.get("f15") else 0.00 # f15对应最高价
item["low"] = round(stock.get("f16", 0)/100, 2) if stock.get("f16") else 0.00 # f16对应最低价
item["open_today"] = round(stock.get("f17", 0)/100, 2) if stock.get("f17") else 0.00 # f17对应今开盘价
item["prev_close"] = round(stock.get("f18", 0)/100, 2) if stock.get("f18") else 0.00 # f18对应昨收盘价
item["crawl_time"] = datetime.now().strftime("%Y-%m-%d %H:%M:%S") # 记录爬取时间
yield item
self.logger.info(f"第{page}页解析完成,共{len(stock_list) if 'data' in result else 0}条")
pipelines.py 数据存储
import pymysql
from pymysql.err import OperationalError, IntegrityError
class StockMysqlPipeline:
def __init__(self, mysql_host, mysql_user, mysql_pass, mysql_db, mysql_port):
# 初始化数据库连接参数
@classmethod
def from_crawler(cls, crawler):
# 从配置文件读取数据库参数
def open_spider(self, spider):
self.conn = pymysql.connect(...) # 建立数据库连接
self.create_stock_table() # 创建数据表
def create_stock_table(self):
create_sql = '''
CREATE TABLE IF NOT EXISTS stock_info (
id INTEGER PRIMARY KEY AUTO_INCREMENT,
serial_num INTEGER NOT NULL,
stock_code VARCHAR(20) NOT NULL,
# 其他字段定义...
crawl_time DATETIME NOT NULL,
UNIQUE KEY uk_stock_crawl (stock_code, crawl_time) # 防重复
)
'''
self.cursor.execute(create_sql)
def process_item(self, item, spider):
insert_sql = '''
INSERT IGNORE INTO stock_info (...) VALUES (%s, %s, ...)
'''
values = (item["serial_num"], item["stock_code"], ...) # 字段值映射
self.cursor.execute(insert_sql, values)
self.conn.commit()
思路:基于pymysql实现 MySQL 数据库连接,从配置文件读取连接参数;
爬虫启动时自动创建stock_info表,定义字段类型及唯一索引(stock_code + crawl_time)避免重复数据;
接收StockItem对象,通过INSERT IGNORE语句将数据写入数据库,结合事务管理(commit/rollback)确保数据存储稳定性。
settings.py 配置管理
# 爬虫基本配置
BOT_NAME = "stock_crawler"
SPIDER_MODULES = ["stock_crawler.spiders"]
# 爬虫行为控制
ROBOTSTXT_OBEY = False # 不遵守robots协议
