
数据采集与融合技术作业1
数据采集与融合技术作业1
作业①
o 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
(1)实验部分
数据获取部分
def clean_university_ranking():
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
response = requests.get(url, headers=headers, timeout=10)
response.encoding = 'utf-8'
网站服务器通常会检测请求的User-Agent头信息来识别访问者身份,当使用python的requests库直接访问时,默认显示为python相关标识,容易被网站的反爬机制拦截,因此我们通过设置User-Agent来模拟浏览器访问,避免被反爬虫机制拦截。另外,设置timeout=10参数,代码规定了最长等待时间为10秒——如果服务器在10秒内没有返回任何数据,requests将自动抛出超时异常,使程序能够继续执行后续的错误处理逻辑。
数据解析部分
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table', class_='rk-table')
if not table:
print("未找到排名表格")
return None
rankings = []
rows = table.find_all('tr')[1:]
for row in rows:
cols = row.find_all('td')
if len(cols) >= 6:
rank = cols[0].get_text(strip=True)
name = cols[1].get_text(strip=True)
name = re.sub(r'[A-Za-z].*', '', name).strip()
province = cols[2].get_text(strip=True)
school_type = cols[3].get_text(strip=True)
score = cols[4].get_text(strip=True)
rankings.append([rank, name, province, school_type, score])
关键步骤 class_='rk-table' 可以通过css类名精确定位排名表格
