



数据治理和hadoop简介
1.数据治理
企业数据治理的重点与难点就是在于如何落地。数据治理不仅仅是一个技术问题,而是一个复杂的、系统性的管理问题!
数据治理是一个宽泛的概念,只要有数据的地方,就会存在数据治理的问题,由于历史原因,我们已经上了一个又一个的系统,我们可以选择从源头介入来进行治理,但这样的难度非常大,成本非常高,周期长而风险高,考虑到需要各系统的高度配合,基本上是一个不可能完成的任务。
数据治理的原因:
· 数据是企业的资产,是最大的价值来源,同时也是最大的风险来源;
· 数据不规则、不完整、质量差是企业信息化中普遍存在的问题,在多业务系统运行时,问题愈发严重,严重制约系统的集成与数据的集成;
· 成功实施数据治理可以使企业的数据质量得到全方位的提升,使与数据相关的业务流程得到深度再造;
· 由于数据治理的提升,可以更好的提高业务系统的应用价值,为决策提供高质量的数据支持;
· 数据治理可以降低IT建设和运维的成本。
数据治理框架:
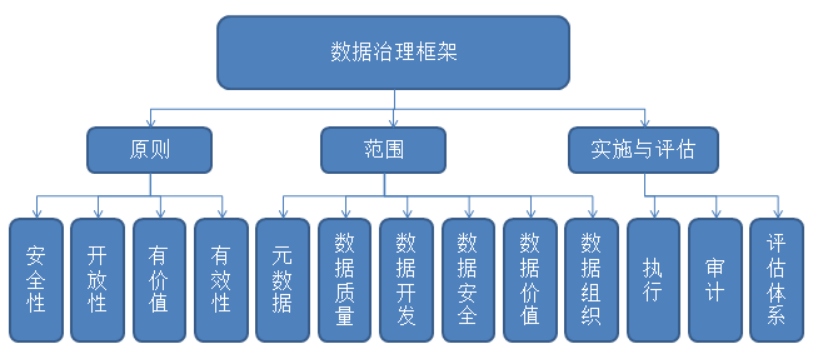
数据治理项目的范围
数据治理项目的范围通常都会包含:组织建设、数据安全、数据开发、数据质量、元数据管理、数据价值等几个模块。当然基于每家公司的数据治理的目标不一样,每家公司的数据治理实施关键路径也会不一样。如果公司数据治理的目标是为方便业务快速掌握了解数据、公开透明数据资产的动态,那么就把数据价值、元数据管理、数据质量做为实施关键路径。
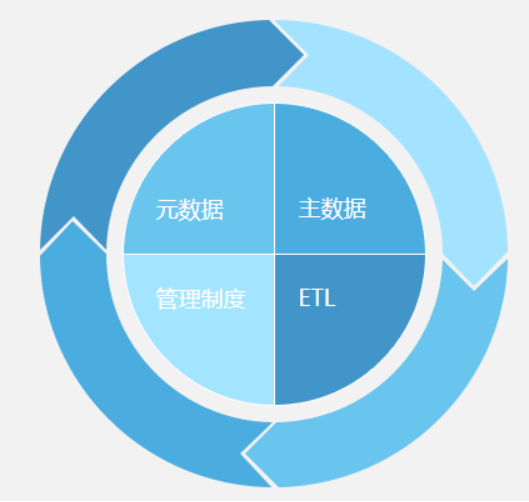
主数据管理(MDM)
主数据在多业务系统的情况下,是一个非常突出的问题。可以毫不夸张的说,进行主数据管理就好像给各业务系统进行外科手术一样,弄的不好,就会劳身伤财,元气大伤。
元数据管理
元数据即关于数据的数据,用以描述数据及其环境的结构化信息,便于查找、理解、使用和管理数据。与人类社会网络相似,元数据构建的就是数据的网络。有了它,就可以实现智能的报表间钻取;有了它,就可以追踪任意报表、指标的计算逻辑与取数来源,进行血缘分析。有了元数据这张网络,使得数据治理变得经脉畅通。
元数据从数据的角度可以分为三类:业务元数据、技术元数据和管理元数据。
- 业务元数据是从业务的视角去描述数据,让不懂数据的人可以快速读懂数据,例如:表名称、表的血缘关系、表的字段说明、指标的统计口径等多种业务描述;
- 技术元数据自然就是从技术的角度去描述数据,例如:表的sql、字段长度、字段类型等多种技术描述;
- 管理元数据是包含数据管理的信息在里面,例如:表的业务属主、表的技术负责人。
元数据的管理通常包含:血缘分析、数据生命周期。
血缘分析:对元数据的上下游进行分析,我的公司按照数据存储的数据库将血缘分析分为了两类:
1.存在Hadoop平台的血缘分析,可用通过脚本解析出到字段级的上下游关系;
2.建表有主外键的,可通过主外键建立血缘关系。
数据生命周期:数据都存在生命周期,当元数据访问量变低,数据价值不存在的时候,可将它下线清除,释放存储空间。
ETL
打通主数据、构建数据仓库,都需要一个工具去落地,这个工具就是ETL工具。(如奥威ETL工具,可以快速完成复杂的数据仓库构建)。
2.Hadoop概述
