20212329实验四《Python程序设计》Python综合实践报告
20212329实验四《Python程序设计》Python综合实践报告
课程:《Python程序设计》
一、实验内容
二、成果预测
三、项目过程
四、问题及解决方案
五、实际效果
六、课程总结
七、感想及建议
一、实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
课代表和各小组负责人收集作业(源代码、视频、综合实践报告)
注:在华为ECS服务器(OpenOuler系统)和物理机(Windows/Linux系统)上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
批阅:注意本次实验不算做实验总分,前三个实验每个实验10分,累计30分。本次实践算入综合实践,打分为25分。
评分标准:
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)10分
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。10分。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。5分
(4)如果没有使用华为云服务(ECS或者MindSpore均可),本次实践扣10分。
二、项目背景
对股市具有深刻了解的证券分析人员根据股票行情的发展进行的对未来股市发展方向以及涨跌程度的预测行为。这种预测行为只是基于假定的因素为既定的前提条件为基础的。
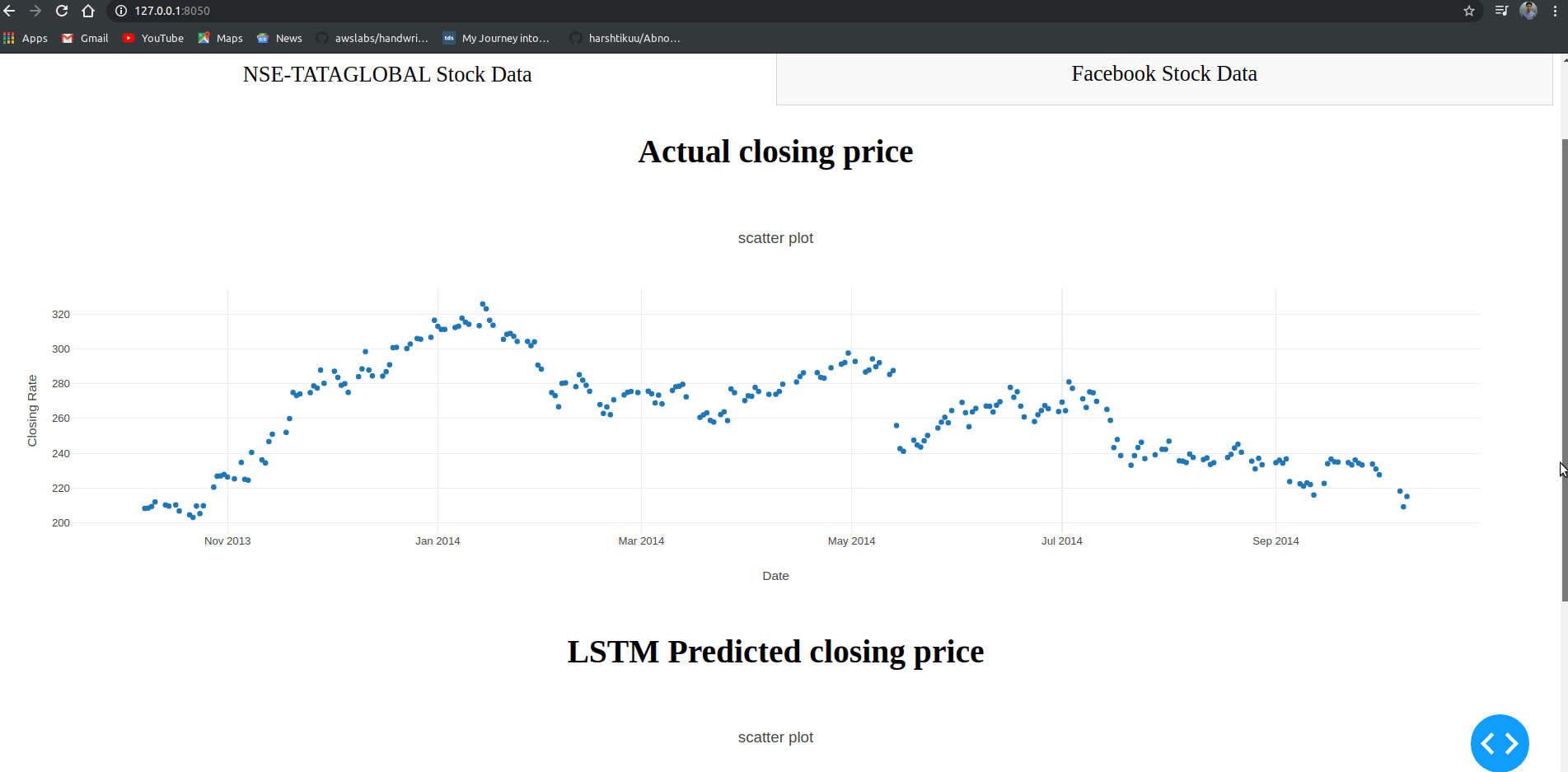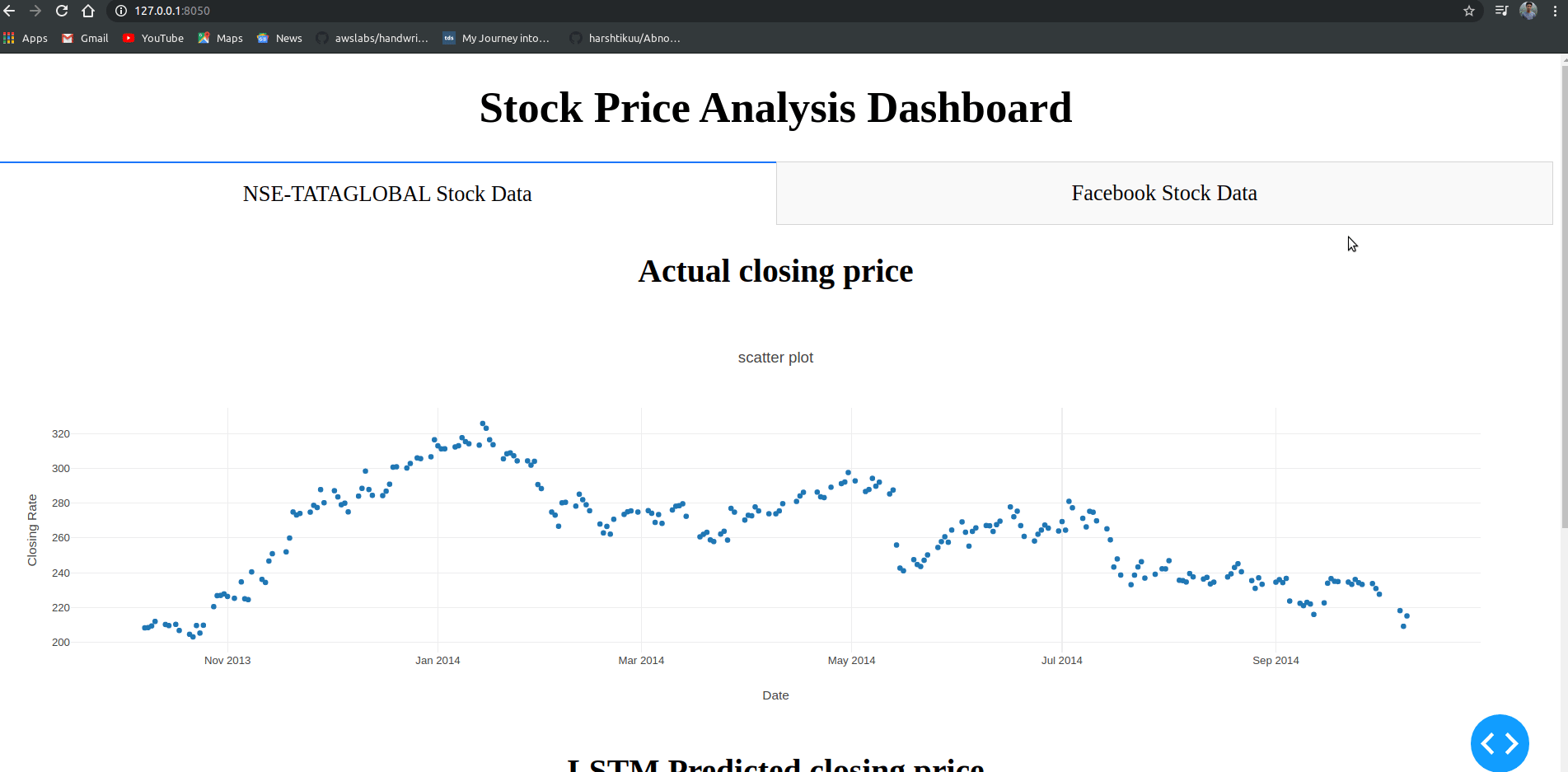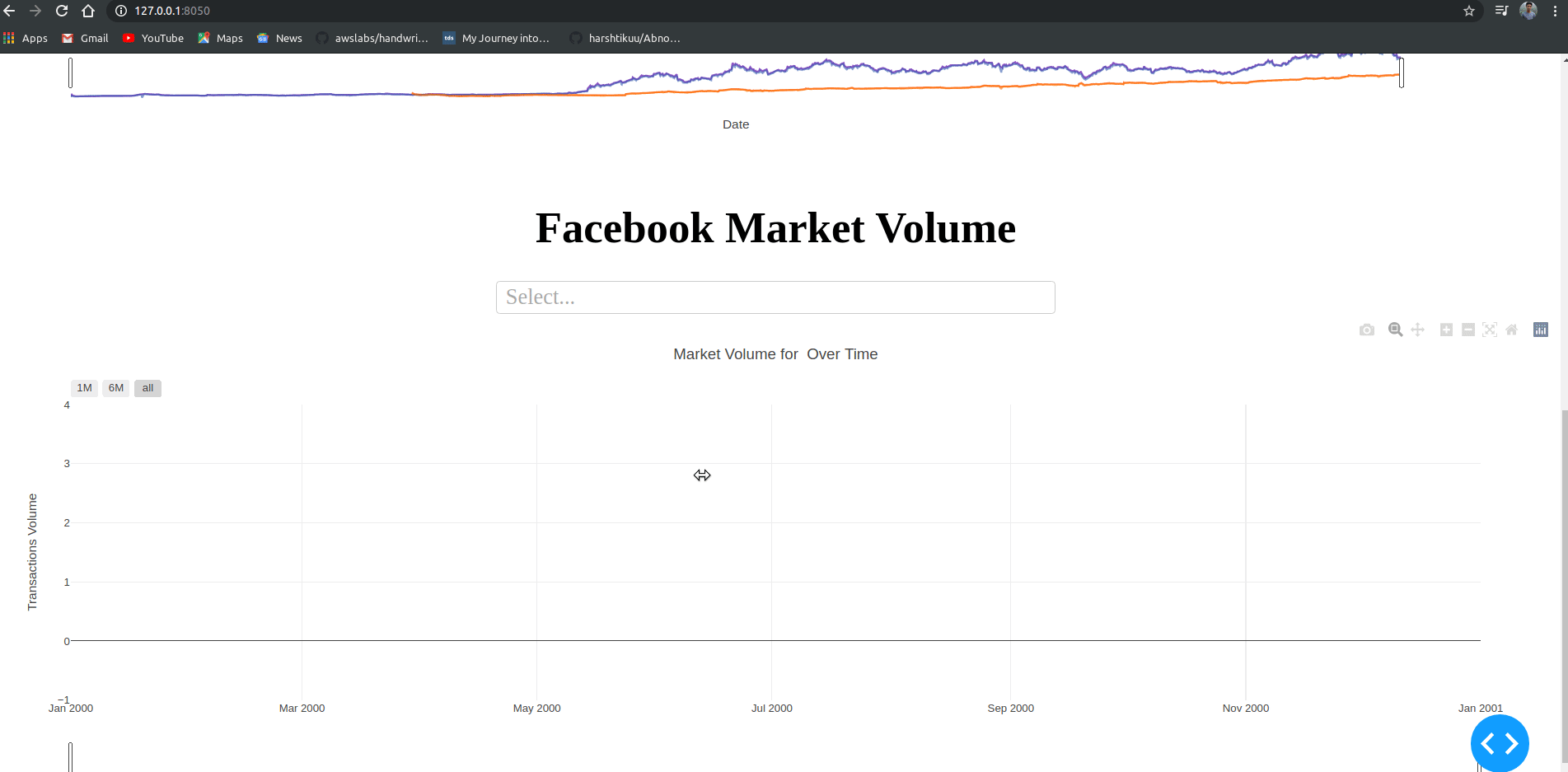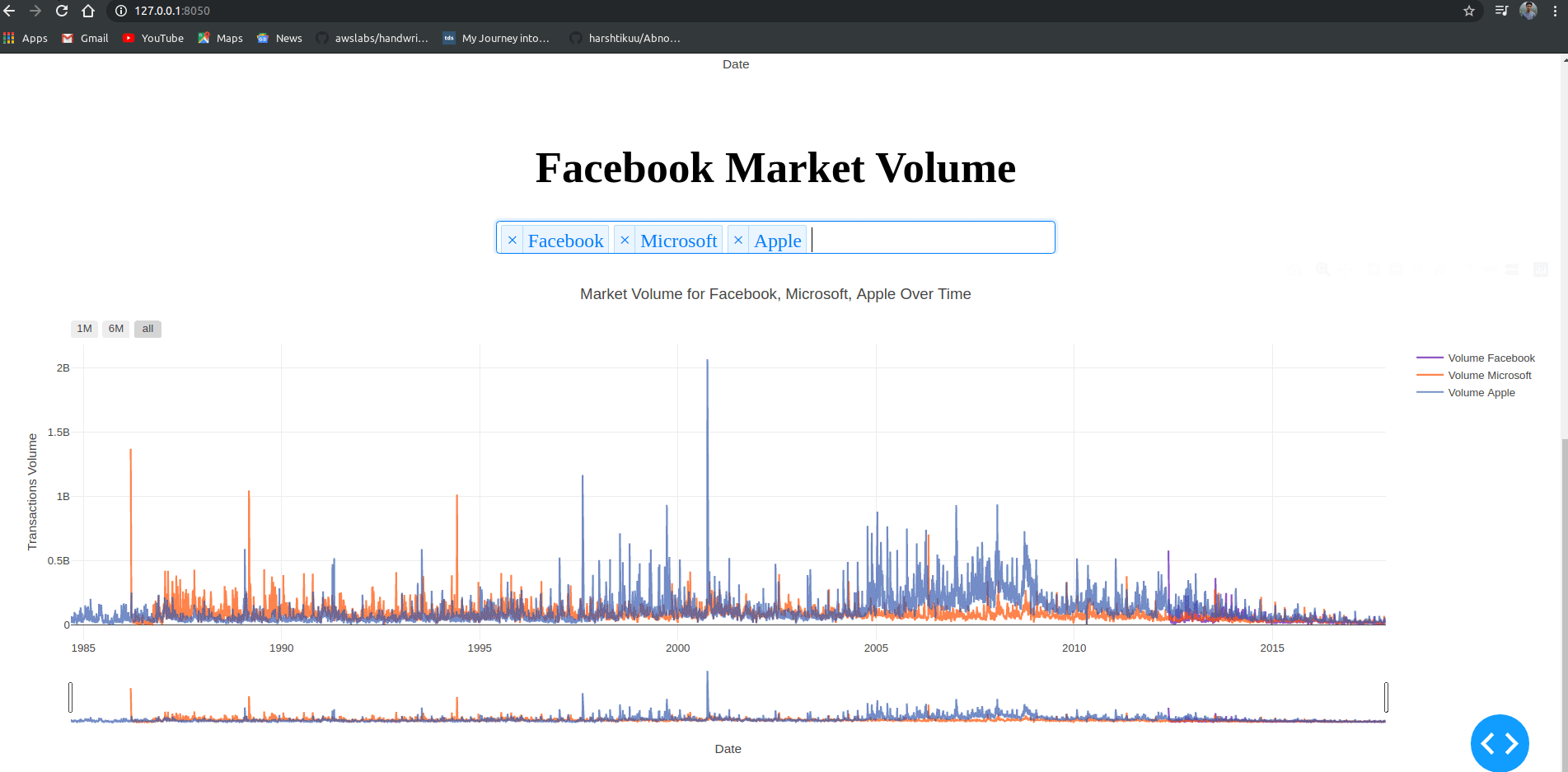
三、项目过程
机器学习在股票价格预测中有着重要的应用。在这个机器学习项目中,我们将讨论预测股票的回报。这个非常复杂的任务有不确定性。
爬取股票历史数据记录
1.配置python环境,登入baostock官网,爬取数据,查询代码对应股票的历史K线数据以及日期、代码、开盘价、日最高价、日最低价、收盘价,前日收盘价、成交量、成交额等参数。
2.获取沪深300成分股,将结果集输出到csv文件和xlsx文件,登出系统。
3.将数据集分为两组:训练集和测试集,训练集远多于测试集(训练集:用来训练模型或确定模型参数;验证集:用来做模型选择;测试集:检验最终选择最优的模型性能如何。验证集不是必须有的,数据集较小只需要有训练集和测试集)。分别设置开始时间和结束时间(超过会自动截止)
1 import baostock 2 import pandas 3 import openpyxl 4 from sklearn import linear_model 5 import numpy 6 import matplotlib.pyplot 7 from sklearn.metrics import r2_score 8 9 stock='sh.600519' #可选择股票 10 11 print('login respond error_code:'+baostock.login().error_code) 12 print('login respond error_msg:'+baostock.login().error_msg) 13 14 bqh = baostock.query_history_k_data_plus(stock, 15 "date,code,open,high,low,close,preclose,volume,amount,turn,pctChg", 16 start_date='2020-01-01', end_date='2021-01-01') 17 print('query_hushen300 error_code:'+bqh.error_code) 18 print('query_hushen300 error_msg:'+bqh.error_msg) 19 hushen300_stocks = [] 20 while (bqh.error_code == '0') & bqh.next(): 21 22 hushen300_stocks.append(bqh.get_row_data()) 23 result = pandas.DataFrame(hushen300_stocks, columns=bqh.fields) 24 result.to_csv("训练集.csv") 25 result.to_excel("训练集.xlsx") 26 27 bqh = baostock.query_history_k_data_plus(stock, 28 "date,code,open,high,low,close,preclose,volume,amount,turn,pctChg", 29 start_date='2022-03-01', end_date='2029-7-20')#超过会自动截止到最新日期 30 print('query_hushen300 error_code:'+bqh.error_code) 31 print('query_hushen300 error_msg:'+bqh.error_msg) 32 hushen300_stocks = [] 33 while (bqh.error_code == '0') & bqh.next(): 34 35 hushen300_stocks.append(bqh.get_row_data()) 36 result = pandas.DataFrame(hushen300_stocks, columns=bqh.fields) 37 result.to_csv("测试集.csv") 38 result.to_excel("测试集.xlsx") 39 40 baostock.logout()
处理数据
4.在Excel中处理数据,将日期中的"-"删去,转换为纯数字以能作为做回归时或重新排序(重新排序会导致训练集与测试集日期数据误差过大)
5.将Excel中的数据按列存入列表中,注意不能直接使用:
1 date1 = pandas.read_excel('训练集.xlsx', usecols='B') 2 open1 = pandas.read_excel('训练集.xlsx', usecols='D') 3 high1 = pandas.read_excel('训练集.xlsx', usecols='E') 4 low1 = pandas.read_excel('训练集.xlsx', usecols='F') 5 close1 = pandas.read_excel('训练集.xlsx', usecols='G') 6 preclose1 = pandas.read_excel('训练集.xlsx', usecols='H') 7 volume1 = pandas.read_excel('训练集.xlsx', usecols='I') 8 amount1 = pandas.read_excel('训练集.xlsx', usecols='J') 9 turn1 = pandas.read_excel('训练集.xlsx', usecols='K') 10 pctchg1 = pandas.read_excel('训练集.xlsx', usecols='L') 11 12 date2 = pandas.read_excel('测试集.xlsx', usecols='B') 13 open2 = pandas.read_excel('测试集.xlsx', usecols='D') 14 high2 = pandas.read_excel('测试集.xlsx', usecols='E') 15 low2 = pandas.read_excel('测试集.xlsx', usecols='F') 16 close2 = pandas.read_excel('测试集.xlsx', usecols='G') 17 preclose2 = pandas.read_excel('测试集.xlsx', usecols='H') 18 volume2 = pandas.read_excel('测试集.xlsx', usecols='I') 19 amount2 = pandas.read_excel('测试集.xlsx', usecols='J') 20 turn2 = pandas.read_excel('测试集.xlsx', usecols='K') 21 pctchg2 = pandas.read_excel('测试集.xlsx', usecols='L')
这样输出其非列表,无法做回归,使用循环分别读取每列的每一行元素以形成列表为散点图做准备。