rows = table.find_all('tr')[1:] 可以跳过表头行直接处理数据
名称清洗:re.sub(r'[A-Za-z].*', '', name) 通过源网页可以看出其中大学名称包括中英文,但是我们只需要中文名称 正则表达式 [A-Za-z].* 匹配从第一个英文字母开始的所有内容,并且将其替换为空
结果截图
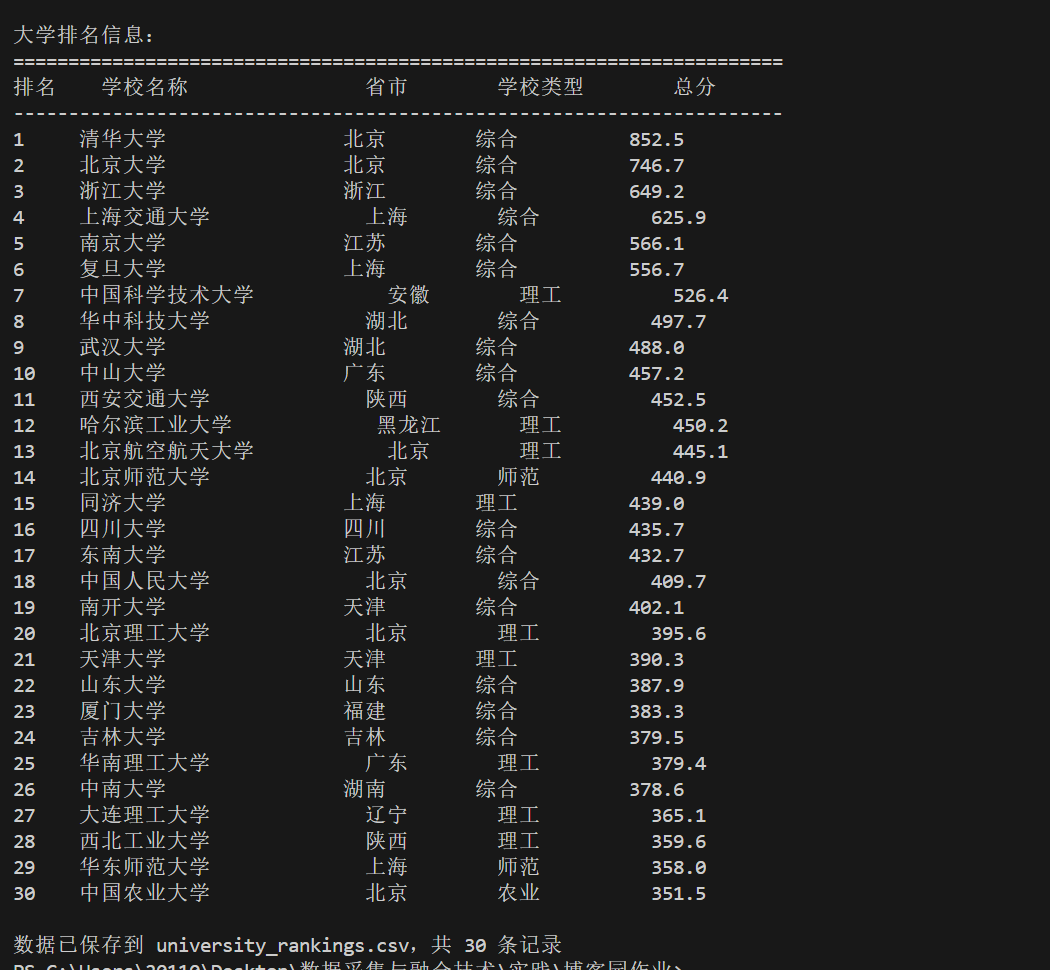
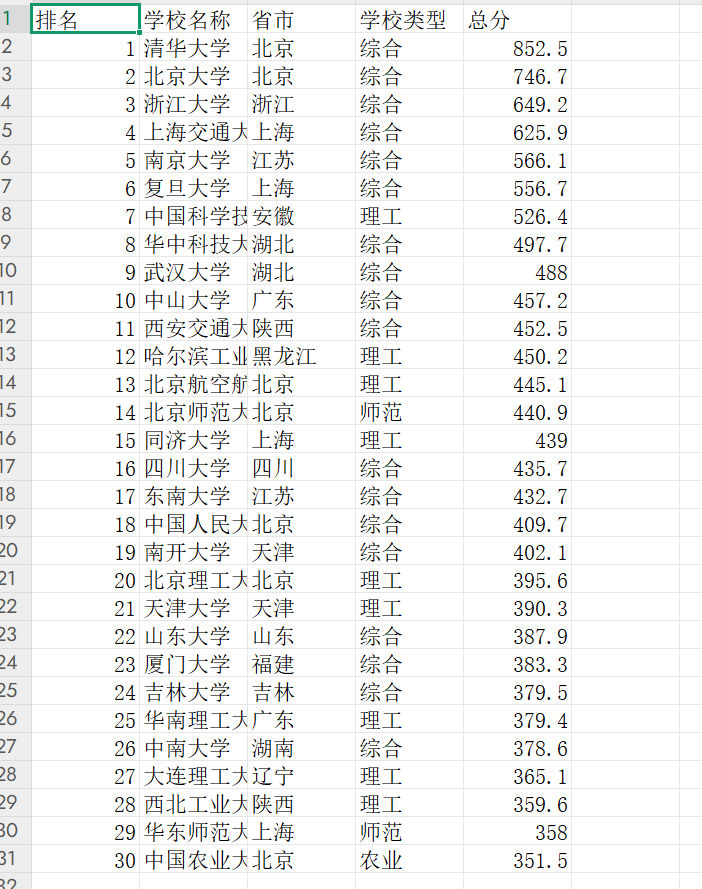
(2)心得体会
在数据获取环节,我设置合适的User-Agent头信息成功绕过了基础的反爬检测,并且通过简单的超时参数对网站信息进行爬取,一开始输出的数据中大学名称混杂着英文,后来使用正则表达式对原始数据进行清洗,将英文去掉,然后输出保存到csv文件中
作业②
o *要求:*用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
(1)实验部分
初始化部分
设置请求头,模拟浏览器访问避免被反爬
页面获取
def fetch_page(self, keyword, page):
encoded_keyword = quote(keyword.encode('gb2312'))
url = f"http://search.dangdang.com/?key={encoded_keyword}&page_index={page}"
将关键词编码为gb2312格式
构建搜索URL,包含关键词和页码
发送GET请求获取页面内容
解析页面提取商品列表
def parse_page(self, html, page):
soup = BeautifulSoup(html, 'html.parser')
products = []
product_list = soup.find('ul', class_='bigimg cloth_shoplist') or \
soup.find('div', id='search_nature_rg')
if product_list:
items = product_list.find_all('li', class_=re.compile(r'line\d+'))
else:
items = soup.find_all('li', class_=re.compile(r'line\d+'))
-
使用
BeautifulSoup解析 HTML,优先定位商品列表容器(ul.bigimg cloth_shoplist或div#search_nature_rg)。 -
