

2,DRF-验证-ModelSerializer-APIView和View的区别-视图的封装-类的继承C3算法
2,DRF-验证-ModelSerializer-APIView和View的区别-视图的封装
使用DRF,序列化变的简单
DRF,第三天 1-48:00 django生命请求周期
单点登录:比如百度,登录百度帐号,旗下的产品都可以登录了,
本节封装代码: https://www.cnblogs.com/GGGG-XXXX/articles/9675911.html
目录-https://www.cnblogs.com/GGGG-XXXX/articles/9564651.html
项目目录-https://www.cnblogs.com/GGGG-XXXX/articles/9907408.html
/
视图的封装 -- 请求进来先走wsgiref模块 -- 中间件 -- url 跟我们CBV进行匹配 -- APIView重写封装了request -- request.data -- request.query_params -- _request
/
1.fields='__all__':也是不能序列化外键关系的,因此引入depth方法 2.对于分类(选择种类的字段)depth是不起作用的,需要自己写. 3.get_xxx 后面跟某些内容,是默认的钩子, 4.def get_publisher_info(self, obj): obj就是要序列化的book对象 APIView的源码分析 1.super的作用,不是单纯的继承父类的方法,加入o依次继承a,b,c,d,e,super(c,cls) 那就是跳过a,b类了, 2.在APIView里面用的request不是一开始wsgi封装的request,而是经过处理后的request 3.在APIView里面,_request才是老的request,而request是新封装的(Request类实例化的一个对象) 4.request.query_params 获取的是原来的request.GET的数据; 5.request.data 获取的是包括POST,PUT等其他的数据
/


from django.shortcuts import render from django.views import View from django.http import HttpResponse, JsonResponse from .models import Book, Publisher from django.core import serializers import json # Create your views here. def fbv(request): return HttpResponse("测试fbv") class CBVView(View): def get(self, request): return HttpResponse("测试CBV") def post(self, request): pass # book_list = [ # { # id: 1, # title: xx, # xxxx: xxx, # pulisher: {title: xxx}, # authors: [{},{}] # } # ] class BookView(View): # 第一版用。values # def get(self, request): # book_list = Book.objects.values("id", "title", "put_time", "category", "publisher") # # querset [{}, {}] # book_list = list(book_list) # # ret = json.dumps(book_list, ensure_ascii=False) # # return HttpResponse(ret) # # JsonResponse HttpResponse 区别 # # 做了序列化 json.dumps, 还帮助我们序列化了datetime # # book_obj.get_category_display() # for book in book_list: # publisher_obj = Publisher.objects.filter(id=book["publisher"]).first() # book["publisher"] = { # "id": publisher_obj.id, # "title": publisher_obj.title # } # return JsonResponse(book_list, safe=False, json_dumps_params={"ensure_ascii": False}) # 用django的serialize方法 外键依然不能够被序列化 取出来的依然是id def get(self, request): book_list = Book.objects.all() ret = serializers.serialize("json", book_list, ensure_ascii=False) return HttpResponse(ret)
/
# -*- coding: utf-8 -*- # __author__ = "maple" from rest_framework.views import APIView from rest_framework.response import Response from .models import Book from .serializers import BookSerializer from rest_framework.viewsets import ViewSetMixin, ModelViewSet # postman # 第一步 下载 pip install djangorestframework # 第二步 在settings注册一个app “rest_framework” # 序列化的第一步 声明一个序列化器 # 视图 # 把这个5个方法抽出来 # queryset serializer_class class GenericAPIView(APIView): # 帮助我们获得queryset serializer_class queryset = None serializer_class = None # 获取queryset def get_queryset(self): print(type(self.queryset)) print(type(self.queryset.all())) return