1 pre = pandas.read_excel("训练集.xlsx", usecols=[1]) 2 pre_list = pre.values.tolist() 3 date1 = [] 4 for s_list in pre_list: 5 date1.append(s_list[0]) 6 pre = pandas.read_excel("训练集.xlsx", usecols=[3]) 7 pre_list = pre.values.tolist() 8 open1 = [] 9 for s_list in pre_list: 10 open1.append(s_list[0]) 11 pre = pandas.read_excel("训练集.xlsx", usecols=[4]) 12 pre_list = pre.values.tolist() 13 high1 = [] 14 for s_list in pre_list: 15 high1.append(s_list[0]) 16 pre = pandas.read_excel("训练集.xlsx", usecols=[5]) 17 pre_list = pre.values.tolist() 18 low1 = [] 19 for s_list in pre_list: 20 low1.append(s_list[0]) 21 pre = pandas.read_excel("训练集.xlsx", usecols=[6]) 22 pre_list = pre.values.tolist() 23 close1 = [] 24 for s_list in pre_list: 25 close1.append(s_list[0]) 26 pre = pandas.read_excel("训练集.xlsx", usecols=[7]) 27 pre_list = pre.values.tolist() 28 preclose1 = [] 29 for s_list in pre_list: 30 preclose1.append(s_list[0]) 31 pre = pandas.read_excel("训练集.xlsx", usecols=[8]) 32 pre_list = pre.values.tolist() 33 volume1 = [] 34 for s_list in pre_list: 35 volume1.append(s_list[0]) 36 pre = pandas.read_excel("训练集.xlsx", usecols=[9]) 37 pre_list = pre.values.tolist() 38 amount1 = [] 39 for s_list in pre_list: 40 amount1.append(s_list[0]) 41 pre = pandas.read_excel("训练集.xlsx", usecols=[10]) 42 pre_list = pre.values.tolist() 43 turn1 = [] 44 for s_list in pre_list: 45 turn1.append(s_list[0]) 46 pre = pandas.read_excel("训练集.xlsx", usecols=[11]) 47 pre_list = pre.values.tolist() 48 pctchg1 = [] 49 for s_list in pre_list: 50 pctchg1.append(s_list[0]) 51 pre = pandas.read_excel("测试集.xlsx", usecols=[1]) 52 pre_list = pre.values.tolist() 53 date2 = [] 54 for s_list in pre_list: 55 date2.append(s_list[0]) 56 pre = pandas.read_excel("测试集.xlsx", usecols=[3]) 57 pre_list = pre.values.tolist() 58 open2 = [] 59 for s_list in pre_list: 60 open2.append(s_list[0]) 61 pre = pandas.read_excel("测试集.xlsx", usecols=[4]) 62 pre_list = pre.values.tolist() 63 high2 = [] 64 for s_list in pre_list: 65 high2.append(s_list[0]) 66 pre = pandas.read_excel("测试集.xlsx", usecols=[5]) 67 pre_list = pre.values.tolist() 68 low2 = [] 69 for s_list in pre_list: 70 low2.append(s_list[0]) 71 pre = pandas.read_excel("测试集.xlsx", usecols=[6]) 72 pre_list = pre.values.tolist() 73 close2 = [] 74 for s_list in pre_list: 75 close2.append(s_list[0]) 76 pre = pandas.read_excel("测试集.xlsx", usecols=[7]) 77 pre_list = pre.values.tolist() 78 preclose2 = [] 79 for s_list in pre_list: 80 preclose2.append(s_list[0]) 81 pre = pandas.read_excel("测试集.xlsx", usecols=[8]) 82 pre_list = pre.values.tolist() 83 volume2 = [] 84 for s_list in pre_list: 85 volume2.append(s_list[0]) 86 pre = pandas.read_excel("测试集.xlsx", usecols=[9]) 87 pre_list = pre.values.tolist() 88 amount2 = [] 89 for s_list in pre_list: 90 amount2.append(s_list[0]) 91 pre = pandas.read_excel("测试集.xlsx", usecols=[10]) 92 pre_list = pre.values.tolist() 93 turn2 = [] 94 for s_list in pre_list: 95 turn2.append(s_list[0]) 96 pre = pandas.read_excel("测试集.xlsx", usecols=[11]) 97 pre_list = pre.values.tolist() 98 pctchg2 = [] 99 for s_list in pre_list: 100 pctchg2.append(s_list[0])
计算大量数据的线性回归并计算拟合度,拟合度高于0.8则采用,低于0.1则不采用。
而后分为两种方法:
①寻找日期与其他参数的回归关系并预测出其他参数的未来数值,再寻找其他参数和收盘价的回归关系,利用预测出的其他参数的未来数值预测收盘价未来数值(多元回归)
1 mymodel = numpy.poly1d(numpy.polyfit(date1, open1, 1)) 2 myline = numpy.linspace(20200102, 20201231) 3 matplotlib.pyplot.scatter(date1, open1) 4 matplotlib.pyplot.plot(myline, mymodel(myline)) 5 matplotlib.pyplot.show() 6 print(r2_score(open1, mymodel(date1))) 7 8 mymodel = numpy.poly1d(numpy.polyfit(date1, high1, 1)) 9 myline = numpy.linspace(20200102, 20201231) 10 matplotlib.pyplot.scatter(date1, high1) 11 matplotlib.pyplot.plot(myline, mymodel(myline)) 12 matplotlib.pyplot.show() 13 print(r2_score(high1, mymodel(date1))) 14 15 mymodel = numpy.poly1d(numpy.polyfit(date1, low1, 1)) 16 myline = numpy.linspace(20200102, 20201231) 17 matplotlib.pyplot.scatter(date1, low1) 18 