


Inoodb 存储引擎
Mysql存储引擎
1.查看数据库的锁竞争
a) 设置监视器:mysql> create table InnoDB_monitor(a INT) engine=InnoDB;
b) 查看:mysql> show engine InnoDB status;
c) 停止查看:mysql> drop table InnoDB_monitor;
d) 具体参考:InnoDB Monitor
https://blog.csdn.net/zyz511919766/article/details/50147283
2.锁(表级锁、页级锁、行级锁、意向锁)
a) 行锁(共享锁、排他锁)
i. 加锁条件
- 通过索引条件检索数据时,Innodb才使用行级锁,否则使用表级锁
- 行锁是对索引加的锁,不同记录使用相同的索引建会导致锁冲突
- 主键索引、唯一索引、普通索引都是是对数据加锁
- 是否使用索引由mysql的执行策略决定
ii. 隐式加锁
- InnoDB自动加意向锁。(对表和页添加同类型的意向锁)
- 对update、delete、insert自动加排他锁
- 对普通的select,InnoDB不会加锁
iii. 显式加锁
- 共享锁:select * from A lock in share model
- 排他锁:select * from A for update
- 间隙锁:select * from A where id > 300 for update
a) 范围索引时,InnoDB不仅会对符合条件的记录加锁,也会对id大于300(这些记录并不存在)的“间隙”加锁。
b)降低了并发,实现了幻读的隔离级别
iv.死锁情况:
- 当前事务需要对某条记录要依存关系,加共享锁后,如果需要对该条记录执行更新操作时会导致死锁,这个时候应该使用排他锁
v. 意向锁
- 兼容性
![]()
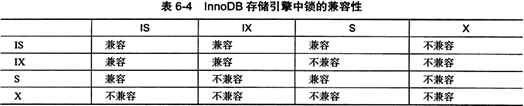
- 意向锁实现了InnoDB的表锁和行级锁的共存
b) 表锁(表共享读锁、表独占写锁)
i. 锁的兼容性
- 获取共享读锁后,阻塞对表的写操作
- 写操作会阻塞其他用户对同一表的读写操作
ii.隐式加锁(MyISAM用表锁,InnoDB执行计划不是索引走表锁)
- 普通的select语句对表加读锁
- Update、insert、delete对表加写锁
iii.显式加锁
- LOCK TABLE table_name WRITE/READ;
- InnoDB使用表锁示例:
SET AUTOCOMMIT=0;
LOCK TABLES t1 WRITE, t2 READ, ...;
[do something with tables t1 and t2 here];
COMMIT;
UNLOCK TABLES;
iv. 释放锁
- UNLOCK TABLES
v.注意点
- 同一个SQL session里,如果已经获取了一个表的锁定,则对没有锁的表不能进行任何操作,否则会报错。
vi.锁的优先级
- 写锁的优先级大于读锁,即使写请求后到
- 使用UPDATE LOW_PRIORITY article SET click_num=134 WHERE id = 823;降低写请求的优先级,降低数据库的查询响应时间
- 优先级调整方法
a) LOW_PRIORITY关键字应用于:DELETE、INSERT、LOAD DATA、REPLACE和UPDATE。
b) HIGH_PRIORITY关键字应用于:SELECT、INSERT语句。
c) delayed(延迟)关键字应用于:INSERT、REPLACE语句。
c) 页锁
d) 三种锁的优缺点:
i. 表锁实现简单,开销小,释放速度快,不易发生死锁。锁粒度大导致并发度低
ii. 行锁相反
e) InnoDB的死锁
i.如何发现死锁: 在InnoDB的事务管理和锁定机制中,有专门检测死锁的机制,会在系统中产生死锁之后的很短时间内就检测到该死锁的存在
ii.解决办法:
- 回滚代价较小(影响记录少的)的那个事务
- 在REPEATABLE-READ隔离级别下,如果两个线程同时对相同条件记录用SELECT…FOR UPDATE加排他锁,在没有符合该条件记录情况下,两个线程都会加锁成功。程序发现记录尚不存在,就试图插入一条新记录,如果两个线程都这么做,就会出现死锁。这种情况下,将隔离级别改成READ COMMITTED,就可避免问题。
iii.行级锁的使用建议
- 尽量使用索引查询以保障使用行锁的前提
- 减少事务的时间和粒度,提高效率
- 减少范围查询,避免间隙锁,影响并发
- 使用合理的事务隔离级别
iv.避免死锁的建议
- 尽量一次锁定事务需要操作的记录
- 如果并发性很高,可以提高锁级别避免死锁
- 顺序访问,避免死锁
3.事务
a) 事务的传播机制
i. PROPAGATION_REQUIRE:没有事务则创建,有则加之
ii. PROPAGATION_SUPPORT:有事务则加之,没有事务则非事务执行
iii. PROPAGATION_NEW_REQUIRE:无论是否有事务都创建一个事务
iv. PROPAGATION_NESTED:有则嵌套之,没有创建
v. PROPAGATION_NO_SUPPORE:没有则执行,有则挂起
vi. PROPAGATION_NEVER:没有则正常运行,有则抛出异常
vii. PROPAGATION_MANDATORY:有则加之,没有异常
b) 事务的特性(ACID)
i. Atomicity-原子性-事务要么成功,要么失败
ii. Consistency-一致性,执行事务后,从一个状态到另一个状态
iii. isolation-隔离性,事务的隔离级别
iv. durability-持久性-事务完成后,持久化的,不会丢失
c) InnoDB事务的隔离级别通过锁来实现,原子性和持久性通过redo日志实现,一致性通过undo日志实现
d) Redo日志(物理日志)
i. 记录页的物理修改操作
ii. 记录事务对数据的修改,先顺序写到redo log buffer,定期fsync刷盘到redo log file。把磁盘的随机写提高到顺序写
iii. 用于保障已经提交事务的持久性
e) Undo日志(逻辑日志)
i. 根据每行记录进行记录
ii. 用于rollback,逻辑的把数据库恢复到原来的样子,只恢复本事务的修改内容,不影响其他并发事务的修改内容。
iii. 保障未提交事务回滚时的恢复
f) MVCC支持读写并发
i. 在A事务写数据时,保存旧数据到undo为v0版本,
ii. A事务未提交之前,有读请求,读取的是v0版本的数据,快照读,提供并发
iii. A事务提交后,删除undo的旧版本数据
iv. Innodb的所有普通select都是快照读,快照读不加锁
v. 普通锁串行,读写锁读读并发,MVCC读写并发
4.索引
a) 内部数据结果是B+树,多叉树,对B树的扩展,对2-3树的扩张,对平衡二叉树的扩张
b) 根据索引键是否为主键可以分为:聚集索引和辅助索引
i. 聚集索引:
- 非叶子节点存放了索引的键值,用于索引,叶子节点用双向链表链接,存放了索引的数据页。
- 一个表只能有一个聚集索引
ii. 非聚集索引
- 与聚集索引存放结构相同,不同点在于,叶子节点存放的是主键的值,需要再利用聚集索引找到数据纪录
- 包括:唯一索引,普通索引,全文索引,hash索引,联合索引
iii.联合索引:
- 多个列组成的索引值
- 查询时,按照创建索引时的顺序查询才能使用索引
- 最左前缀索引
- 覆盖索引,叶子节点保存了主键值和联合索引的值,所以如果通过联合索引查询某一个联合索引列的值或者主键的值时只需要一次搜索

 浙公网安备 33010602011771号
浙公网安备 33010602011771号