self.queryset.all() # 获取序列化器 def get_serializer(self, *args, **kwargs): return self.serializer_class(*args, **kwargs) class ListModelMixin(object): # 我们的get方法 def list(self, request): queryset = self.get_queryset() ser_obj = self.get_serializer(queryset, many=True) return Response(ser_obj.data) class CreateModelMixin(object): # 我们的post方法 def create(self, request): ser_obj = self.get_serializer(data=request.data) if ser_obj.is_valid(): print(ser_obj.validated_data) ser_obj.save() return Response(ser_obj.validated_data) else: return Response(ser_obj.errors) class RetrieveModelMixin(object): def retrieve(self, request, id): book_obj = self.get_queryset().filter(id=id).first() ser_obj = self.get_serializer(book_obj) return Response(ser_obj.data) class UpdateModelMixin(object): def update(self, request, id): book_obj = self.get_queryset().filter(id=id).first() ser_obj = self.get_serializer(instance=book_obj, data=request.data, partial=True) if ser_obj.is_valid(): ser_obj.save() return Response(ser_obj.validated_data) else: return Response(ser_obj.errors) class DestroyModelMixin(object): def destroy(self, request, id): book_obj =self.get_queryset().filter(id=id).first() if book_obj: book_obj.delete() return Response("") else: return Response("删除对象不存在") class ListCreateModelMixin(GenericAPIView,ListModelMixin, CreateModelMixin): # 方便继承 什么也没做 pass class RetrieveUpdateDestroyModelMixin(GenericAPIView, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin): pass class BookAPIView(ListCreateModelMixin): # 执行as_view方法,然后进行了如下的操作, # 重新封装了request对象 用Request类进行封装 # request.query_params GET # request.data POST PUT # 旧的_request queryset = Book.objects.all() serializer_class = BookSerializer # def get(self, request): # # book_list = Book.objects.all() # queryset = self.get_queryset() # # ser_obj = BookSerializer(book_list, many=True) # ser_obj = self.get_serializer(queryset, many=True) # # return Response("DRF接口测试ok") # return Response(ser_obj.data) def get(self, request): return self.list(request) # def post(self, request): # book_obj = request.data # print(request.data) # ser_obj = BookSerializer(data=book_obj) # if ser_obj.is_valid(): # print(ser_obj.validated_data) # ser_obj.save() # return Response(ser_obj.validated_data) # else: # return Response(ser_obj.errors) def post(self, request): return self.create(request) class BookEditView(RetrieveUpdateDestroyModelMixin): queryset = Book.objects.all() serializer_class = BookSerializer # def get(self, request, id): # book_obj = Book.objects.filter(id=id).first() # ser_obj = BookSerializer(book_obj) # return Response(ser_obj.data) def get(self, request, id): return self.retrieve(request, id) # def patch(self, request, id): # book_obj = Book.objects.filter(id=id).first() # ser_obj = BookSerializer(instance=book_obj, data=request.data, partial=True) # if