matplotlib.pyplot.plot(myline, mymodel(myline)) 19 matplotlib.pyplot.show() 20 print(r2_score(low1, mymodel(date1))) 21 22 mymodel = numpy.poly1d(numpy.polyfit(date1, close1, 1)) 23 myline = numpy.linspace(20200102, 20201231) 24 matplotlib.pyplot.scatter(date1, close1) 25 matplotlib.pyplot.plot(myline, mymodel(myline)) 26 matplotlib.pyplot.show() 27 print(r2_score(close1, mymodel(date1))) 28 29 mymodel = numpy.poly1d(numpy.polyfit(date1, preclose1, 1)) 30 myline = numpy.linspace(20200102, 20201231) 31 matplotlib.pyplot.scatter(date1, preclose1) 32 matplotlib.pyplot.plot(myline, mymodel(myline)) 33 matplotlib.pyplot.show() 34 print(r2_score(preclose1, mymodel(date1))) 35 36 mymodel = numpy.poly1d(numpy.polyfit(date1, volume1, 1)) 37 myline = numpy.linspace(20200102, 20201231) 38 matplotlib.pyplot.scatter(date1, volume1) 39 matplotlib.pyplot.plot(myline, mymodel(myline)) 40 matplotlib.pyplot.show() 41 print(r2_score(volume1, mymodel(date1))) 42 43 mymodel = numpy.poly1d(numpy.polyfit(date1, amount1, 1)) 44 myline = numpy.linspace(20200102, 20201231) 45 matplotlib.pyplot.scatter(date1, amount1) 46 matplotlib.pyplot.plot(myline, mymodel(myline)) 47 matplotlib.pyplot.show() 48 print(r2_score(amount1, mymodel(date1))) 49 50 mymodel = numpy.poly1d(numpy.polyfit(date1, turn1, 1)) 51 myline = numpy.linspace(20200102, 20201231) 52 matplotlib.pyplot.scatter(date1, turn1) 53 matplotlib.pyplot.plot(myline, mymodel(myline)) 54 matplotlib.pyplot.show() 55 print(r2_score(turn1, mymodel(date1))) 56 57 mymodel = numpy.poly1d(numpy.polyfit(date1, pctchg1, 1)) 58 myline = numpy.linspace(20200102, 20201231) 59 matplotlib.pyplot.scatter(date1, pctchg1) 60 matplotlib.pyplot.plot(myline, mymodel(myline)) 61 matplotlib.pyplot.show() 62 print(r2_score(pctchg1, mymodel(date1)))
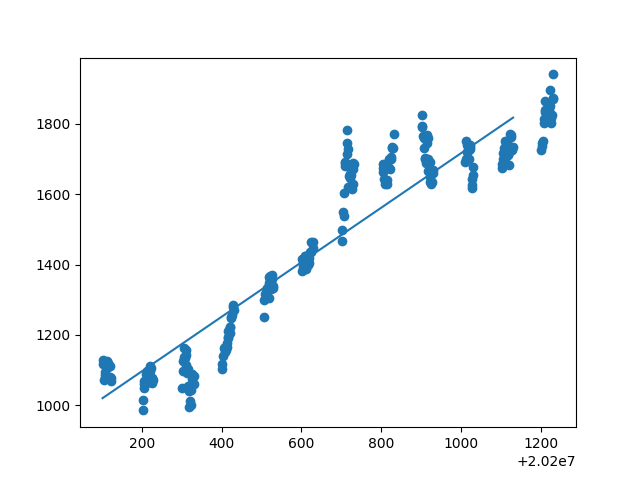
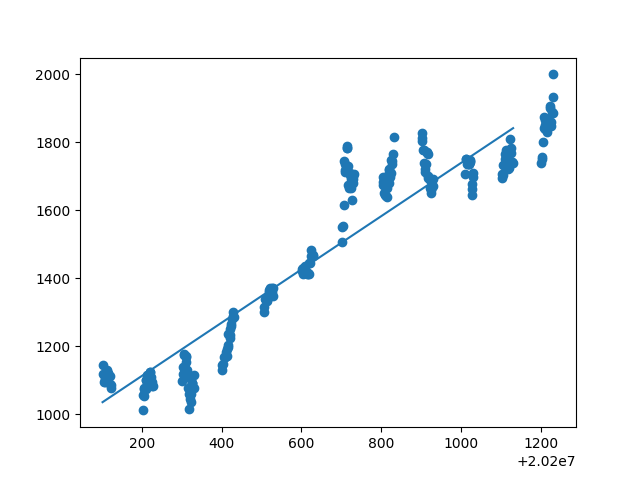
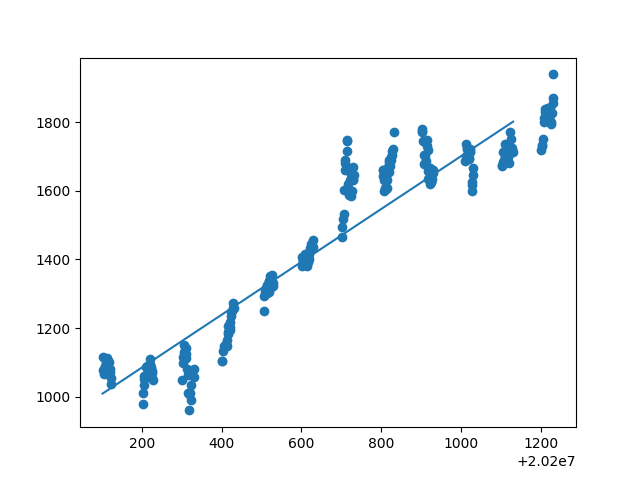
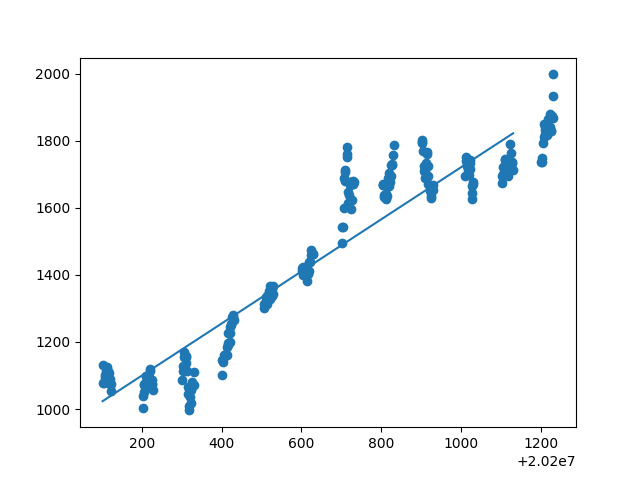
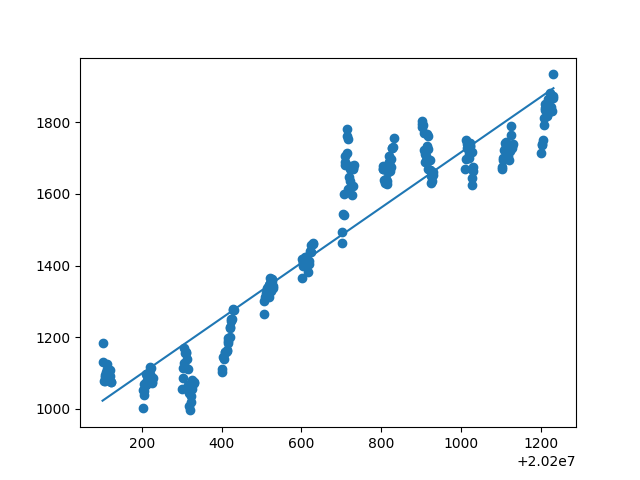
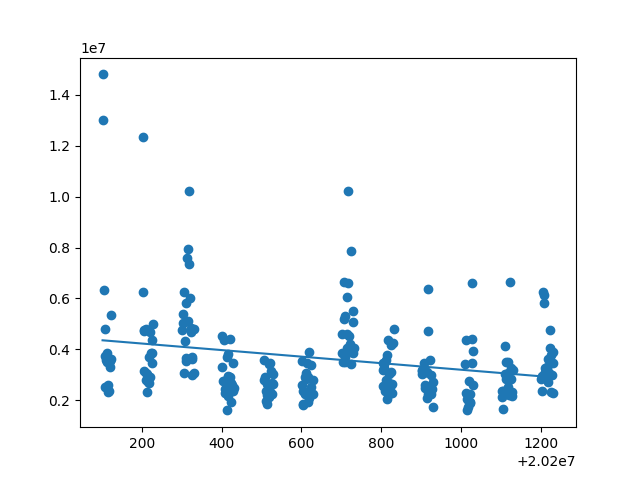
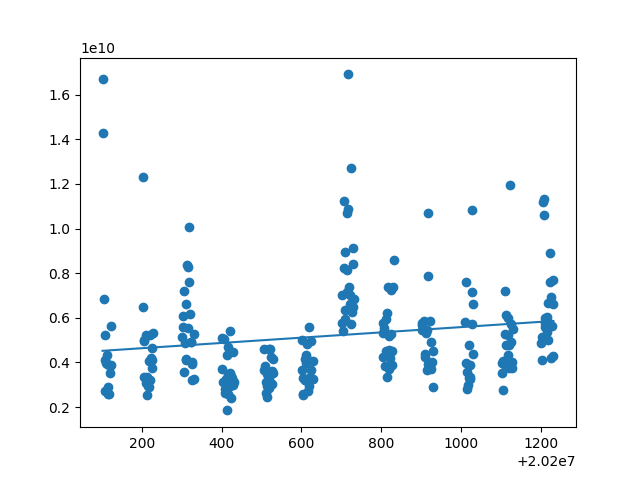
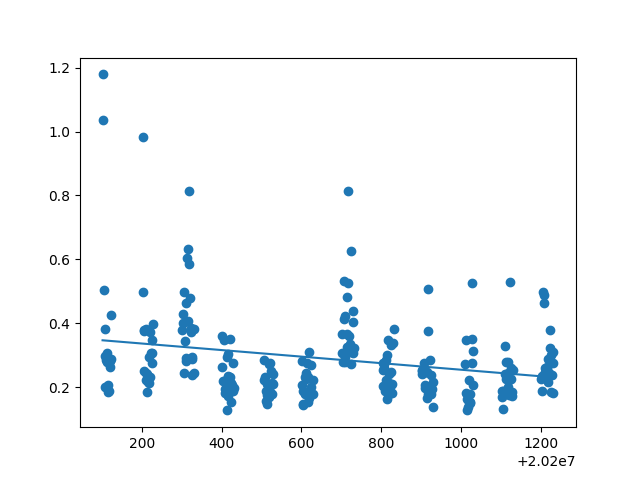
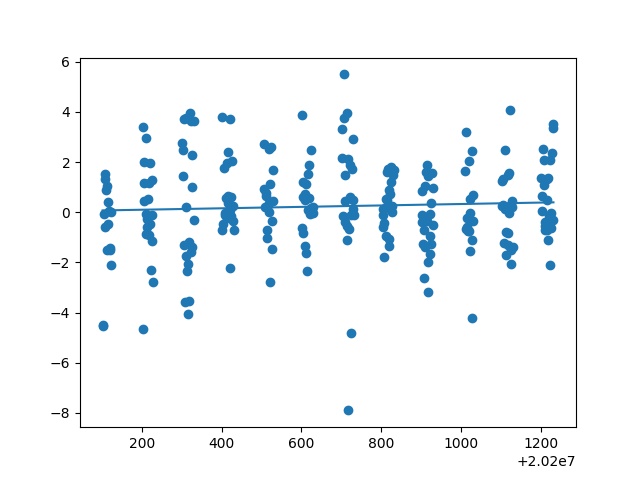
由所得散点图回归直线及拟合度可得:开盘价、日最高价、日最低价、收盘价、前日收盘价能与日期拟合线性关系,其拟合度都在0.9左右。然后用开盘价、日最高价、日最低价、收盘价、前日收盘价等测试数据来测试模型,以检验是否给出相同的结果。
1 mymodel = numpy.poly1d(numpy.polyfit(date1, open1, 1)) 2 r2 = r2_score(open2, mymodel(date2)) 3 print(r2) 4 mymodel = numpy.poly1d(numpy.polyfit(date1, high1, 1)) 5 r2 = r2_score(high2, mymodel(date2)) 6 print(r2) 7 mymodel = numpy.poly1d(numpy.polyfit(date1, low1, 1)) 8 r2 = r2_score(low2, mymodel(date2)) 9 print(r2) 10 mymodel = numpy.poly1d(numpy.polyfit(date1, close1, 1)) 11 r2 = r2_score(close2, mymodel(date2)) 12 print(r2) 13 mymodel = numpy.poly1d(numpy.polyfit(date1, preclose1, 1)) 14 r2 = r2_score(preclose2, mymodel(date2)) 15 print(r2) 16 mymodel = numpy.poly1d(numpy.polyfit(date1, volume1, 1)) 17 r2 = r2_score(volume2, mymodel(date2)) 18 print(r2) 19 mymodel = numpy.poly1d(numpy.polyfit(date1, amount1, 1)) 20 r2 = r2_score(amount2, mymodel(date2)) 21 print(r2) 22 mymodel = numpy.poly1d(numpy.polyfit(date1, turn1, 1)) 23 r2 = r2_score(turn2, mymodel(date2)) 24 print(r2) 25 mymodel = numpy.poly1d(numpy.polyfit(date1, pctchg1, 1)) 26 r2 = r2_score(pctchg2, mymodel(date2)) 27 print(r2)
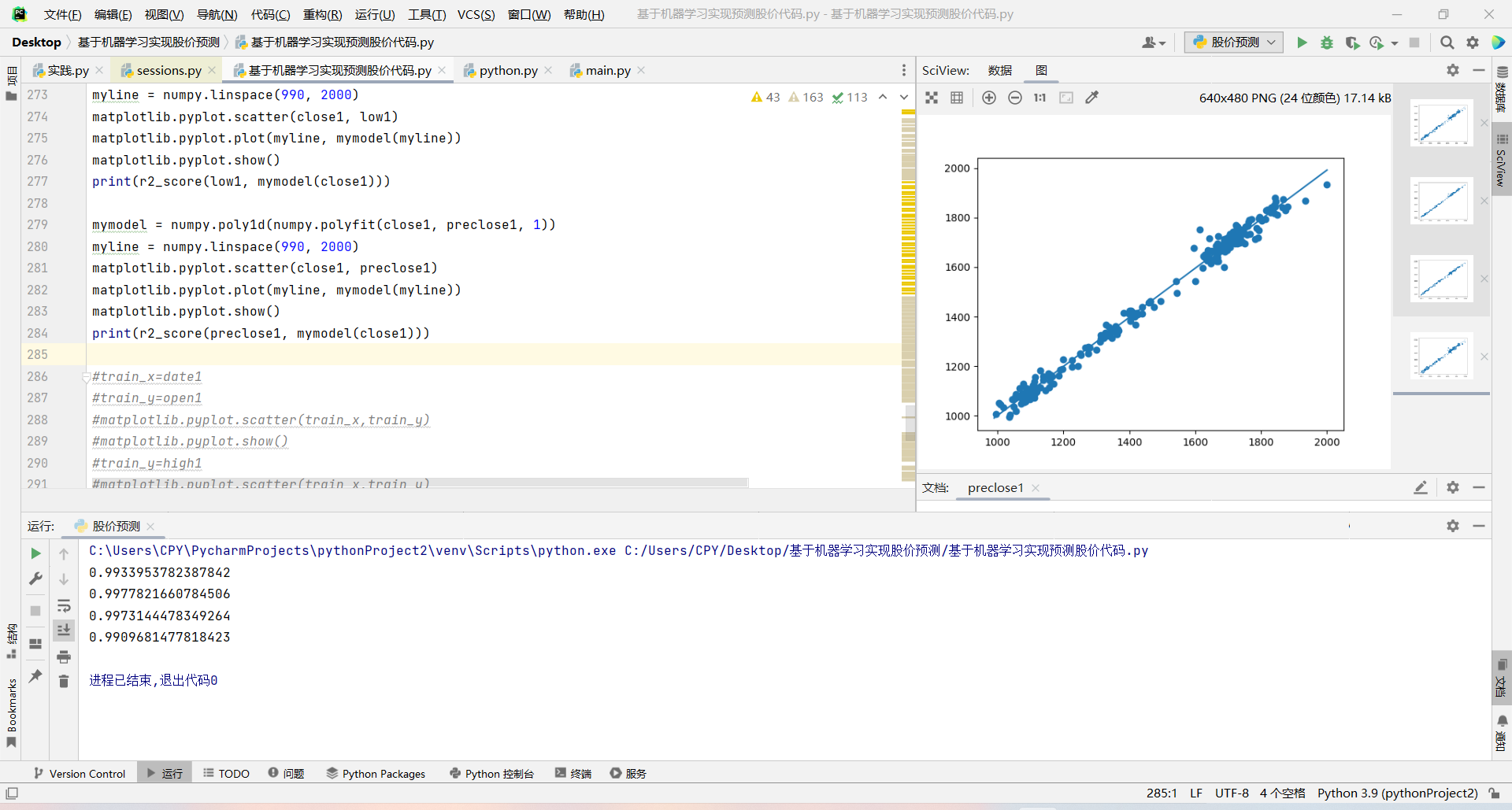
结果表明该模型适合测试集,即确信可以使用该模型预测未来值。可以开始预测新值了。
接下来用同样的方法寻找其他参数和收盘价的回归关系,得出开盘价,最高价,最低价,前日收盘价能与收盘价拟合线性关系,其拟合度都在1左右。之后测试模型,拟合度比较高表示模型还不错,可以预测了。