CONCURRENT_REQUESTS_PER_DOMAIN = 1 # 单域名并发请求数
DOWNLOAD_DELAY = 1 # 下载延迟(秒)
# 数据管道配置
ITEM_PIPELINES = {
"stock_crawler.pipelines.StockMysqlPipeline": 300,
}
# 数据库连接信息
MYSQL_HOST = "localhost"
MYSQL_USER = "root"
MYSQL_PASSWORD = "root"
MYSQL_DB = "stock_db"
MYSQL_PORT = 3306
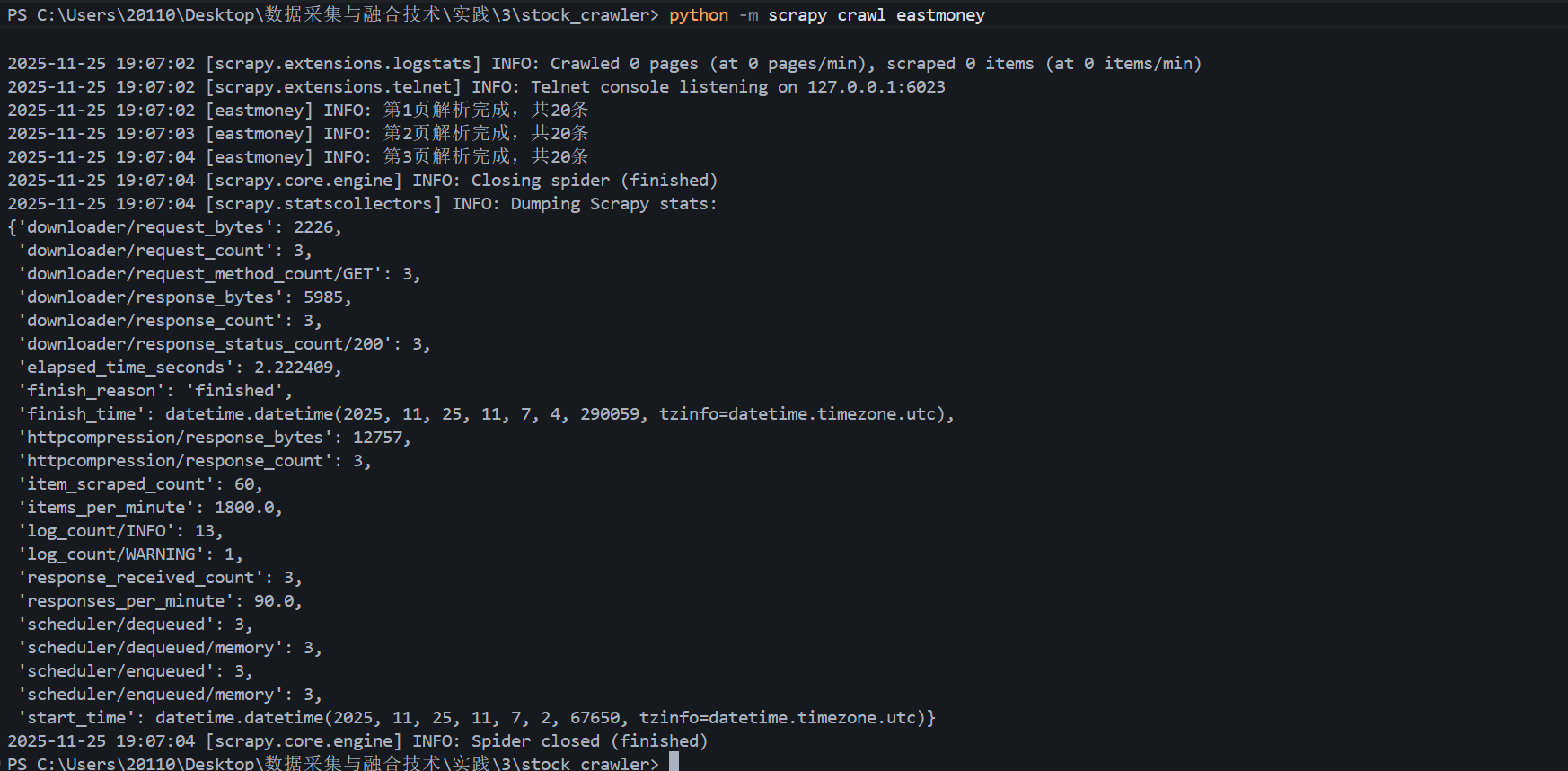
输出信息:
代码仓库地址:https://gitee.com/oozyt/datacollecting/tree/master/作业3/实验任务二
终端运行输出:
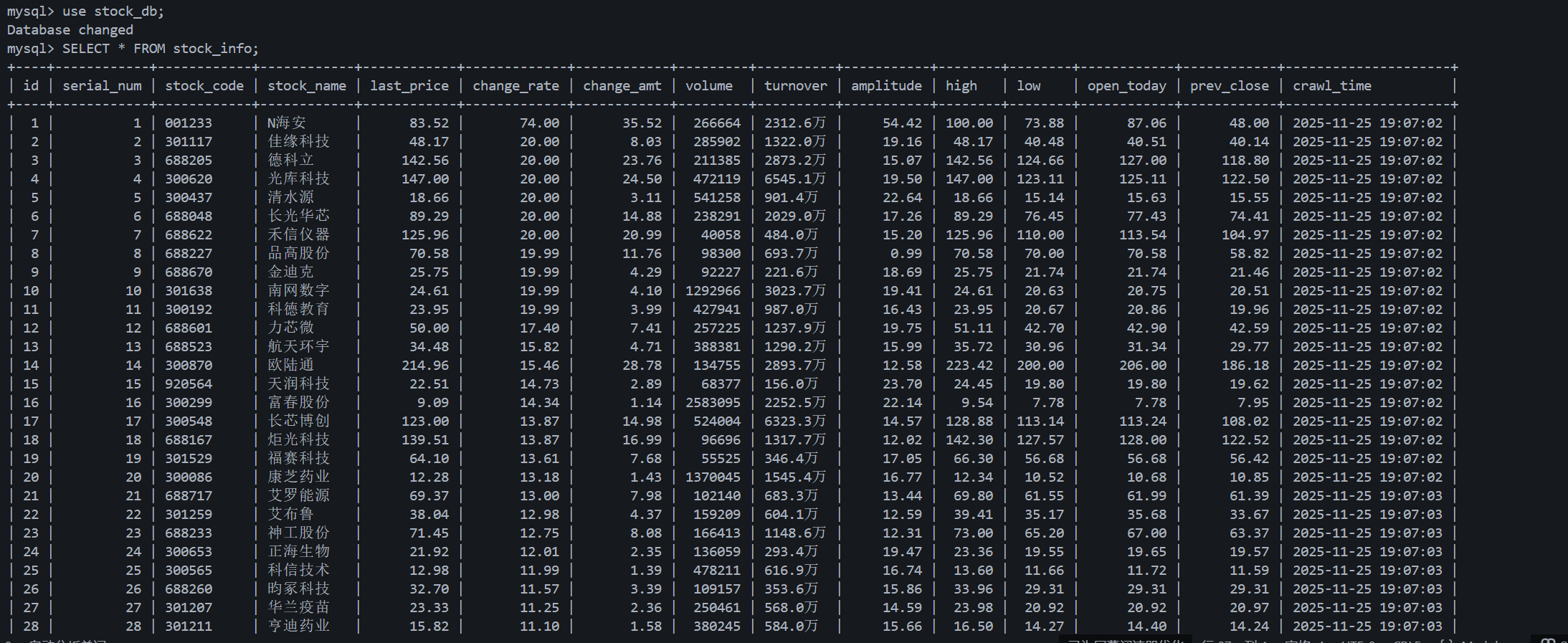
查看mysql结果:
(2)心得体会
该网站的股票数据通过动态加载的API接口获取并渲染到页面的,并非直接嵌入在HTML静态代码中,XPath依赖于网页DOM结构提取数据,无法直接定位到接口返回的隐藏数据;且页面结构复杂且可能随更新变动,XPath表达式易失效,用XPath不好实现。因此我通过分析API接口实现数据获取,API返回的JSON数据结构固定、字段映射明确(如f12对应股票代码、f2对应最新价),不仅避免了因页面DOM结构变动导致的解析失效问题,还能通过pn(页码)、pz(每页条数)等参数高效批量获取数据,大幅降低了数据提取的复杂度。
在具体实现中:将接口返回的“分”单位价格除以100转换为“元”,根据成交额数值动态转换“万/亿”单位,以及用round()函数统一保留两位小数,这些处理让原始数据更贴合实际使用场景。同时,Scrapy框架的组件化设计(Spider负责请求与解析、Item定义数据结构、Pipeline处理存储)让流程清晰可控,尤其是通过MySQL Pipeline的UNIQUE KEY约束避免重复存储.
实验三
(1)实验过程
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
items.py 数据结构定义
import scrapy
class ForexItem(scrapy.Item):
currency = scrapy.Field() # 货币名称
tbp = scrapy.Field() # 现汇买入价(TBP)
cbp = scrapy.Field() # 现钞买入价(CBP)
tsp = scrapy.Field() # 现汇卖出价(TSP)
csp = scrapy.Field() # 现钞卖出价(CSP)
time = scrapy.Field() # 发布时间(Time)
eastmoney.py 爬虫核心
import scrapy
from forex_crawler.items import ForexItem
class BocForexSpider(scrapy.Spider):
name = "boc_forex"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
# 精准定位第2个表格的所有数据行(跳过表头行)
# 第2个表格的XPath:(//table)[2],取tr[position()>1]即数据行
rows = response.xpath('(//table)[2]//tr[position()>1]')
self.logger.info(f"找到 {len(rows)} 条数据行") # 现在会显示实际行数(如30+)
for row in rows:
# 提取字段(对应表格列:1=货币,2=现汇买入价,3=现钞买入价,4=现汇卖出价,5=现钞卖出价,8=发布时间)
currency = row.xpath('./td[1]/text()').get()
