
练习
1.复购率
SELECT
count( t.userid) 总共消费人数,
count(DISTINCT case when t.`消费次数`>1 then t.userid else null end) as 总共复购人数,
concat(round(count(DISTINCT case when t.`消费次数`>1 then t.userid else null end)/count(DISTINCT t.userid)*100,2),'%')as 复购率 FROM
(
select userid,
count(userid) as 消费次数
from order_info_utf
where ispaid = '已支付'
group by userid
) t

SELECT
count( b.userid) 总共消费人数,
count(DISTINCT case when b.`消费次数`>1 then b.userid else null end) as 总共复购人数,
concat(round(count(DISTINCT case when b.`消费次数`>1 then b.userid else null end)/count(DISTINCT b.userid)*100,2),'%')as 复购率 FROM
( select userid,count(日期) as 消费次数
from
(
select userid,date_format(paidtime,"%Y-%m-%d") as 日期
from order_info_utf
where ispaid = '已支付'
group by userid,日期
) t
group by userid
) b

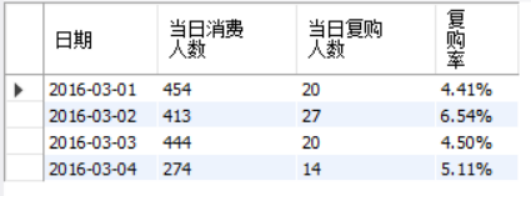
SELECT t.`日期`,count( t.userid) 当日消费人数,
count(DISTINCT case when t.`消费次数`>1 then t.userid else null end) as 当日复购人数,
concat(round(count(DISTINCT case when t.`消费次数`>1 then t.userid else null end)/count(DISTINCT t.userid)*100,2),'%')as 复购率 FROM
(
select userid,date_format(paidtime,"%Y-%m-%d") as 日期,
count(userid) as 消费次数
from order_info_utf
where ispaid = '已支付'
group by userid,日期
) t
group by t.日期
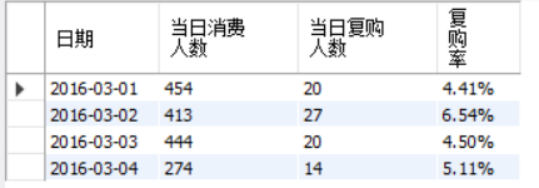
SELECT t.`日期`,count(distinct t.userid) 当日消费人数,
count(DISTINCT case when t.`消费次数`>1 then t.userid else null end) as 当日复购人数,
concat(round(count(DISTINCT case when t.`消费次数`>1 then t.userid else null end)/count(DISTINCT t.userid)*100,2),'%')as 复购率 FROM
(
select userid,date_format(paidtime,"%Y-%m-%d") as 日期,
count(orderid) as 消费次数
from order_info_utf
where ispaid = '已支付'
group by userid,日期
) t
group by t.日期
2.回购率
select date1,
count( userid) as 当天购买人数,
sum( case when 天数=1 then 1 else 0 end)as 次日购买人数,
sum( case when 天数=1 then 1 else 0 end)/count(DISTINCT userid) as 回购率
from
( select a.userid,a.date1 as date1,datediff(date2,date1) as 天数
from
( (
select date_format(paidtime,"%Y-%m-%d") as date1,userid
from order_info_utf
where ispaid = '已支付'
group by date_format(paidtime,"%Y-%m-%d"),userid
) a
left join
(
select date_format(paidtime,"%Y-%m-%d") as date2,userid
from order_info_utf
where ispaid = '已支付'
group by date_format(paidtime,"%Y-%m-%d"),userid
) b
on a.userid = b.userid
)
) d
group by d.date1
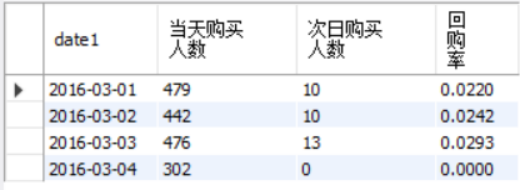
注意先去重再连接,比如用户1第一天购买100次,时间作差不要直接减会出错,使用datediff函数。
(2)python
import pandas as pd
df = pd.read_csv('order_info_utf.csv')