1 want_date=int(input()) 2 mymodel = numpy.poly1d(numpy.polyfit(date1, open1, 1)) 3 r2 = r2_score(open2, mymodel(date2)) 4 future_open=mymodel(want_date) 5 6 mymodel = numpy.poly1d(numpy.polyfit(date1, high1, 1)) 7 r2 = r2_score(high2, mymodel(date2)) 8 future_high=mymodel(want_date) 9 10 mymodel = numpy.poly1d(numpy.polyfit(date1, low1, 1)) 11 r2 = r2_score(low2, mymodel(date2)) 12 future_low=mymodel(want_date) 13 14 mymodel = numpy.poly1d(numpy.polyfit(date1, close1, 1)) 15 r2 = r2_score(close2, mymodel(date2)) 16 future_close=mymodel(want_date) 17 18 mymodel = numpy.poly1d(numpy.polyfit(date1, preclose1, 1)) 19 r2 = r2_score(preclose2, mymodel(date2)) 20 future_preclose=mymodel(want_date) 21 22 mymodel = numpy.poly1d(numpy.polyfit(open1, close1, 1)) 23 r2 = r2_score(open2, mymodel(close2)) 24 future_close1=mymodel(future_open) 25 mymodel = numpy.poly1d(numpy.polyfit(high1,close1 , 1)) 26 r2 = r2_score(high2, mymodel(close2)) 27 future_close2=mymodel(future_high) 28 mymodel = numpy.poly1d(numpy.polyfit(low1, close1, 1)) 29 r2 = r2_score(low2, mymodel(close2)) 30 future_close3=mymodel(future_low) 31 mymodel = numpy.poly1d(numpy.polyfit(preclose1, close1, 1)) 32 r2 = r2_score(preclose2, mymodel(close2)) 33 future_close4=mymodel(future_preclose) 34 print((future_close+future_close1+future_close2+future_close3+future_close4)/5)
②将Excel的前日收盘价替换为明日收盘价,空出最后一行的单元格(不计入回归计算中),寻找其他参数与明日收盘价的回归关系并利用已知参数预测。(避开日期差的问题)
该方法与第一种方法大体步骤一致,与未来收盘价拟合度高的参数是开盘价,最高价,最低价,收盘价,拟合度都在0.9左右并对这四个模型进行测试。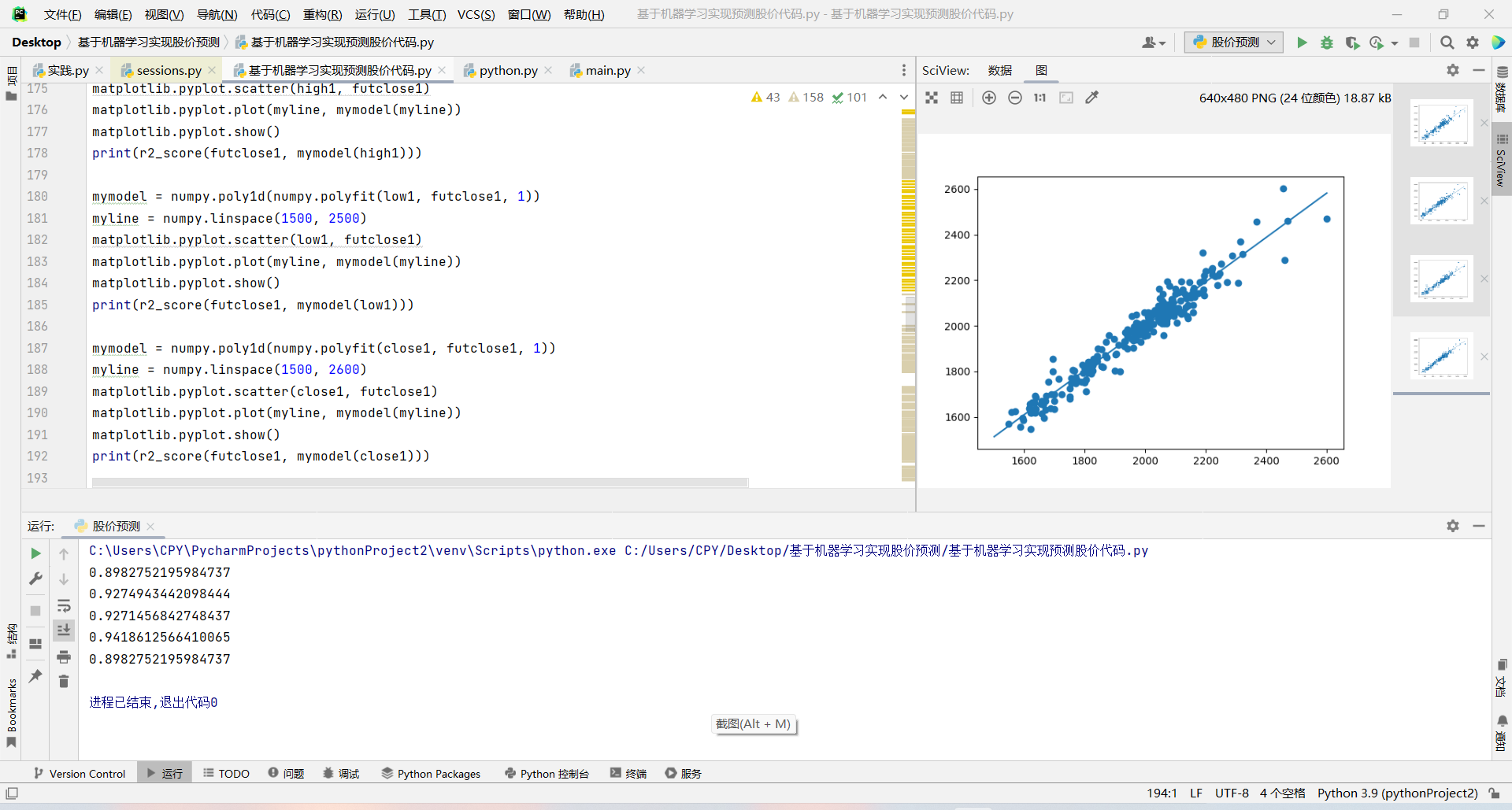
1 pre = pandas.read_excel("训练集.xlsx", usecols=[7]) 2 pre_list = pre.values.tolist() 3 futclose1 = [] 4 for s_list in pre_list: 5 futclose1.append(s_list[0])
1 mymodel = numpy.poly1d(numpy.polyfit(open1, futclose1, 1)) 2 myline = numpy.linspace(1500, 2600) 3 matplotlib.pyplot.scatter(open1, futclose1) 4 matplotlib.pyplot.plot(myline, mymodel(myline)) 5 #matplotlib.pyplot.show() 6 #print(r2_score(futclose1, mymodel(open1))) 7 8 mymodel = numpy.poly1d(numpy.polyfit(high1, futclose1, 1)) 9 myline = numpy.linspace(1600, 2600) 10 matplotlib.pyplot.scatter(high1, futclose1) 11 matplotlib.pyplot.plot(myline, mymodel(myline)) 12 #matplotlib.pyplot.show() 13 #print(r2_score(futclose1, mymodel(high1))) 14 15 mymodel = numpy.poly1d(numpy.polyfit(low1, futclose1, 1)) 16 myline = numpy.linspace(1500, 2500) 17 matplotlib.pyplot.scatter(low1, futclose1) 18 matplotlib.pyplot.plot(myline, mymodel(myline)) 19 #matplotlib.pyplot.show() 20 #print(r2_score(futclose1, mymodel(low1))) 21 22 mymodel = numpy.poly1d(numpy.polyfit(close1, futclose1, 1)) 23 myline = numpy.linspace(1500, 2600) 24 matplotlib.pyplot.scatter(close1, futclose1) 25 matplotlib.pyplot.plot(myline, mymodel(myline)) 26 #matplotlib.pyplot.show() 27 #print(r2_score(futclose1, mymodel(close1))) 28 29 openx=float(input("输入今日开盘价:\n")) 30 highx=float(input("输入今日最高价:\n")) 31 lowx=float(input("输入今日最低价:\n")) 32 closex=float(input("输入今日收盘价:\n")) 33 mymodel = numpy.poly1d(numpy.polyfit(open1, futclose1, 1)) 34 r2 = r2_score(open2, mymodel(close2)) 35 future_close1=mymodel(openx) 36 mymodel = numpy.poly1d(numpy.polyfit(high1,futclose1 , 1)) 37 r2 = r2_score(high2, mymodel(close2)) 38 future_close2=mymodel(highx) 39 mymodel = numpy.poly1d(numpy.polyfit(low1, futclose1, 1)) 40 r2 = r2_score(low2, mymodel(close2)) 41 future_close3=mymodel(lowx) 42 mymodel = numpy.poly1d(numpy.polyfit(close1, futclose1, 1)) 43 r2 = r2_score(futclose2, mymodel(close2)) 44 future_close4=mymodel(closex) 45 print("预测明日收盘价为:") 46 print((future_close4+future_close3+future_close2+future_close1)/4)
上传至码云
在华为云上运行
完整代码
1 import baostock 2 import pandas 3 import openpyxl 4 from sklearn import linear_model 5 import numpy 6 import matplotlib.pyplot 7 from sklearn.metrics import r2_score 8 9 stock='sh.600519' #可选择股票 10 11 print('login respond error_code:'+baostock.login().error_code) 12 print('login respond error_msg:'+baostock.login().error_msg) 13 14 bqh = baostock.query_history_k_data_plus(stock, 15 "date,code,open,high,low,close,preclose,volume,amount,turn,pctChg", 16 start_date='2020-01-01', end_date='2021-01-01') 17 print('query_hushen300 error_code:'+bqh.error_code) 18 print('query_hushen300 error_msg:'+bqh.error_msg) 19 hushen300_stocks = [] 20 while (bqh.error_code == '0') & bqh.next(): 21 22 hushen300_stocks.append(bqh.get_row_data()) 23 result = pandas.DataFrame(hushen300_stocks, columns=bqh.fields) 