Java基础篇之——集合
我们常用的数组是非常的方便的:
int [ ] arr = {9,6,11,3,5,12,8,7,10,15,14,4,1,13,2};
此时我们得到了一个arr的数组,它是构成了我们最基本的数据结构。
第一章:基础数据结构
第一节:理解数组
在这里我们必须理解数组在内存中的存储方式是连续的,何为连续?
张三和张三的老婆、女儿去看电影,选座位的时候肯定要求座位是连坐,A座1号、A座2号、A座3号。
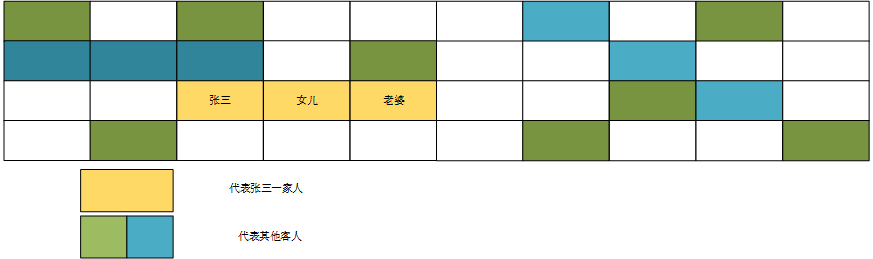
形象一点的话可以如上图;
我们直到,数组这玩意是不可以扩增的,张三是可以看电影途中离开上厕所,但是电影放映中想让他表妹过来一起观看电影,这种情况不允许,那该怎么办呢?
删除该数组,重新找一片足够容纳新人员的位置,如下图:
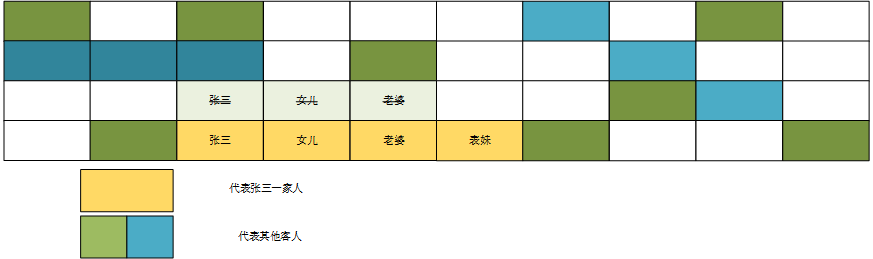
我们把原来位置上的数据进行了删除,重新找了块地方,刚刚好容纳四个人连坐,这就是数组的增加,
如果需要删除/增加数组内的数据,你必须将数组重新安排到合理的位置,所以数组的增删很低效!
如果去寻找张三的位置,你只需要知道他座位号在那里就行了,所以不管你是找张三还是张三的老婆,只要知道他们的座位号就等于找到了他们,这也是数组中的索引,所以数组的查找很高效!
第二节:理解链表
相信我们都玩过回形针

大家应该都玩过回形针,一串一串在一起,如果你玩过,恭喜你已经理解了一半的链表了,因为链表在底层数据的原理就是和回形针一样,我们通过这里来理解链表:
首先数组在内存中的地址必须是连续的,这导致它在增加,删除的时候需要不断地寻找内存中地位置,但是链表不需要如此麻烦,它存储的除了数据信息以外,还有下一条数据的地址,什么意思:
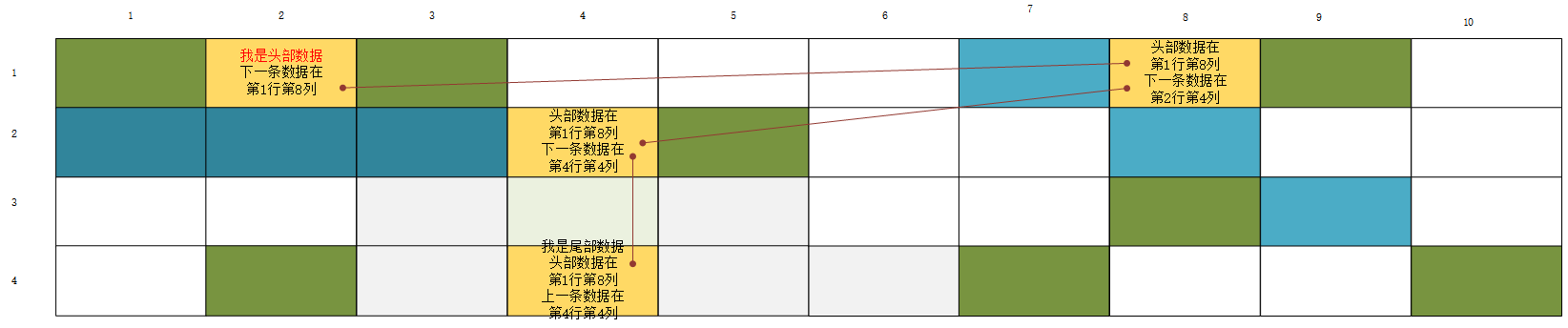
没错,每个数据中存储了起码4样最核心的数据:
1.头部数据的位置
2.尾部数据的位置
3.下一条数据的位置
4.上一条数据的位置(双向链表特有)
这样如此,链表就形成了,那么我们就可以推断出链表有怎样的特性?
