
RFM(二):python实战
一、数据预处理
首先浏览数据大致情况:
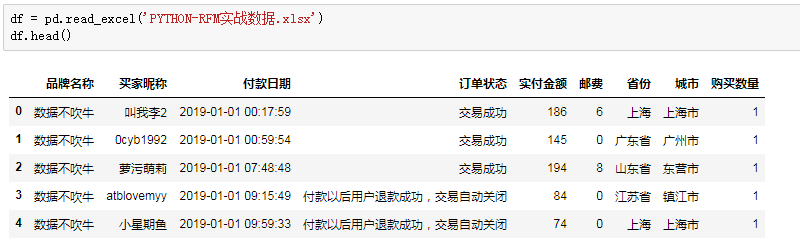
对于交易失败,可以理解为缺失值;对于同一天内,多次交易的,视为重复值,保留最近的作为rencency。
查看订单状态的分类:

查看数据类型和缺失情况:
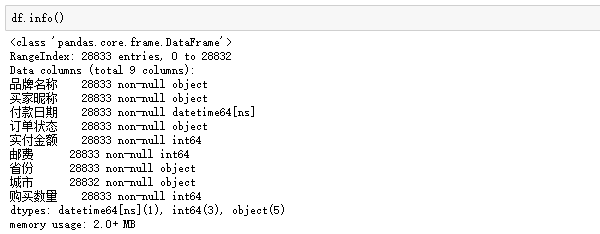
没有缺失值,一共28833条数据。
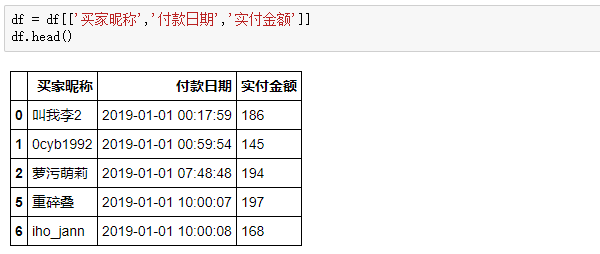
删除退款数据:

特征提取:RFM模型只需要买家昵称,付款时间和实付金额这3个关键字段
2.指标构造
关键在于构建模型所需的三个字段:R(最近一次购买距今多少天),F(购买了多少次)以及M(平均或者累计购买金额)
首先是R值:
要拿到所有用户最近一次付款时间,只需要按买家昵称分组,再选取付款日期的最大值即可

用今天减去每位用户最近一次付款时间,就得到R值了,这里我们把“2019-7-1”当作“今天”:

其次是F值:
依照“买家昵称”和“日期标签”进行分组,把每个用户一天内的多次下单行为合并,再统计购买次数:

最后是M值:
用总金额除以购买频次,就能得到用户平均支付金额:
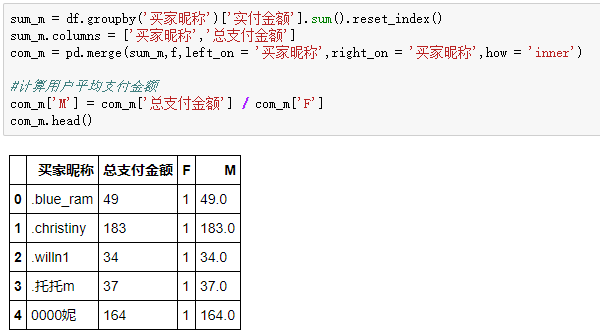
R,F,M合并:
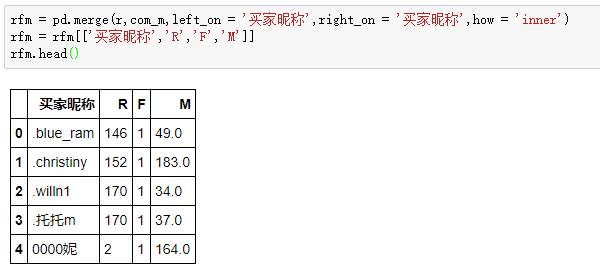
3.评分模型
-
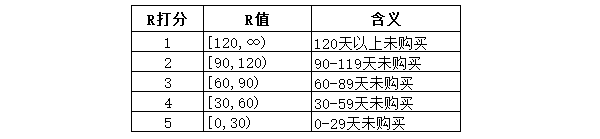
以R值为例,R代表了用户有多少天没来下单,这个值越大,用户流失的可能性越大,我们当然不希望用户流失,所以R越大,分值越小。
-
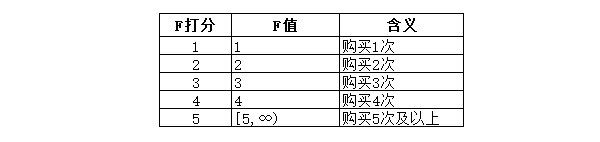
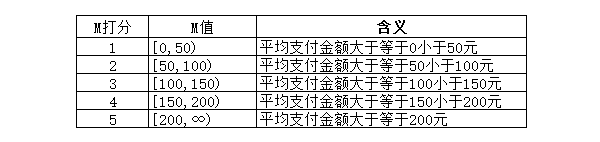
F值代表了用户购买频次,M值则是用户平均支付金额,这两个指标是越大越好,即数值越大,得分越高。
RFM模型中打分一般采取5分制,有两种比较常见的方式,一种是按照数据的分位数来打分,另一种是依据数据和业务的理解,进行分值的划分。
这里设置如下:
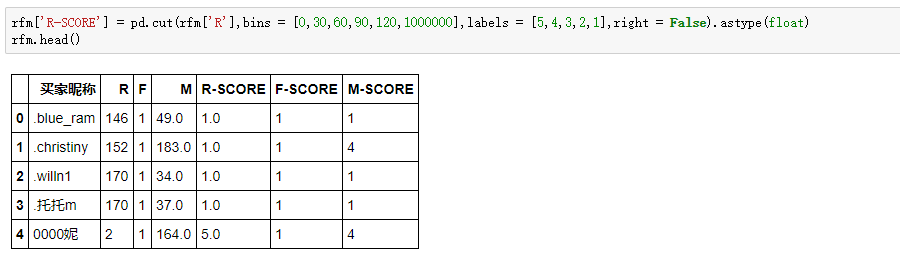
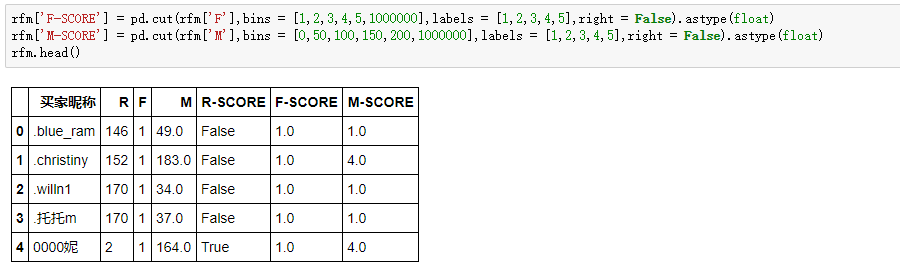
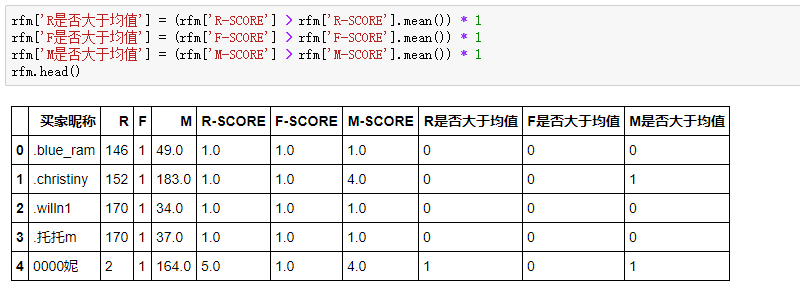