ser_obj.is_valid(): # ser_obj.save() # return Response(ser_obj.validated_data) # else: # return Response(ser_obj.errors) def patch(self, request, id): return self.update(request, id) # def delete(self, request, id): # book_obj = Book.objects.filter(id=id).first() # if book_obj: # book_obj.delete() # return Response("") # else: # return Response("删除对象不存在") def delete(self, request, id): return self.destroy(request, id) # class ModelViewSet(ViewSetMixin, ListCreateModelMixin, RetrieveUpdateDestroyModelMixin): # pass class BooksAPIView(ModelViewSet): queryset = Book.objects.all() serializer_class = BookSerializer
/
# -*- coding: utf-8 -*- # __author__ = "maple" from rest_framework import serializers from .models import Book class PublisherSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) class AuthorSerializer(serializers.Serializer): id = serializers.IntegerField() name = serializers.CharField(max_length=32) book_obj = { "title": "xxx", "category": 1, "publisher": 1, "authors": [1, 2] } def my_validate(value): print("my_validate") # 对敏感信息进行过滤 if "马化腾" in value.lower(): raise serializers.ValidationError("不能含有敏感词汇") else: return value # class BookSerializer(serializers.Serializer): # id = serializers.IntegerField(required=False) # title = serializers.CharField(max_length=32, validators=[my_validate]) # CHOICES = ((1, "Python"), (2, "Linux"), (3, "go")) # category = serializers.CharField(max_length=32, source="get_category_display", read_only=True) # post_category = serializers.ChoiceField(choices=CHOICES, write_only=True) # put_time = serializers.DateField() # # publisher = PublisherSerializer(read_only=True) # authors = AuthorSerializer(many=True, read_only=True) # # publisher_id = serializers.IntegerField(write_only=True) # author_list = serializers.ListField(write_only=True) # # def create(self, validated_data): # # 执行ORM的新增数据的操作 # book_obj = Book.objects.create(title=validated_data["title"], category=validated_data["post_category"], # put_time=validated_data["put_time"], publisher_id=validated_data["publisher_id"]) # book_obj.authors.add(*validated_data["author_list"]) # print(validated_data["author_list"]) # return book_obj # # def update(self, instance, validated_data): # # 有就更新没有就取默认的 # instance.title = validated_data.get("title", instance.title) # instance.category = validated_data.get("post_category", instance.category) # instance.put_time = validated_data.get("put_time", instance.put_time) # instance.publisher_id = validated_data.get("publisher_id", instance.publisher_id) # if validated_data.get("author_list"): # instance.authors.set(*validated_data["author_list"]) # instance.save() # return instance # # def validate_title(self, value): # print("validate_title") # if "python" not in value.lower(): # raise serializers.ValidationError("内容必须含有Python") # else: # return value # # def validate(self, attrs): # print("validate") # # attrs有我们所有的字段和数据字典 # # 要求title含有Python 并且 分类是1 # if "python" in attrs["title"].lower() and attrs["post_category"] == 1: # return attrs # else: # raise serializers.ValidationError("数据不合法请重新输入") class BookSerializer(serializers.ModelSerializer): category_dis= serializers.SerializerMethodField(read_only=True) publisher_info = serializers.SerializerMethodField(read_only=True) author_info = serializers.SerializerMethodField(read_only=True) def get_author_info(self, obj): # 通过obj拿到authors # 构建想要的数据结构返回 authors = obj.authors.all() ret = [] for author in authors: ret.append({ "id": author.id, "name": author.name }) return ret def get_category_dis(self, obj): return obj.get_category_display() def get_publisher_info(self, obj): # 序列化的Book对象 # 通过Book对象找到我们的publisher对象 # 就可以拿到我们想要的字段 # 拼接成自己想要的数据结构 ret = { "id": obj.publisher.id, "title": obj.publisher.title } return ret class Meta: model = Book # fields = ["id", "title", "put_time"] fields = "__all__" # 让你这些外键关系的字段变成read_only = True # depth = 1 extra_kwargs = {"category": {"write_only": True},"publisher": {"write_only": True}, "authors":{"write_only": True},"title": {"validators": [my_validate]}}
/
from django.db import models # Create your models here. __all__ = ["Book", "Publisher", "Author"] class Book(models.Model): title = models.CharField(max_length=32, verbose_name="图书的名字") CHOICES = ((1, "Python"), (2, "Linux"), (3, "go")) category = models.IntegerField(choices=CHOICES) put_time = models.DateField() publisher = models.ForeignKey(to="Publisher") authors = models.ManyToManyField(to="Author") def __str__(self): return self.title class Meta: db_table = "01-图书表" verbose_name_plural = db_table class Publisher(models.Model): title = models.CharField(max_length=32, verbose_name="出版社的名称") def __str__(self): return self.title class Meta: db_table = "02-出版社表" verbose_name_plural = db_table class Author(models.Model): name = models.CharField(max_length=32, verbose_name="作者的名字") def __str__(self): return self.name class Meta: db_table = "03-作者表" verbose_name_plural = db_table
/
"""DRFDemo URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/1.11/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.conf.urls import url, include 2. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls')) """ from django.conf.urls import url from django.contrib import admin from SerDemo.views import fbv, CBVView, BookView # from SerDemo.my_views import BookAPIView, BookEditView from SerDemo.my_views import BooksAPIView urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^test-fbv', fbv), url(r'^test-cbv', CBVView.as_view()), url(r'^books', BookView.as_view()), url(r'^api/books', BooksAPIView.as_view({"get": "list", "post": "create"})), url(r'^api/book/(?P<pk>\d+)', BooksAPIView.as_view({"get": "retrieve", "patch": "update", "delete": "destroy"})), ]
字段验证
1,自定义的字段验证