24 result.to_csv("训练集.csv") 25 result.to_excel("训练集.xlsx") 26 27 bqh = baostock.query_history_k_data_plus(stock,"date,code,open,high,low,close,preclose,volume,amount,turn,pctChg", 28 start_date='2022-03-01', end_date='2029-7-20')#超过会自动截止到最新日期 29 print('query_hushen300 error_code:'+bqh.error_code) 30 print('query_hushen300 error_msg:'+bqh.error_msg) 31 hushen300_stocks = [] 32 while (bqh.error_code == '0') & bqh.next(): 33 34 hushen300_stocks.append(bqh.get_row_data()) 35 result = pandas.DataFrame(hushen300_stocks, columns=bqh.fields) 36 result.to_csv("测试集.csv") 37 result.to_excel("测试集.xlsx") 38 39 baostock.logout() 40 41 42 43 44 pre = pandas.read_excel("训练集.xlsx", usecols=[1]) 45 pre_list = pre.values.tolist() 46 date1 = [] 47 for s_list in pre_list: 48 date1.append(s_list[0]) 49 pre = pandas.read_excel("训练集.xlsx", usecols=[3]) 50 pre_list = pre.values.tolist() 51 open1 = [] 52 for s_list in pre_list: 53 open1.append(s_list[0]) 54 pre = pandas.read_excel("训练集.xlsx", usecols=[4]) 55 pre_list = pre.values.tolist() 56 high1 = [] 57 for s_list in pre_list: 58 high1.append(s_list[0]) 59 pre = pandas.read_excel("训练集.xlsx", usecols=[5]) 60 pre_list = pre.values.tolist() 61 low1 = [] 62 for s_list in pre_list: 63 low1.append(s_list[0]) 64 pre = pandas.read_excel("训练集.xlsx", usecols=[6]) 65 pre_list = pre.values.tolist() 66 close1 = [] 67 for s_list in pre_list: 68 close1.append(s_list[0]) 69 pre = pandas.read_excel("训练集.xlsx", usecols=[7]) 70 pre_list = pre.values.tolist() 71 preclose1 = [] 72 for s_list in pre_list: 73 preclose1.append(s_list[0]) 74 pre = pandas.read_excel("训练集.xlsx", usecols=[8]) 75 pre_list = pre.values.tolist() 76 volume1 = [] 77 for s_list in pre_list: 78 volume1.append(s_list[0]) 79 pre = pandas.read_excel("训练集.xlsx", usecols=[9]) 80 pre_list = pre.values.tolist() 81 amount1 = [] 82 for s_list in pre_list: 83 amount1.append(s_list[0]) 84 pre = pandas.read_excel("训练集.xlsx", usecols=[10]) 85 pre_list = pre.values.tolist() 86 turn1 = [] 87 for s_list in pre_list: 88 turn1.append(s_list[0]) 89 pre = pandas.read_excel("训练集.xlsx", usecols=[11]) 90 pre_list = pre.values.tolist() 91 pctchg1 = [] 92 for s_list in pre_list: 93 pctchg1.append(s_list[0]) 94 pre = pandas.read_excel("测试集.xlsx", usecols=[1]) 95 pre_list = pre.values.tolist() 96 date2 = [] 97 for s_list in pre_list: 98 date2.append(s_list[0]) 99 pre = pandas.read_excel("测试集.xlsx", usecols=[3]) 100 pre_list = pre.values.tolist() 101 open2 = [] 102 for s_list in pre_list: 103 open2.append(s_list[0]) 104 pre = pandas.read_excel("测试集.xlsx", usecols=[4]) 105 pre_list = pre.values.tolist() 106 high2 = [] 107 for s_list in pre_list: 108 high2.append(s_list[0]) 109 pre = pandas.read_excel("测试集.xlsx", usecols=[5]) 110 pre_list = pre.values.tolist() 111 low2 = [] 112 for s_list in pre_list: 113 low2.append(s_list[0]) 114 pre = pandas.read_excel("测试集.xlsx", usecols=[6]) 115 pre_list = pre.values.tolist() 116 close2 = [] 117 for s_list in pre_list: 118 close2.append(s_list[0]) 119 pre = pandas.read_excel("测试集.xlsx", usecols=[7]) 120 pre_list = pre.values.tolist() 121 preclose2 = [] 122 for s_list in pre_list: 123 preclose2.append(s_list[0]) 124 pre = pandas.read_excel("测试集.xlsx", usecols=[8]) 125 pre_list = pre.values.tolist() 126 volume2 = [] 127 for s_list in pre_list: 128 volume2.append(s_list[0]) 129 pre = pandas.read_excel("测试集.xlsx", usecols=[9]) 130 pre_list = pre.values.tolist() 131 amount2 = [] 132 for s_list in pre_list: 133 amount2.append(s_list[0]) 134 pre = pandas.read_excel("测试集.xlsx", usecols=[10]) 135 pre_list = pre.values.tolist() 136 turn2 = [] 137 for s_list in pre_list: 138 turn2.append(s_list[0]) 139 pre = pandas.read_excel("测试集.xlsx", usecols=[11]) 140 pre_list = pre.values.tolist() 141 pctchg2 = [] 142 for s_list in pre_list: 143 pctchg2.append(s_list[0]) 144 145 mymodel = numpy.poly1d(numpy.polyfit(date1, open1, 1)) 146 myline = numpy.linspace(20200102, 20201231) 147 matplotlib.pyplot.scatter(date1, open1) 148 matplotlib.pyplot.plot(myline, mymodel(myline)) 149 matplotlib.pyplot.show() 150 print(r2_score(open1, mymodel(date1))) 151 152 mymodel = numpy.poly1d(numpy.polyfit(date1, high1, 1)) 153 myline = numpy.linspace(20200102, 20201231) 154 matplotlib.pyplot.scatter(date1, high1) 155 matplotlib.pyplot.plot(myline, mymodel(myline)) 156 matplotlib.pyplot.show() 157 print(r2_score(high1, mymodel(date1))) 158 159 mymodel = numpy.poly1d(numpy.polyfit(date1, low1, 1)) 160 myline = numpy.linspace(20200102, 20201231) 161 matplotlib.pyplot.scatter(date1, low1) 162 matplotlib.pyplot.plot(myline, mymodel(myline)) 163 matplotlib.pyplot.show() 164 print(r2_score(low1, mymodel(date1))) 165 166 mymodel = numpy.poly1d(numpy.polyfit(date1, close1, 1)) 167 myline = numpy.linspace(20200102, 20201231) 168 matplotlib.pyplot.scatter(date1, close1) 169 matplotlib.pyplot.plot(myline, mymodel(myline)) 170 matplotlib.pyplot.show() 171 print(r2_score(close1, mymodel(date1))) 172 173 mymodel = numpy.poly1d(numpy.polyfit(date1, preclose1, 1)) 174 myline = numpy.linspace(20200102, 20201231) 175 matplotlib.pyplot.scatter(date1, preclose1) 176 matplotlib.pyplot.plot(myline, mymodel(myline)) 177 matplotlib.pyplot.show() 178 print(r2_score(preclose1, mymodel(date1))) 179 180 mymodel = numpy.poly1d(numpy.polyfit(date1, volume1, 1)) 181 myline = numpy.linspace(20200102, 20201231) 182 matplotlib.pyplot.scatter(date1, volume1) 183 matplotlib.pyplot.plot(myline, mymodel(myline)) 184 matplotlib.pyplot.show() 185 print(r2_score(volume1, mymodel(date1))) 186 187 mymodel = numpy.poly1d(numpy.polyfit(date1, amount1, 1)) 188 myline = numpy.linspace(20200102, 20201231) 189 matplotlib.pyplot.scatter(date1, amount1) 190 matplotlib.pyplot.plot(myline, mymodel(myline)) 191 matplotlib.pyplot.show() 192 print(r2_score(amount1, mymodel(date1))) 193 194 mymodel = numpy.poly1d(numpy.polyfit(date1, turn1, 1)) 195 myline = numpy.linspace(20200102, 20201231) 196 matplotlib.pyplot.scatter(date1, turn1) 197 matplotlib.pyplot.plot(myline, mymodel(myline)) 198 matplotlib.pyplot.show() 199 print(r2_score(turn1, mymodel(date1))) 200 201 mymodel = numpy.poly1d(numpy.polyfit(date1, pctchg1, 1)) 202 myline = numpy.linspace(20200102, 20201231) 203 matplotlib.pyplot.scatter(date1, pctchg1) 204 matplotlib.pyplot.plot(myline, mymodel(myline)) 205 matplotlib.pyplot.show() 206 print(r2_score(pctchg1, mymodel(date1))) 207 mymodel = numpy.poly1d(numpy.polyfit(date1, open1, 1)) 208 r2 = r2_score(open2, mymodel(date2)) 209 print(r2) 210 mymodel = numpy.poly1d(numpy.polyfit(date1, high1, 1)) 211 r2 = r2_score(high2, mymodel(date2)) 212 print(r2) 213 mymodel = numpy.poly1d(numpy.polyfit(date1, low1, 1)) 214 r2 = r2_score(low2, mymodel(date2)) 215 print(r2) 216 mymodel = numpy.poly1d(numpy.polyfit(date1, close1, 1)) 217 r2 = r2_score(close2, mymodel(date2)) 218 print(r2) 219 mymodel = numpy.poly1d(numpy.polyfit(date1, preclose1, 1)) 220 r2 = r2_score(preclose2, mymodel(date2)) 221 print(r2) 222 mymodel = numpy.poly1d(numpy.polyfit(date1, volume1, 1)) 223 r2 = r2_score(volume2, mymodel(date2)) 224 print(r2) 225 mymodel = numpy.poly1d(numpy.polyfit(date1, amount1, 1)) 226 r2 = r2_score(amount2, mymodel(date2)) 227 print(r2) 228 mymodel = numpy.poly1d(numpy.polyfit(date1, turn1, 1)) 229 r2 = r2_score(turn2, mymodel(date2)) 230 print(r2) 231 mymodel = numpy.poly1d(numpy.polyfit(date1, pctchg1, 1)) 232 r2 = r2_score(pctchg2, mymodel(date2)) 233 print(r2) 234 235 print("请输入日期:\n") 236 rate=0 237 want_date=int(input()) 238 while(want_date>20210000): 239 want_date=want_date-10000 240 rate=rate+1 241 want_date=want_date+rate*100 242 mymodel = numpy.poly1d(numpy.polyfit(date1, open1, 1)) 243 r2 = r2_score(open2, mymodel(date2)) 244 future_open=mymodel(want_date) 245 246 mymodel = numpy.poly1d(numpy.polyfit(date1, high1, 1)) 247 r2 = r2_score(high2, mymodel(date2)) 