从容器中提取所有商品项(
li标签,class 匹配line\d+,如line1、line2等)。 -
遍历商品项,调用
extract_product方法提取每个商品的详情 提取商品名称和价格
def extract_product(self, item_html): title = '' soup = BeautifulSoup(item_html, 'html.parser') title_tag = soup.find('p', class_='name') if title_tag and title_tag.a: title = title_tag.a.get('title', '').strip() if not title: match = re.search(r'<a[^>]*title="([^"]+)"', item_html) if match: title = match.group(1).strip() price = '0.00' price_tag = soup.find('p', class_='price') if price_tag: price_span = price_tag.find('span', class_='price_n') if price_span: price = price_span.get_text().strip().replace('¥', '') if not price or price == '0.00': match = re.search(r'class="price_n"[^>]*>(\d+\.\d+)', item_html) if match: price = match.group(1) return {'title': title, 'price': price}- 提取逻辑:
- 商品名称(title):
- 优先用
BeautifulSoup查找<p class="name">下的<a>标签,获取其title属性(最准确的商品名)。 - 若上述失败,用正则表达式从 HTML 中匹配
<a>标签的title属性(<a title="xxx">),作为备用方案。
- 优先用
- 价格(price):
- 优先用
BeautifulSoup查找<p class="price">下的<span class="price_n">标签,提取文本并去除 “¥” 符号。 - 若上述失败,用正则表达式匹配