def my_validate(value): print("my_validate") # 对敏感信息进行过滤 if "马化腾" in value.lower(): raise serializers.ValidationError("不能含有敏感词汇") else: return value class BookSerializer(serializers.Serializer): id = serializers.IntegerField(required=False) title = serializers.CharField(max_length=32, validators=[my_validate])
2,单字段验证
单个字段的验证,验证title字段,联想form组件的局部钩子函数,进行字段的验证
def validate_title(self, value): print("validate_title") if "python" not in value.lower(): raise serializers.ValidationError("内容必须含有Python") else: return value
3,联合字段验证
def validate(self, attrs): print("validate") # attrs有我们所有的字段和数据字典 # 要求title含有Python 并且 分类是1 if "python" in attrs["title"].lower() and attrs["post_category"] == 1: return attrs else: raise serializers.ValidationError("数据不合法请重新输入")
三种验证方法的优先级是:自定义>单字段>联合字段
ModelSerializer-APIView和View的区别
注意:使用ModelSerializer时,添加或者局部更新数据,都不用写create或者update的方法了,已经内部给实现了.
使用ModelSerializer
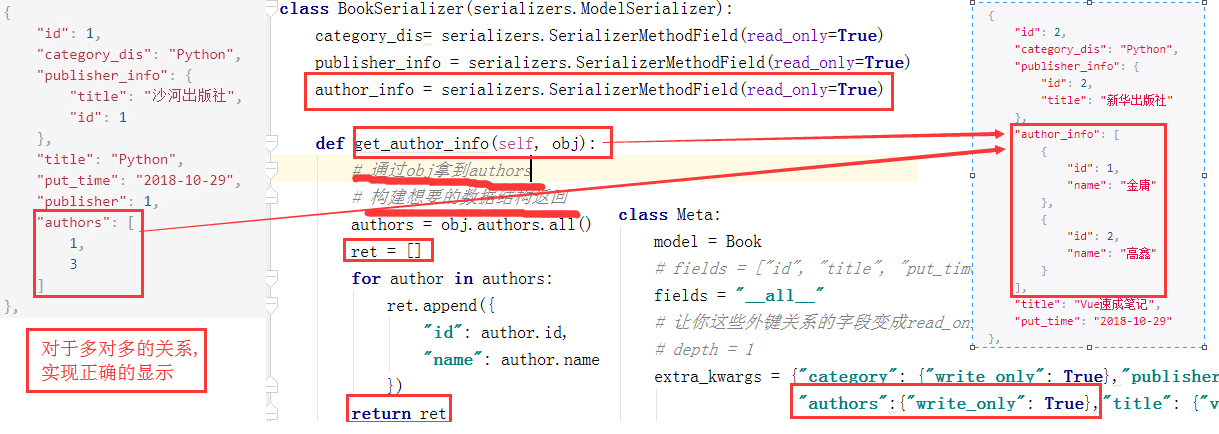
class BookSerializer(serializers.ModelSerializer): category_dis= serializers.SerializerMethodField(read_only=True) publisher_info = serializers.SerializerMethodField(read_only=True) author_info = serializers.SerializerMethodField(read_only=True) def get_author_info(self, obj): # 通过obj拿到authors # 构建想要的数据结构返回 authors = obj.authors.all() ret = [] for author in authors: ret.append({ "id": author.id, "name": author.name }) return ret
/
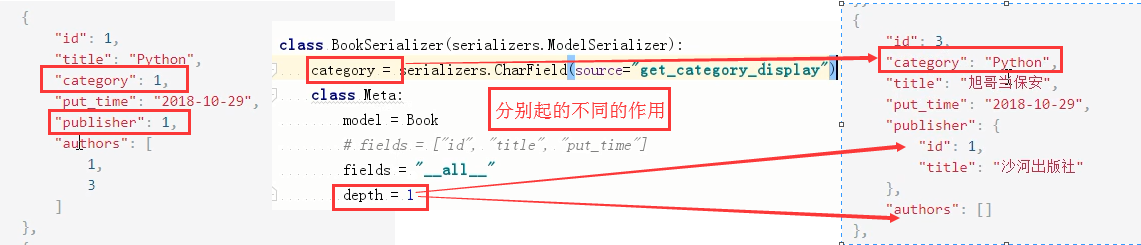
关于depth
表与表之间存在外键关系(可能),存在外键关系的表可能与别的表还存在外键关系,
depth=1,就表示只找一层,
depth=2,表示找2层,
还有,使用depth之后,会让字段都变成 readonly=True,所以不建议使用.还有可能会出现数据的冗余.
/
自定义方法,
对于显示的内容,做一个自定义,使用ModelSerializer之后,解决,category显示是数字而不是对于内容的问题,

/
多对多的显示
视图
类的继承,C3算法,
# 归并算法 class A:pass class B(A):pass class C(A):pass class D(B):pass class E(C):pass class F(D,E):pass # 第一步 先找出F类的父类的MRO # D [D,B,A,O] # E [E,C,A,O] # merge([D,B,A,O], [E,C,A,O], [D,E]) # 第一个表的表头 后面所有的表去掉表头部分不能含有这个D # FD merge([B,A,O], [E,C,A,O], [E]) # FDB merge([A,O], [E,C,A,O], [E]) # 不满足条件时 取二个表的表头,假如取不出来表头(([A,0],[O,A])),python是不允许相互继承的,没有意义,在写继承时就已经报错了, # FDBE merge([A,O], [C,A,O]) # FDBEC merge([A,O], [A,O]) # FDBECAO print(F.__mro__)
/
类的继承顺序,遵循C3算法,C3算法是一种归并算法,
python是不允许相互继承的,没有意义,如果取不出来表头,在写继承时就
已经报错了,
假如继承顺序,是CBEAO,
super继承时,把E放里面,就是找E之后的继承,
不一定是从C找B,
APIView
APIview是继承View的,基于原来的View进行的一些拓展,把csrf进行了豁免.
返回的view,执行父类的as_view方法了,
执行APIview的dispatch的方法,把django的wsgi封装的request给重做了,进行了赋值了
所以也就没有request.method,request.POST等等方法了,已经是新的request了,
源码分析-----------****************-----------------
执行as_view方法,然后进行了如下的操作,
重新封装了request对象 用Request类进行封装
request.query_params 对应之前的,request.GET
request.data 对应之前的,request.POST PUT
旧的_request
现在是增删改查都实现了,但是会出现代码的冗余,进行方法的合并等一些操作,
进行了类的封装,
/from rest_framework.viewsets import ViewSetMixin (路由可以传参了,)
ViewSetMixin重新写了as_views()的方法,拿到路由传参的参数,进行匹配,

/ModelViewSet
路由是拿pk来识别的,
使用ModelSerializer时,添加或者局部更新数据,都不用写create或者update
的方法了,已经内部给实现了,
/
/
///////////

 浙公网安备 33010602011771号
浙公网安备 33010602011771号