248 future_high=mymodel(want_date) 249 250 mymodel = numpy.poly1d(numpy.polyfit(date1, low1, 1)) 251 r2 = r2_score(low2, mymodel(date2)) 252 future_low=mymodel(want_date) 253 254 mymodel = numpy.poly1d(numpy.polyfit(date1, close1, 1)) 255 r2 = r2_score(close2, mymodel(date2)) 256 future_close=mymodel(want_date) 257 258 mymodel = numpy.poly1d(numpy.polyfit(date1, preclose1, 1)) 259 r2 = r2_score(preclose2, mymodel(date2)) 260 future_preclose=mymodel(want_date) 261 262 mymodel = numpy.poly1d(numpy.polyfit(open1, close1, 1)) 263 r2 = r2_score(open2, mymodel(close2)) 264 future_close1=mymodel(future_open) 265 mymodel = numpy.poly1d(numpy.polyfit(high1,close1 , 1)) 266 r2 = r2_score(high2, mymodel(close2)) 267 future_close2=mymodel(future_high) 268 mymodel = numpy.poly1d(numpy.polyfit(low1, close1, 1)) 269 r2 = r2_score(low2, mymodel(close2)) 270 future_close3=mymodel(future_low) 271 mymodel = numpy.poly1d(numpy.polyfit(preclose1, close1, 1)) 272 r2 = r2_score(preclose2, mymodel(close2)) 273 future_close4=mymodel(future_preclose) 274 print((future_close+future_close1+future_close2+future_close3+future_close4)/5) 275 276 277 ###################################################### 278 279 280 pre = pandas.read_excel("训练集.xlsx", usecols=[7]) 281 pre_list = pre.values.tolist() 282 futclose1 = [] 283 for s_list in pre_list: 284 futclose1.append(s_list[0]) 285 pre = pandas.read_excel("测试集.xlsx", usecols=[7]) 286 pre_list = pre.values.tolist() 287 futclose2 = [] 288 for s_list in pre_list: 289 futclose2.append(s_list[0]) 290 291 mymodel = numpy.poly1d(numpy.polyfit(open1, futclose1, 1)) 292 myline = numpy.linspace(1500, 2600) 293 matplotlib.pyplot.scatter(open1, futclose1) 294 matplotlib.pyplot.plot(myline, mymodel(myline)) 295 #matplotlib.pyplot.show() 296 #print(r2_score(futclose1, mymodel(open1))) 297 298 mymodel = numpy.poly1d(numpy.polyfit(high1, futclose1, 1)) 299 myline = numpy.linspace(1600, 2600) 300 matplotlib.pyplot.scatter(high1, futclose1) 301 matplotlib.pyplot.plot(myline, mymodel(myline)) 302 #matplotlib.pyplot.show() 303 #print(r2_score(futclose1, mymodel(high1))) 304 305 mymodel = numpy.poly1d(numpy.polyfit(low1, futclose1, 1)) 306 myline = numpy.linspace(1500, 2500) 307 matplotlib.pyplot.scatter(low1, futclose1) 308 matplotlib.pyplot.plot(myline, mymodel(myline)) 309 #matplotlib.pyplot.show() 310 #print(r2_score(futclose1, mymodel(low1))) 311 312 mymodel = numpy.poly1d(numpy.polyfit(close1, futclose1, 1)) 313 myline = numpy.linspace(1500, 2600) 314 matplotlib.pyplot.scatter(close1, futclose1) 315 matplotlib.pyplot.plot(myline, mymodel(myline)) 316 #matplotlib.pyplot.show() 317 #print(r2_score(futclose1, mymodel(close1))) 318 319 openx=float(input("输入今日开盘价:\n")) 320 highx=float(input("输入今日最高价:\n")) 321 lowx=float(input("输入今日最低价:\n")) 322 closex=float(input("输入今日收盘价:\n")) 323 mymodel = numpy.poly1d(numpy.polyfit(open1, futclose1, 1)) 324 r2 = r2_score(open2, mymodel(close2)) 325 future_close1=mymodel(openx) 326 mymodel = numpy.poly1d(numpy.polyfit(high1,futclose1 , 1)) 327 r2 = r2_score(high2, mymodel(close2)) 328 future_close2=mymodel(highx) 329 mymodel = numpy.poly1d(numpy.polyfit(low1, futclose1, 1)) 330 r2 = r2_score(low2, mymodel(close2)) 331 future_close3=mymodel(lowx) 332 mymodel = numpy.poly1d(numpy.polyfit(close1, futclose1, 1)) 333 r2 = r2_score(futclose2, mymodel(close2)) 334 future_close4=mymodel(closex) 335 print("预测明日收盘价为:") 336 print((future_close4+future_close3+future_close2+future_close1)/4)
四、问题及解决方案
1.使用beautifulsoup爬取股票信息仅能捕获当天的信息
解决:①通过pandas_datareader库的方法爬取股市数据(pandas_datareader是一个能读取各种金融数据的库)②引入baostock库(提供大量准确、完整的证券历史行情数据、上市公司财务数据)
2.pandas写入excel提示FutureWarning: As the xlwt package is no longer maintained
解决:由于xlwt软件包不再维护,xlwt引擎将在未来版本的pandas中删除。这是pandas中唯一支持xls格式写入的引擎。安装openpyxl并改为写入xlsx文件。
3.Matlab运行文件时报告在当前文件夹或MATLAB路径中未找到文件。
解决:MATLAB不推荐使用 csvread。
M = csvread(将逗号分隔值 (CSV) 格式化文件读入数组filename)M中。该文件只能包含数值。