class="price_n"对应的价格数值(如(\d+\.\d+)匹配类似129.00的价格)。
- 优先用
- 商品名称(title):
- 提取逻辑:
页面控制
def crawl(self, keyword="书包", pages=1):
all_products = []
for page in range(1, pages + 1):
print(f"爬取第{page}页...")
html = self.fetch_page(keyword, page)
if html:
products = self.parse_page(html, page)
all_products.extend(products)
print(f"第{page}页获取到{len(products)}个商品")
time.sleep(1)
return all_products
利用for循环爬取多页数据,每页间隔两秒避免请求过快
结果
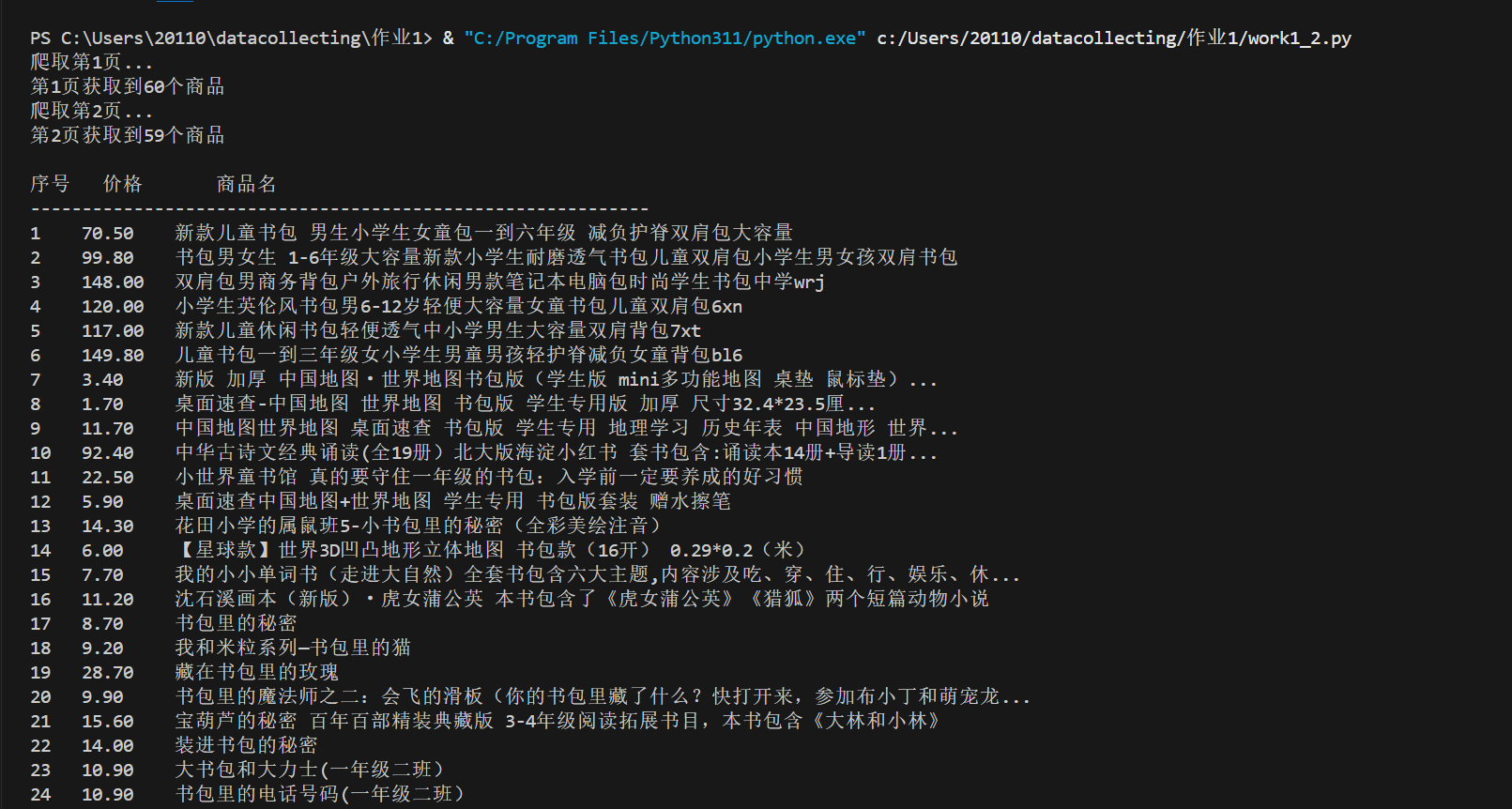
(2)心得体会
定向抓取比价数据时,先靠 Session 维持请求稳定性并模拟浏览器行为,用 GB2312 编码适配网站需求确保请求成功;解析环节发现采用bs4库更简单,最后了采用 BeautifulSoup 定位商品容器,搭配正则表达式灵活匹配的特性,双管齐下提取商品名和价格,保证准确性同时通过控制爬取间隔规避反爬风险,最后将数据按规范格式展示并保存为 CSV,整个流程聚焦核心需求,简化冗余逻辑,高效实现定向数据抓取目标。
作业③
o *要求:*爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
o *输出信息:*将自选网页内的所有JPEG、JPG或PNG格式文件保存在一个文件夹中
(1)实验部分
数据链接提取
def extract_image_urls(self, html_content):
soup = BeautifulSoup(html_content, 'html.parser')
image_urls = []
img_tags = soup.find_all('img')
for img in img_tags:
src = img.get('src') or img.get('data-src')
if src:
full_url = urljoin(self.base_url, src)
if self.is_valid_url(full_url):