现在R-SCORE、F-SCORE、M-SCORE在1-5几个数之间,如果把3个值进行组合,像111,112,113...这样可以组合出125种结果,过多的分类和不分类本质是一样的。所以,我们通过判断每个客户的R、F、M值是否大于平均值,来简化分类结果。使得R、F、M,只有0和1(0表示小于平均值,1表示大于平均值)两种结果,最终有8种结果。
客户分层:
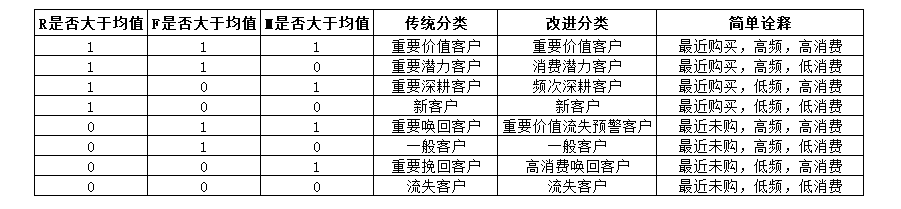
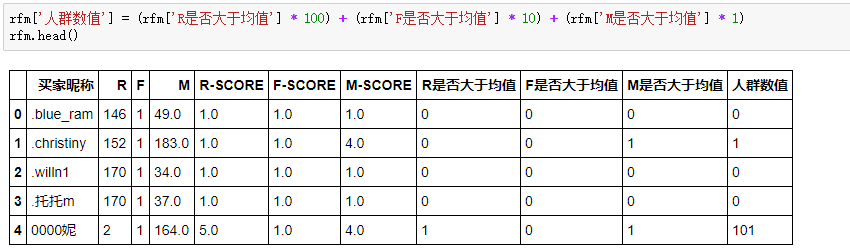
人群数值是数值类型,所以位于前面的0就自动略过,比如1代表着“001”的高消费唤回客户人群,10对应着“010”的一般客户。
为了得到最终人群标签,再定义一个判断函数,通过判断人群数值的值,来返回对应的分类标签:
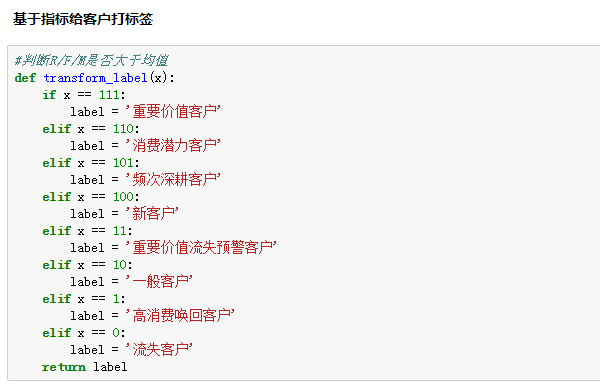
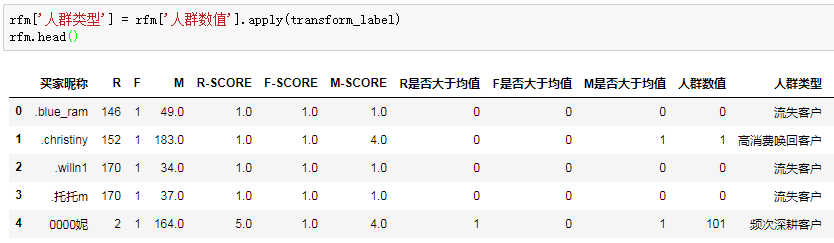
RFM模型建模的结束,每一位客户都有了属于自己的RFM标签。
4.结果分析
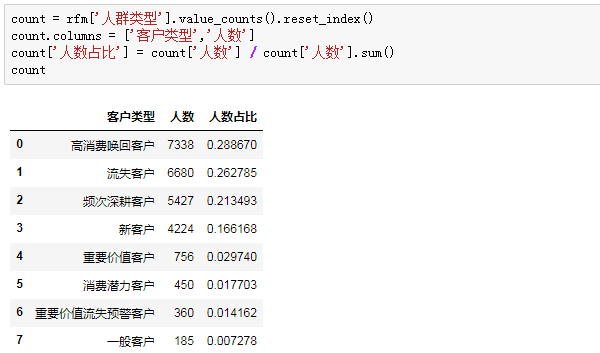
查看各类用户占比情况:
不同类型客户消费金额贡献占比:
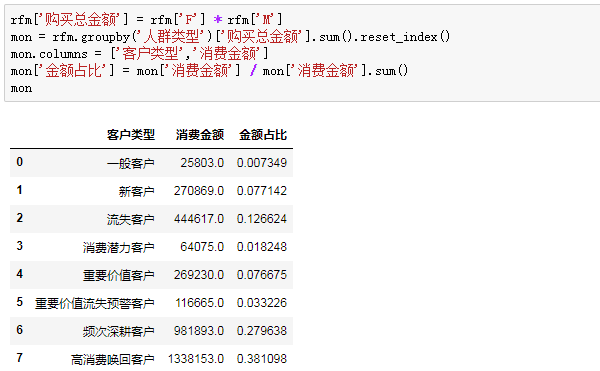