tbp = row.xpath('./td[2]/text()').get()
cbp = row.xpath('./td[3]/text()').get()
tsp = row.xpath('./td[4]/text()').get()
csp = row.xpath('./td[5]/text()').get()
time = row.xpath('./td[8]/text()').get()
# 过滤空数据(处理表格中可能的空值)
if currency and time:
item = ForexItem()
item["currency"] = currency.strip()
# 处理空值/'-'符号,转为None(MySQL会存为NULL)
item["tbp"] = tbp.strip() if (tbp and tbp.strip() not in ['', '-']) else None
item["cbp"] = cbp.strip() if (cbp and cbp.strip() not in ['', '-']) else None
item["tsp"] = tsp.strip() if (tsp and tsp.strip() not in ['', '-']) else None
item["csp"] = csp.strip() if (csp and csp.strip() not in ['', '-']) else None
item["time"] = time.strip()
yield item
self.logger.info(f"提取数据:{item['currency']} - 现汇卖出价:{item['tsp']}")
pipelines.py 数据存储
import pymysql
class ForexMysqlPipeline:
def __init__(self, mysql_host, mysql_user, mysql_pass, mysql_db, mysql_port):
self.host = mysql_host
self.user = mysql_user
self.passwd = mysql_pass
self.db = mysql_db
self.port = mysql_port
self.conn = None
self.cursor = None
@classmethod
def from_crawler(cls, crawler):
# 从settings.py读取MySQL配置
return cls(
mysql_host=crawler.settings.get("MYSQL_HOST"),
mysql_user=crawler.settings.get("MYSQL_USER"),
mysql_pass=crawler.settings.get("MYSQL_PASSWORD"),
mysql_db=crawler.settings.get("MYSQL_DB"),
mysql_port=crawler.settings.get("MYSQL_PORT", 3306)
)
def open_spider(self, spider):
# 连接数据库+创建表
self.conn = pymysql.connect(
host=self.host,
user=self.user,
password=self.passwd,
db=self.db,
port=self.port,
charset="utf8mb4"
)
self.cursor = self.conn.cursor()
# 创建外汇数据表
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS forex_rate (
id INT PRIMARY KEY AUTO_INCREMENT,
currency VARCHAR(50) NOT NULL,