image_urls.append(full_url)
return image_urls
从 HTML 中解析并提取所有有效图片 URL
-
用
BeautifulSoup解析 HTML,定位所有<img>标签(网页中图片的主要载体)。 -
从
<img>标签中提取图片地址:优先取src属性,若为空则取data-src(部分网页用data-src延迟加载图片)。 -
通过
urljoin处理相对路径(如../images/pic.jpg),结合base_url补全为完整 URL -
调用
is_valid_url过滤无效链接(如缺少协议或域名的 URL),确保后续下载可用。爬取流程
def crawl(self): print(f"开始爬取网页: {self.base_url}") print(f"图片将保存到: {self.download_folder}") print("-" * 50) html_content = self.get_page_content(self.base_url) if not html_content: print("程序退出") return image_urls = self.extract_image_urls(html_content) print(f"找到 {len(image_urls)} 个图片链接") target_images = [url for url in image_urls if self.is_image_file(url)] print(f"其中 {len(target_images)} 个是 JPEG/JPG/PNG 格式的图片")-
调用
extract_image_urls提取所有图片 URL,再通过is_image_file筛选出 JPG、PNG、JPEG 格式的有效图片(过滤非图片资源)结果
-
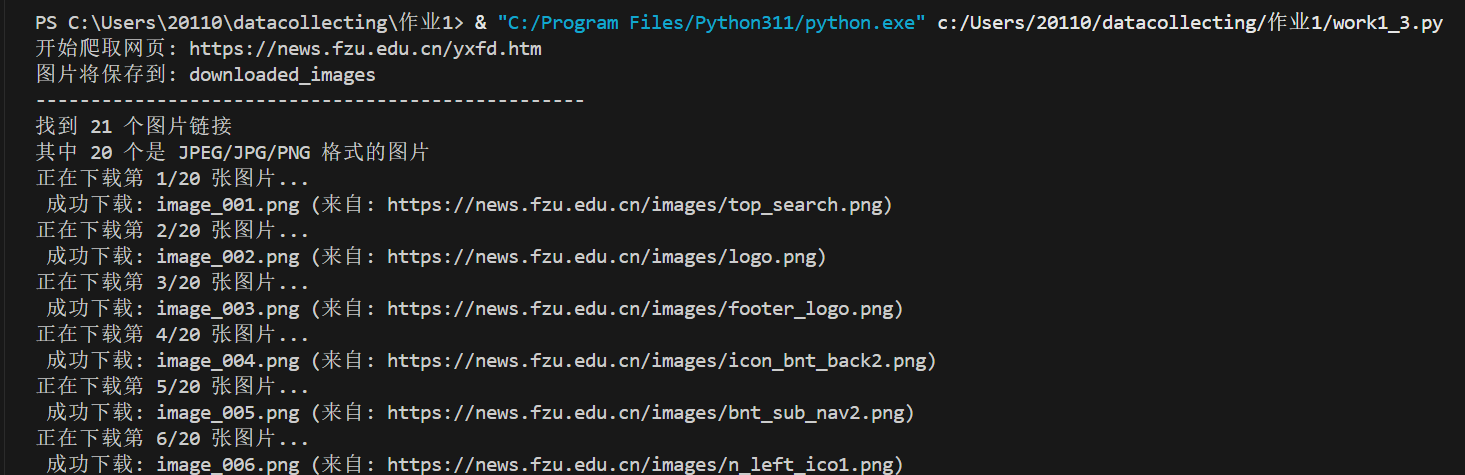
(2)心得体会
先装成浏览器发请求,网页里的图片地址有各种写法,相对路径、延迟加载的 data-src 等,都得处理明白。 用工具解析标签,再过滤出正经图片格式。下载的时候慢点,要限制速度。
地址:https://gitee.com/oozyt/datacollecting/tree/54af0e328aa48ed46ed0a8478fe5f78acd3af392

 浙公网安备 33010602011771号
浙公网安备 33010602011771号