5.可视化分析
result = pd.merge(count,mon,left_on = '客户类型',right_on = '客户类型')
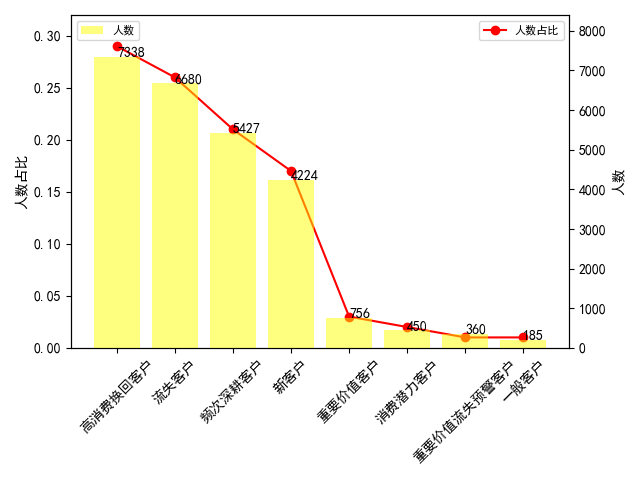
从上面结果,我们可以快速得到一些推断:
-
客户流失情况严峻,高消费唤回客户、流失客户占比超过50%,怎么样制定针对性唤回策略迫在眉睫。
-
重要价值客户占比仅2.97%,还有三个客户占比甚至不足2%,我们模型打分可能不够科学,可以进一步调整打分区间进行优化。
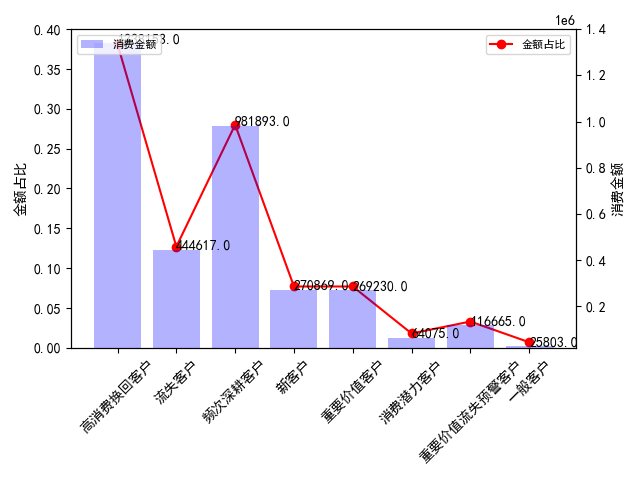
再结合金额进行分析:
高消费唤回客户人数占比28.87%,金额占比上升到了38.11%,这部分客户是消费的中流砥柱,他们为什么流失,应结合订单和购买行为数据进一步展开挖掘。
频次深耕客户金额占比紧随其后,这部分客户的特征是近期有消费、消费频次低、消费金额高,和高消费唤回客户仅有购买时间上的不同,如何避免这部分客户向高消费唤回客户的流转是我们要思考的主要命题。
流失客户人数占比26.28%,金额占比仅12.66%,这部分客户中有多少是褥羊毛用户,有多少是目标用户,对我们引流策略能够进行怎么样的指导和调整?
