
考试分数(二、三)
1.牛客每次考试完,都会有一个成绩表(grade),如下:
|
id |
job |
score |
|
1 |
C++ |
11001 |
|
2 |
C++ |
10000 |
|
3 |
C++ |
9000 |
|
4 |
Java |
12000 |
|
5 |
Java |
13000 |
|
6 |
JS |
12000 |
|
7 |
JS |
11000 |
|
8 |
JS |
9999 |
|
9 |
Java |
12500 |
第1行表示用户id为1的用户选择了C++岗位并且考了11001分
。。。
第8行表示用户id为8的用户选择了前端岗位并且考了9999分
请你写一个sql语句查询用户分数大于其所在工作(job)分数的平均分的所有grade的属性,并且以id的升序排序,如下:
|
id |
job |
score |
|
1 |
C++ |
11001 |
|
5 |
Java |
13000 |
|
6 |
JS |
12000 |
|
7 |
JS |
11000 |
(注意: sqlite 1/2得到的不是0.5,得到的是0,只有1*1.0/2才会得到0.5,sqlite四舍五入的函数为round)
我的方法:
select *
from grade t1
where score >(select avg(score) from grade where job = t1.job)
group by id
方法一:子查询将t1,t2表进行关联
select id,job, score
from `grade` t1
where score >
(select avg(score) from `grade` t2 where t1.job = t2.job)
order by 1 ;
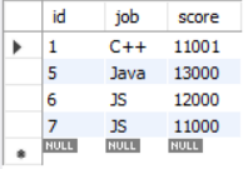
方法二:表连接
select id, t1.job, score
from `grade` t1
left join
(select job,avg(score)av from `grade` group by 1)t2
on t1.job = t2.job
where t1.score > t2.av
order by 1 ;
方法三:窗口函数
select id, job, score
from
(select id,job,score,
avg(score)over(partition by job)av
from `grade`
)t1
where score > av
order by 1 ;
经典错误:
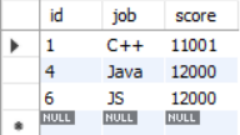
select * from grade
group by job
having score>avg(score)
order by id asc;
使用group by进行分组结果变成了三条
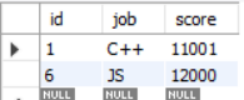
然后再使用score>avg(score)筛选,结果变成了
题目二:牛客每次举办企业笔试的时候,企业一般都会有不同的语言岗位,比如C++工程师,JAVA工程师,Python工程师,每个用户笔试完有不同的分数,现在有一个分数(grade)表简化如下:
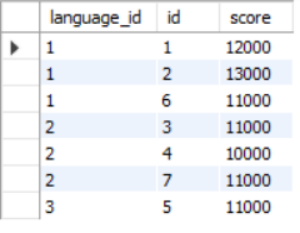
| id | language_id | score |
| 1 | 1 | 12000 |
| 2 | 1 | 13000 |
| 3 | 2 | 11000 |
| 4 | 2 | 10000 |
| 5 | 3 | 11000 |
| 6 | 1 | 11000 |
| 7 | 2 | 11000 |
....
第7行表示用户id为7的选择了language_id为2岗位的最后考试完的分数为11000,
不同的语言岗位(language)表简化如下:
| id | name |
| 1 | C++ |
| 2 | JAVA |
| 3 | Python |
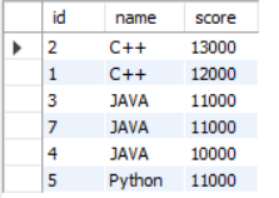
请你找出每个岗位分数排名前2名的用户,得到的结果先按照language的name升序排序,再按照积分降序排序,最后按照grade的id升序排序,得到结果如下:
| id | name | score |
| 2 | C++ | 13000 |
| 1 | C++ | 12000 |
| 3 | JAVA | 11000 |
| 7 | JAVA | 11000 |
| 4 | JAVA | 10000 |
| 5 | Python | 11000 |
我的思路:
select id,name,score from
(select grade.id,name,score,
dense_rank()over(partition by name order by score desc)ranking
from grade,language
where grade.language_id = language.id
)t
where ranking <=2
错误:窗口函数加了id排序出错,因为只用score函数认为score为11000和11000的排名相同,如果加上name,id,只有name,id,score相同的函数才会认为是排名一样,所以下面方法错误,结果输出不完整。
select id,name,score from
(select grade.id,name,score,
dense_rank()over(partition by name order by score desc,grade.id)ranking
from grade,language
where grade.language_id = language.id
)t
where ranking <=2

方法二:自连接
单纯自连接:有可能存在同分的情况所以要用<=,并且不是输出所有岗位的,而是要分岗位输出,要分组,故要用g1.language_id=g2.language_id.
SELECT g1.language_id,g1.id,g1.score
FROM grade AS g1, grade AS g2
WHERE g1.score<=g2.score
AND g1.language_id=g2.language_id
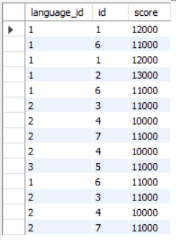
加了group by 之后
SELECT g1.language_id,g1.id,g1.score
FROM grade AS g1, grade AS g2
WHERE g1.score<=g2.score
AND g1.language_id=g2.language_id
GROUP BY g1.language_id,g1.id
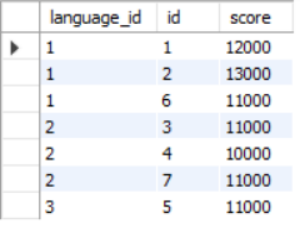
加了having之后
SELECT g1.language_id,g1.id,g1.score
FROM grade AS g1, grade AS g2
WHERE g1.score<=g2.score
AND g1.language_id=g2.language_id
GROUP BY g1.language_id,g1.id
HAVING COUNT(DISTINCT g2.score)<=2
综合语句如下:
SELECT a.id,name,score
FROM (
SELECT g1.language_id,g1.id,g1.score
FROM grade AS g1, grade AS g2
WHERE g1.score<=g2.score
AND g1.language_id=g2.language_id
GROUP BY g1.language_id,g1.id
HAVING COUNT(DISTINCT g2.score)<=2)AS a
INNER JOIN language
ON a.language_id=language.id
ORDER BY name,score DESC,a.id
结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号