df['paidtime']=pd.to_datetime(df['paidtime'],format="%Y-%m-%d %H:%M:%S")
df['date']=df['paidtime'].dt.strftime('%Y-%m-%d').astype('datetime64[ns]')
#复购率
data=df.groupby(['userid','date'])['orderid'].count().reset_index()
s1=data.groupby('date')['userid'].count() #当日消费人数
s2=data[data['orderid']>1].groupby('date')['userid'].count()#当日复购人数
df_new=pd.concat([s1,s2],axis=1)
df_new.columns=['当日消费人数','当日多次消费人数']
df_new['复购率']=(df_new['当日多次消费人数']/df_new['当日消费人数']).apply(lambda x: format(x,'.2%')) #两位小数百分数
df_new

#回购率
df3=df
df3=df3.drop_duplicates(subset=['userid','date'])
df3=df3[['userid','date']]
order2=pd.merge(df3,df3,on='userid',how='left')
order2['diff']=order2['date_y']-order2['date_x']
order2['diff']=order2['diff'].dt.days
a=order2.groupby(['date_x'])['userid'].count() #当月消费人数
b=order2[order2['diff']==1].groupby(['date_x'])['userid'].count() #次月消费人数
data2=pd.concat([a,b],axis=1)
data2.columns=['当日购买人数','次日回购人数']
data2['回购率']=data2['次日回购人数']/data2['当日购买人数']
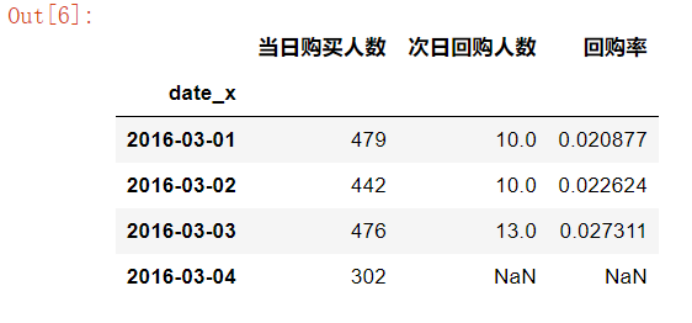
3.不同日期的下单数
(1)mysql
select date_format(paidtime,'%Y-%m-%d') as 日期,
count(distinct userid) as 下单人数,
count(userid) as 下单数
from order_info_utf
group by date_format(paidtime,'%Y-%m-%d')
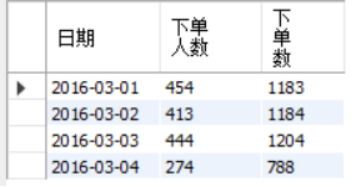
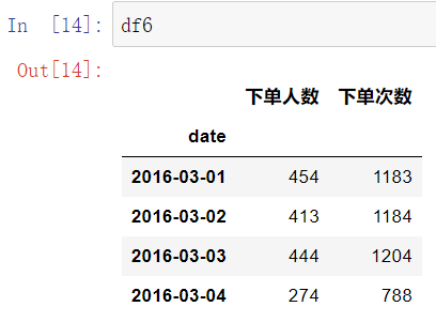
(2)python
df4=df
df6=df4.groupby(['date','userid']).count().reset_index().groupby('date').agg({'userid':'count','orderid':'sum'})
df6=df6.rename(columns={'userid':'下单人数','orderid':'下单次数'})
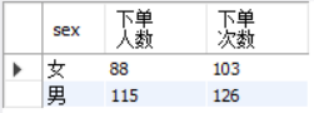
4.不同性别的下单数
select sex,count(distinct b.userid) as 下单人数,
count(b.userid) as 下单次数
from user_info a
join order_info_utf b
on a.userId = b.userid
group by sex
(2)python
order=df
user=pd.read_csv('user_info.csv')
df6=pd.merge(order,user,left_on='userid',right_on='userId',how='left')
df6=df6.groupby(['sex','userId']).count().reset_index().groupby('sex').agg({'userId':'count','orderid':'sum'})
df6=df6.rename(columns={'userId':'消费人数','orderid':'消费次数'})

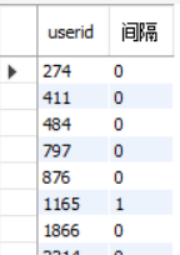
5.统计多次消费的用户,第一次和最后一次消费时间的间隔
select userid,
datediff(max(date_format(paidtime,'%Y-%m-%d')),min(date_format(paidtime,'%Y-%m-%d'))) as 间隔
from order_info_utf
where ispaid = '已支付'
group by userid
having count(orderid) > 1
order by userid
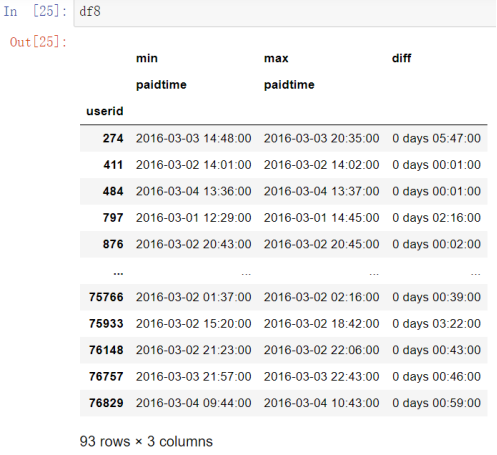
(2)python
df8=order.pivot_table(index='userid',values='paidtime',aggfunc=['min','max'])
df8['diff']=df8['max']-df8['min']