参考:
数据处理:https://blog.csdn.net/SeizeeveryDay/article/details/102735628
可视化:https://blog.csdn.net/leige_smart/article/details/79583470
横坐标重叠解决:https://blog.csdn.net/weixin_39527163/article/details/111424970
附录:
#参考:https://blog.csdn.net/SeizeeveryDay/article/details/102735628
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel('RFM.xlsx')
df['订单状态'].unique()
#Out[4]: array(['交易成功', '付款以后用户退款成功,交易自动关闭'], dtype=object)
df.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 28833 entries, 0 to 28832
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 品牌名称 28833 non-null object
1 买家昵称 28833 non-null object
2 付款日期 28833 non-null datetime64[ns]
3 订单状态 28833 non-null object
4 实付金额 28833 non-null int64
5 邮费 28833 non-null int64
6 省份 28833 non-null object
7 城市 28832 non-null object
8 购买数量 28833 non-null int64
dtypes: datetime64[ns](1), int64(3), object(5)
memory usage: 2.0+ MB
'''
df = df.loc[df['订单状态']=='交易成功',:]
print(len(df))
#27793
df = df[['买家昵称','付款日期','实付金额']]
'''
print(df.head())
买家昵称 付款日期 实付金额
0 叫我李2 2019-01-01 00:17:59 186
1 0cyb1992 2019-01-01 00:59:54 145
2 萝污萌莉 2019-01-01 07:48:48 194
5 重碎叠 2019-01-01 10:00:07 197
6 iho_jann 2019-01-01 10:00:08 168
'''
r = df.groupby('买家昵称')['付款日期']
r = r.max().reset_index()
'''
print(r.head())
买家昵称 付款日期
0 .blue_ram 2019-02-04 17:49:34.000
1 .christiny 2019-01-29 14:17:15.000
2 .willn1 2019-01-11 03:46:18.000
3 .托托m 2019-01-11 02:26:33.000
4 0000妮 2019-06-28 16:53:26.458
'''
print(len(r))
#25420
r['R']=(pd.to_datetime('2019-7-1')-r['付款日期']).dt.days
r = r[['买家昵称','R']]
'''
print(r.head())
买家昵称 R
0 .blue_ram 146
1 .christiny 152
2 .willn1 170
3 .托托m 170
4 0000妮 2
'''
df['日期标签'] = df['付款日期'].astype(str).str[:10]
dup_f = df.groupby(['买家昵称','日期标签'])['付款日期']
dup_f = dup_f.count().reset_index()
f = dup_f.groupby('买家昵称')['付款日期'].count().reset_index()
f.columns = ['买家昵称','F']
sum_m = df.groupby('买家昵称')['实付金额'].sum().reset_index()
sum_m.columns = ['买家昵称','总支付金额']
com_m = pd.merge(sum_m,f,left_on = '买家昵称',right_on='买家昵称',how='inner')
com_m['M'] = com_m['总支付金额'] / com_m['F']
'''
print(com_m.head())
买家昵称 总支付金额 F M
0 .blue_ram 49 1 49.0
1 .christiny 183 1 183.0
2 .willn1 34 1 34.0
3 .托托m 37 1 37.0
4 0000妮 164 1 164.0
'''
frm = pd.merge_ordered(r,com_m,left_on='买家昵称',right_on='买家昵称',how='inner')
rfm = frm[['买家昵称','R','F','M']]
'''
print(frm.head())
买家昵称 R 总支付金额 F M
0 .blue_ram 146 49 1 49.0
1 .christiny 152 183 1 183.0
2 .willn1 170 34 1 34.0
3 .托托m 170 37 1 37.0
4 0000妮 2 164 1 164.0
'''
rfm['R-SCORE'] = pd.cut(rfm['R'],bins = [0,30,60,90,120,1000000],labels=[5,4,3,2,1],right = False).astype(float)
'''
print(rfm.head())
买家昵称 R F M R-SCORE
0 .blue_ram 146 1 49.0 1.0
1 .christiny 152 1 183.0 1.0
2 .willn1 170 1 34.0 1.0
3 .托托m 170 1 37.0 1.0
4 0000妮 2 1 164.0 5.0
'''
rfm['F-SCORE'] = pd.cut(rfm['F'],bins = [1,2,3,4,5,1000000],labels=[1,2,3,4,5],right = False).astype(float)
rfm['M-SCORE'] = pd.cut(rfm['M'],bins = [0,50,100,150,200,1000000],labels=[1,2,3,4,5],right = False).astype(float)
'''
print(rfm.head())
买家昵称 R F M R-SCORE F-SCORE M-SCORE
0 .blue_ram 146 1 49.0 1.0 1.0 1.0
1 .christiny 152 1 183.0 1.0 1.0 4.0
2 .willn1 170 1 34.0 1.0 1.0 1.0
3 .托托m 170 1 37.0 1.0 1.0 1.0
4 0000妮 2 1 164.0 5.0 1.0 4.0
'''
rfm['R是否大于均值'] = (rfm['R-SCORE'] > rfm['R-SCORE'].mean())*1