tbp DECIMAL(10,2),
cbp DECIMAL(10,2),
tsp DECIMAL(10,2),
csp DECIMAL(10,2),
time VARCHAR(20) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
''')
self.conn.commit()
def process_item(self, item, spider):
# 插入数据
insert_sql = '''
INSERT INTO forex_rate (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
'''
values = (
item["currency"],
item["tbp"],
item["cbp"],
item["tsp"],
item["csp"],
item["time"]
)
self.cursor.execute(insert_sql, values)
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
settings.py 配置管理
# 启用MySQL Pipeline
ITEM_PIPELINES = {
"forex_crawler.pipelines.ForexMysqlPipeline": 300, # 300为优先级
}
# MySQL数据库配置
MYSQL_HOST = "localhost"
MYSQL_USER = "root"
MYSQL_PASSWORD = "root"
MYSQL_DB = "forex_db" # 需提前创建
MYSQL_PORT = 3306
# 反爬设置
ROBOTSTXT_OBEY = False # 不遵守robots协议
CONCURRENT_REQUESTS_PER_DOMAIN = 1 # 单域名并发数
DOWNLOAD_DELAY = 1 # 下载延迟(秒)
实现思路:
数据结构定义
通过ForexItem类规范化需要爬取的数据字段,对应外汇牌价中的核心信息(货币名称、现汇 / 现钞买入价、现汇 / 现钞卖出价、发布时间),确保数据格式统一,为后续处理提供结构化基础。
页面爬取与解析(Spider)
以中国银行外汇牌价页面为起始 URL,通过 Scrapy 的start_urls发起请求。
使用 XPath 定位页面中包含外汇数据的表格(第 2 个表格),提取所有数据行(跳过表头)。
逐行解析表格数据,按列索引提取对应字段值,同时处理空值和特殊符号(如-),将清洗后的数据封装为ForexItem对象并传递给 Pipeline。
数据存储(Pipeline)
基于pymysql实现 MySQL 数据库连接,从配置文件读取数据库参数(主机、用户、密码等)。
爬虫启动时自动创建数据表(forex_rate),定义字段类型与约束(如价格字段为DECIMAL类型,货币名称和时间为非空字段)。
接收 Spider 传递的ForexItem,通过 SQL 插入语句将数据批量存储到数据库,并在爬虫结束时关闭连接,确保资源释放。
配置管理(Settings)
集中配置项目参数,包括启用 MySQL 存储管道、设置数据库连接信息、配置反爬策略(如下载延迟、并发控制),使项目结构清晰且易于维护。
输出信息:
代码仓库地址:https://gitee.com/oozyt/datacollecting/tree/master/作业3/实验任务三
(2)心得体会
通过使用Scrapy框架爬取中国银行外汇牌价数据并存储到MySQL的实践,深刻体会到框架对爬虫流程的高效管控,认识到精准解析网页结构、规范处理数据(如清洗空值与特殊符号)、合理设计数据库表结构的重要性,设置反爬策略以文明爬取,各环节的严谨处理是实现数据高效获取与可靠存储的关键。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号