M = csvread(从行偏移量filename,R1,C1)R1和列偏移量C1开始读取文件中的数据。例如,偏移量R1=0、C1=0指定文件中的第一个值。
M = csvread(仅读取行偏移量filename,R1,C1,[R1C1R2C2])R1和R2及列偏移量C1和C2界定的范围。另一种定义范围的方法是使用电子表格表示法(例如'A1..B7')而非[0 0 6 1]。
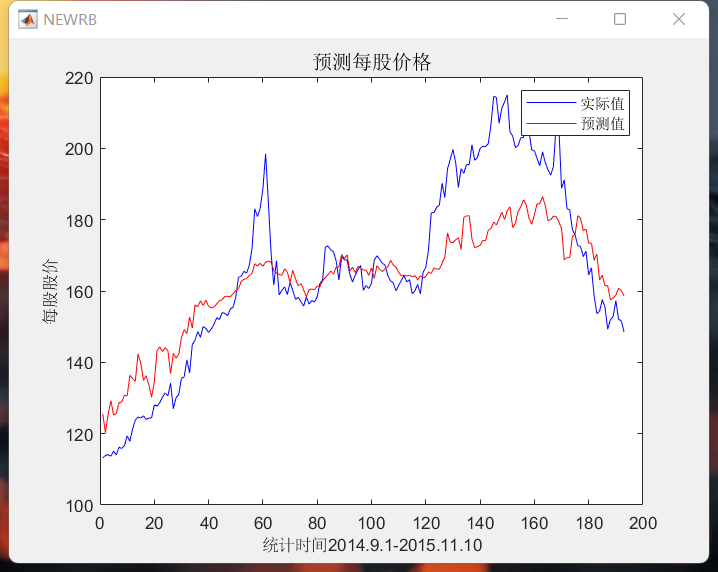
五、实际效果
六、课程总结
“人生苦短,我用Python!”python是一门非常有潜力的高级语言,完全面向对象的语言,历经多年的发展,其在编程上发挥着越来越大的作用。从print(“hello world”)到做期末作业的大项目,在这学期中,通过选修python课上的基础知识学习,我对python也的认识也相较于第一学期更加深入。在本学期同时学习python和C,难免想将二者做对比:python的语句更简洁,更通俗易懂,利用缩进设置语句嵌套更清晰,而且python的变量不需要提前去定义,为pythoner创造了极度舒适的编程环境,而C语言步骤繁琐,利用{}来设置语句嵌套会有些许不直观,但for循环等方面C语言还是更胜一筹。而随着近几年来的发展,python的受欢迎度也越来越高,而它的运用的领域也是越来越多,比如机器学习和大数据等领域,python都是在其中扮演者重要的角色。内容过多不再一一赘述,简单列举些Python的用法:
1、列表相当于动态数组,元组相当于静态数组。
2、字典类型十分方便,在python直接以基本数据类型的方式实现。
3、变量不用定义类型,直接赋值即可。
4、python中没有自增运算符和自减运算符。
5、身份运算符is与==有区别,is比较两个变量的身份(内存地址)是否相等,==比较两个变量的值是否相等。
6、集合是无序的,所以{1,2,3}=={3,2,1}为true;元组和列表是有序的,所以(1,2.,3)==(3,2,1)为false。
7、python依靠缩进区分代码块,而不是{ }。
8、if-else语句、while语句中有冒号:。
9、只存在形式上的常量,将变量名全大写当作常量。
10、没有switch,可以用elif代替,相当于else if。
11、while可以与else搭配使用,for也可以与else搭配,但很少使用。
12、for循环的格式是for target_list in expression_list,循环时target_list会自增,其他语言中for(int i=0;i<=10;i++)可以用for x in range(0,10)代替。
13、range(0,10)表示0到9。range(0,10,2)将步长设为2,表示的是0、2、4、6、8。range(10,0,-1)表示的是10到1。
range()格式为range(start, stop[, step]),
start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5;
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1);
关于导入:
14、在一个文件夹里创建_init_.py,可以使python将该文件夹当作一个包。导入模块使用import,可以加上as关键词。
15、导入模块中单个或多个变量可以使用form … import …(此处可用通配符*)。导入某一模块时会执行该模块的所有代码。要注意避免循环导入。
16、每个模块有内置的变量:__name__是模块的完整名称,__package是模块所在的包的名称,__file__是模块的绝对路径,__doc__是该模块的注释内容。但是入口文件的__name__会被强制更改为__main__,入口文件也不属于任何包,file也会变成自身文件名而不是绝对路劲。
17、逻辑运算符and、or、not用于操作和返回布尔值,但非布尔类型的值也可以被认为是布尔值从而使用逻辑运算符,逻辑运算符也可以返回非布尔类型的值,等同于其他语言中先用if语句做判断,然后确定返回某一个值。int、float类型的值不为零则认为是True,字符串不为空也被认为是True。当操作值不是布尔值时,and与or的返回规律如下:先判断该表达式返回的布尔值是True还是False,再在操作值中寻找能转化为该布尔值的值,该值即为表达式真正返回的值;若两个操作值都符合条件,则and返回后面的值,or返回前面的值。如1 and 2返回2,1 or 2 返回1。Python中没有&与|。
关于函数:
18、python中定义函数时不用指定函数返回值的类型,通通用def。参数列表可以没有,列表中的变量也不需要定义类型。后面依然要带上冒号:。区分代码块依然靠缩进而非{}。
19、函数的返回结果可以是多个,可以使用return A,B。接受返回值时可以直接用多个变量接受
20、序列解包是python一大特点。执行d=1,2,3,python会自动将d整合为一个序列(数组),变成[1,2,3]。再执行a,b,c=d, python会自动将序列解包,相当于a=1,b=2,c=3。
21、在调用函数时,可以在函数的参数列表中利用表达式赋值(顺序可以与定义函数时的形参顺序不同)
22、在定义函数时,可以在参数列表中定义默认参数,例如def add(x,y=1):……,调用时只需要输入一个参数值即可。注意定义和调用时在顺序上默认参数必须在非默认参数的后面,调用时也可以用关键字参数修改默认值。
23、python中也遵循变量作用域的规则,但不存在块级作用域,因此for循环中定义的变量可以直接在循环外调用。
24、python中全局变量的作用域是所有模块。
关于类:
25、实例化一个类时不需要用new,如student=Student(),而非student= new Student()。
26、在类中,变量分为实例变量和类变量,方法分为实例方法、类方法和静态方法。
27、定义类时,定义类中的实例方法无论是否需要传参,参数列表都必须有self。定义类中的类方法无论是否需要传参,参数列表都必须有cls,并在方法的上一行加上@classmethod
28、构造函数的模板为def __init__(self):……, 构造函数的调用也是自动的,同样,在定义构造函数时修改参数列表,在构造函数给成员变量赋值,可以在实例化传入不同的初始值。
29、在定义实例方法时,访问实例变量用self.变量名,访问类变量用self.__class__.变量名;在类外,访问对象的实例变量用对象名.变量名,访问类变量用类名.变量名。
30、在定义类方法时,访问类变量用cls.变量名。在类外调用类方法时用类名.方法名或者对象名.方法名(建议前者)。
31、定义静态方法要在上一行加@staticmethod。
32、类中变量名和方法名以双下划线__开头则为私有的,否则为公开的(构造函数除外)。Python中没有public和private。
33、关于继承,在定义子类的括号里加入父类的名称即可继承。子类的构造函数需要显式地通过super调用父类的构造函数相比较C、Java这种大型语言,Python轻便、灵巧而且入门比较快。
……
……
七、感想及建议
这一学期跟随着王老师学习了python,收获颇丰,受益匪浅。王老师的教学水平很高,总是能将复杂晦涩抽象的东西简单化,让我对其有更加深入的理解,听过王老师讲的最到的一个词就是“例如”。此外,王老师平易近人,始终带着微笑给我们传授知识,表白、刷屏、爬取美女图片的代码更是“实用性”极强,这让我十分喜欢上王老师的课,在获取知识的同时收获快乐。因为大一上学期的自学python让我有了一定基础,在课程前期的学习中比较轻松。但随着学习内容的深入,我开始渐渐有些难以跟上老师教学的步伐了。由于基础不够扎实,总是会遇到各种各样的问题,虽然云班课中的教学资源非常充足,但过多的视频学习资源同时让人生畏,难以提起学习积极性来。在上课时,我总觉得有些知识点还没弄透就学到了下一章节,对于基础不好的同学不够友好。所以希望王老师能够调整上课节奏速度,对于前几节较为基础的课来说可以加快速度,而后来难度较大的课可以放慢节奏,同时布置一些练习题以巩固学习成果,使同学们查漏补缺。在这个磕磕绊绊的学习过程中,跟随着老师的脚步,对python各个方面的内容都进行了一定方面的学习,进行了很多的编程实践,虽然没有完成很庞大的项目,但是在课程学习的过程中,我掌握了许许多多的知识,收获非常大,也体会到了python写脚本、做项目的快乐。对于我来说,能够亲手实现一些以前从来没有编写过的程序确实是满满的成就感。最后,希望自己能够在以后的时间中,继续学习python,写出更多实用的程序,在python学习之路上继续前行,感谢王老师的辛勤付出及一个学期的陪伴。


本文来自博客园,作者:{HYHr},转载请注明原文链接:https://www.cnblogs.com/dishearten/p/16292401.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号