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。主要解决海量数据的存储以及海量数据的分析计算,Hadoop核心概念是HDFS(分布式存储),以及MapReduce。通俗来将就是,当一个海量数据,如果你使用传统方法去处理,比如10TB的数据,那么数据库就不太够用,并且即使数据库够用,那么在有限的资源(也就是CPU、内存)中处理的数据量是极少 的,10TB数据可能需要运作很久,那么有了Hadoop,HDFS是分布式存储文件系统,它将10TB数据分块存储在不同服务器(节点)中,然后在每个服务器中处理相应文件,也就是相当于n个服务器并行处理,并且每个服务器都不需要太高的配置。而这些处理的任务是由MapReduce分配的。
什么是并行:
传统处理方法,假如要写10000个字,你一个人写字速度为一分钟100个,那么就需要100分钟才能写完。
而采用并行处理,相当于有100同学一起写,并且分工明确,那么只需要一分钟,你们100个人就能写10000个字。
Hadoop能干什么
大数据存储:分布式存储
日志处理:擅长日志分析
ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
机器学习: 比如Apache Mahout项目
搜索引擎:Hadoop + lucene实现
数据挖掘:目前比较流行的广告推荐,个性化广告推荐
Hadoop是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
Hadoop优点
1.高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖 。
2.高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3.高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快 。
4.高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配 。
5.低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低 。
Hadoop架构
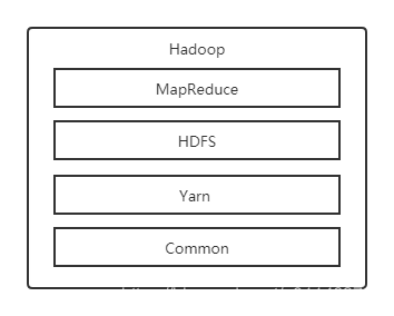
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。MapReduce是一个分布式计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
总之,Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
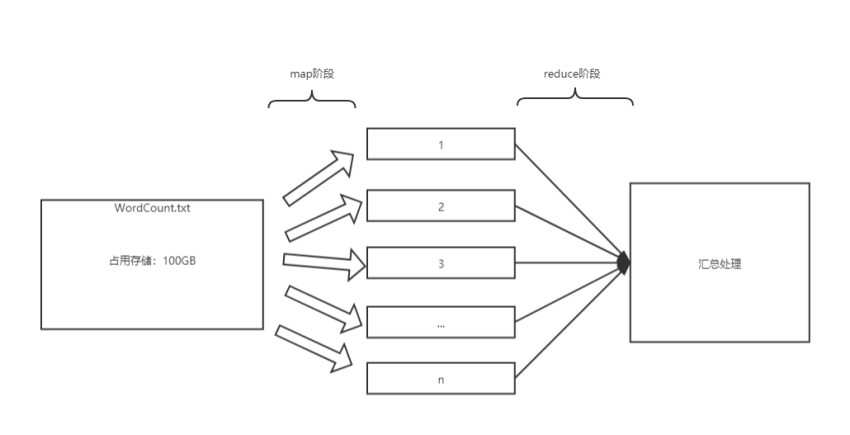
分布式计算:MapReduce架构
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
参考:
https://blog.csdn.net/u011463794/article/details/106019055
https://blog.csdn.net/qq_32649581/article/details/82892861


 浙公网安备 33010602011771号
浙公网安备 33010602011771号