rfm['F是否大于均值'] = (rfm['F-SCORE'] > rfm['F-SCORE'].mean())*1
rfm['M是否大于均值'] = (rfm['M-SCORE'] > rfm['M-SCORE'].mean())*1
rfm['人群数值'] = (rfm['R是否大于均值']*100)+(rfm['F是否大于均值']*10)+(rfm['M是否大于均值']*1)
def transform_label(x):
if x == 111:
label = '重要价值客户'
elif x == 110:
label = '消费潜力客户'
elif x == 101:
label = '频次深耕客户'
elif x == 100:
label = '新客户'
elif x == 11:
label = '重要价值流失预警客户'
elif x == 10:
label = '一般客户'
elif x == 111:
label = '重要价值客户'
elif x == 1:
label = '高消费换回客户'
elif x == 0:
label = '流失客户'
return label
rfm['人群类型'] = rfm['人群数值'].apply(transform_label)
count = rfm['人群类型'].value_counts().reset_index()
count.columns = ['客户类型','人数']
count['人数占比'] = count['人数'] / count['人数'].sum()
rfm['购买总金额'] = rfm['F'] * rfm['M']
mon = rfm.groupby('人群类型')['购买总金额'].sum().reset_index()
mon.columns = ['客户类型','消费金额']
mon['金额占比'] = mon['消费金额'] / mon['消费金额'].sum()
result = pd.merge(count,mon,left_on = '客户类型',right_on = '客户类型')
#plt.rcParams['font.family'] = 'SimSun' #不加这句无法显示中文
#python 画柱状图折线图
#可视化1
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
a=result['人数'] #数据
b=result['人数占比']
#把b中数字保留两位小数
c = []
for i in b:
c.append(round(i,2))
b=c
l=[i for i in range(8)]
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
fmt="%.2f"
yticks = mtick.FormatStrFormatter(fmt) #设置百分比形式的坐标轴
lx=[u'高消费换回客户',u'流失客户',u'频次深耕客户',u'新客户',u'重要价值客户',u'消费潜力客户',u'重要价值流失预警客户',u'一般客户']
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.plot(l, b,'or-',label=u'人数占比');
ax1.yaxis.set_major_formatter(yticks)
#for i,(_x,_y) in enumerate(zip(l,b)):
# plt.text(_x,_y,b[i],color='black',fontsize=10,) #将数值显示在图形上
ax1.set_xticklabels(l,rotation=45) #将横坐标进行倾斜45度
ax1.legend(loc=1)
ax1.set_ylim([0, 0.32]);
ax1.set_ylabel('人数占比');
plt.legend(prop={'family':'SimHei','size':8}) #设置中文
ax2 = ax1.twinx() # this is the important function
plt.bar(l,a,alpha=0.5,color='yellow',label=u'人数')
ax2.legend(loc=2)
ax2.set_ylim([0, 8400]);#设置y轴取值范围
ax2.set_ylabel('人数');
plt.legend(prop={'family':'SimHei','size':8},loc="upper left")
for i,(_x,_y) in enumerate(zip(l,a)):
plt.text(_x,_y,a[i],color='black',fontsize=10,) #将数值显示在图形上
plt.xticks(l,lx)
plt.show()
#可视化2
a=result['消费金额'] #数据
b=result['金额占比']
#把b中数字保留两位小数
c = []
for i in b:
c.append(round(i,3))
b=c
l=[i for i in range(8)]
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
fmt="%.2f"
yticks = mtick.FormatStrFormatter(fmt) #设置百分比形式的坐标轴
lx=[u'高消费换回客户',u'流失客户',u'频次深耕客户',u'新客户',u'重要价值客户',u'消费潜力客户',u'重要价值流失预警客户',u'一般客户']
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.plot(l, b,'or-',label=u'金额占比');
ax1.yaxis.set_major_formatter(yticks)
#for i,(_x,_y) in enumerate(zip(l,b)):
# plt.text(_x,_y,b[i],color='black',fontsize=10,) #将数值显示在图形上
ax1.set_xticklabels(l,rotation=45) #将横坐标进行倾斜45度
ax1.legend(loc=1)
ax1.set_ylim([0, 0.40]);
ax1.set_ylabel('金额占比');
plt.legend(prop={'family':'SimHei','size':8}) #设置中文
ax2 = ax1.twinx() # this is the important function
plt.bar(l,a,alpha=0.3,color='blue',label=u'消费金额')
ax2.legend(loc=2)
ax2.set_ylim([20000,1400000]);#设置y轴取值范围
ax2.set_ylabel('消费金额');
plt.legend(prop={'family':'SimHei','size':8},loc="upper left")
for i,(_x,_y) in enumerate(zip(l,a)):
plt.text(_x,_y,a[i],color='black',fontsize=10,) #将数值显示在图形上
plt.xticks(l,lx)
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号