df8=df8[df8['diff']>'0 days 00:00:00']
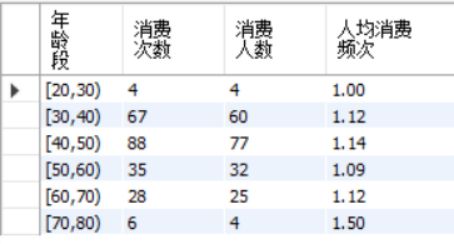
6.不同年龄段的消费频次
SELECT t.`年龄段`,COUNT(t.orderid) as 消费次数,
count(DISTINCT t.userid) as 消费人数,
round(COUNT(t.orderid)/count(DISTINCT t.userid),2) as 人均消费频次 from
(SELECT o.userid,o.orderid,
case
WHEN 2022-year(u.birth)<10 then '[0,10)'
WHEN 2022-year(u.birth)<20 then '[10,20)'
WHEN 2022-year(u.birth)<30 then '[20,30)'
WHEN 2022-year(u.birth)<40 then '[30,40)'
WHEN 2022-year(u.birth)<50 then '[40,50)'
WHEN 2022-year(u.birth)<60 then '[50,60)'
WHEN 2022-year(u.birth)<70 then '[60,70)'
WHEN 2022-year(u.birth)<80 then '[70,80)'
WHEN 2022-year(u.birth)<90 then '[80,90)'
else '90+'
end as 年龄段
from order_info_utf o
LEFT JOIN user_info u
on o.userid=u.userid
where o.ispaid='已支付' and year(u.birth)>1900) t
GROUP BY t.`年龄段`
(2)python
us=pd.read_csv('user_info.csv')
us['birth']=pd.to_datetime(us['birth'],format="%Y-%m-%d")
us['birth']=us['birth'].dt.strftime('%Y-%m-%d').astype('datetime64[ns]')
us['birth']=us['birth'].dt.year
from datetime import datetime
us['age']=datetime(2022,8,30).year-us['birth']
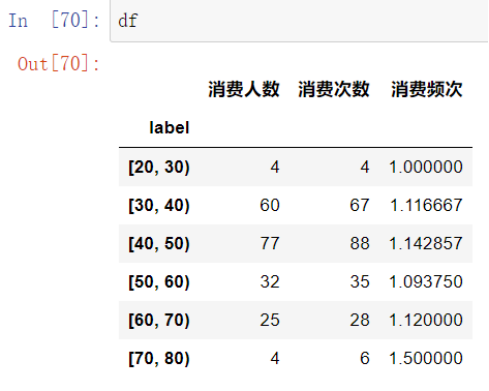
us['label']=pd.cut(us['age'],bins=[0,10,20,30,40,50,60,70,80,90,150],right=False).astype(str)#要把category转换成str类型,才能groupby
#表连接
df=pd.merge(order,us,left_on='userid',right_on='userId',how='left').dropna() #删除缺失值所在行
#数据分组求解
df=df[['userid','orderid','label']]
df=df.groupby(['label','userid']).count().reset_index().groupby('label').agg({'userid':'count','orderid':'sum'})
df=df.rename(columns={'userid':'消费人数','orderid':'消费次数'})
df['消费频次']=df['消费次数']/df['消费人数']
7.消费金额前20%的用户,贡献了多少额度
SELECT * FROM
(SELECT userid,round(sum(price),2) as 'sum',
row_number() over (order by sum(price) desc) as 'ranking'
from order_info_utf
where ispaid='已支付'
GROUP BY userid) t
对每位用户的消费金额进行排名
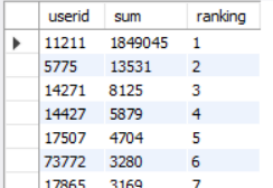
选出前20%的用户
SELECT sum(t.sum) FROM
(SELECT userid,round(sum(price),2) as 'sum',
row_number() over (order by sum(price) desc) as 'ranking'
from order_info_utf
where ispaid='已支付'
GROUP BY userid) t
#where t.ranking<(SELECT 0.2*count(DISTINCT userid) from order_info_utf
#where ispaid='已支付')
;
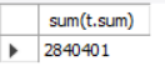
(2)python
#计算每个用户的消费金额
df=order.groupby('userid')['price'].sum().reset_index()
#计算贡献排在前20%的分位数
data=df['price'].quantile(0.8,interpolation='nearest') #分位数为1314
#筛选出前20%贡献数据,并计算求和
df=df[df['price']>=data]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号