1.修改数据只需要修改上一条数据或者下一跳数据的位置就可以了,所以它的修改速度很快。
2.每次查询都要从头部数据/尾部数据开始查找,一层一层向下探寻,所以它的查找速度慢。
实际上链表有两种:单向链表和双向链表,其实也很好理解,单向链表只包含下一条数据的位置,双链表是既包含下一条数据的位置,又包含上一条数据的位置,就这个区别。
那么具备了数组和链表的基础知识,恭喜你踏入了数据结构的入门,这些简单的基本知识根本无需背诵。现在,我们开始理解集合架构:
第二章:集合框架
这是我早期画的一张集合框架的图,凑合着看吧:
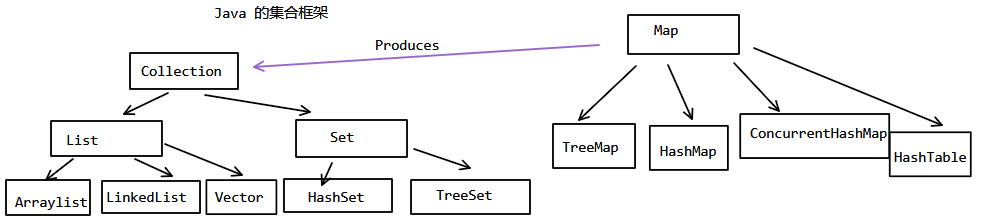
List接口的特点:有序且连续,可以重复的。Set接口特点:无序的,不可以重复的。
第一节:理解ArrayList
首先我们从ArrayList入手,它实现了List,我们了解它的特点:
1.有序且连续,元素可以重复
2.使用索引来访问属性
3.数据类型可以不同(在不泛型的情况下,一般来说我们都是泛型的)
4.查询速度快(在内存中的存储位置是连续的,使用索引查询所以速度快)
5.数组动态化(位置不足时自动增加当前容量的50%空位)
缺点:
1.不使用泛型的情况下,取出的数据都是Object类型(所以泛型是硬性条件咯~)
2.增删改效率低(每次增加/删除会更改内存位置,如果是扩增那么会在原来的容量上加50%的空位,如果是删除,所有元素都要重新排列)
创建方法
ArrayList arraylist = new Arraylist();
添加方法
arraylist.add(100);
获取方法
Object obj = arraylist.get(0);
不泛型可不行,我们需要规定取出来的是什么类型的对象,不然每次都要转换。
ArrayList<String> list = new Arraylist<>();
Array.add("add");
Array.add("hello");
下面是数组的主要方法:
|
方法 |
解释 |
|
size() |
获取集合中元素的个数 |
|
add(E e) |
添加一个元素 |
|
add(int index,E e) |
指定位置插入元素,index的取值范围0~size() |
|
get(int index) |
根据索引位置,获取元素对象,index取值范围:0~size()-1 |
|
addAll() |
指定集合的Iterator返回的顺序将指定集合中的所有元素追加到此列表的末尾。 |
|
clear() |
清空集合 |
|
isEmpty() |
判断是否为空集合,是则返回true |
|
remove(int index) |
根据索引位置,删除元素对象 |
|
set(int index,E e) |
指定索引位置,替换元素对象 |
|
subList(int fromIndex,int toIndex) |
索引从fromIndex开始直到toIndex结束,返回一组新的数组。 |
|
contains(Object o ) |
如果此列表中包含指定元素,则返回 true。(实际上是使用equals对应) |
|
indexOf(Object o) |
返回指定元素在列表中的索引,如果集合中并不存在,则返回-1 |
|
remove(Object o) |
从列表中删除第一次出现的元素。 |
|
forEach() |
给数组的每一项都进行传入函数操作。 |
|
Iterator() |
返回列表中的元素迭代器。 |
|
listIterator(int i) |
返回列表中的列表迭代器,可传入第一参数返回指定位置开始迭代器 |
第二节:理解LinkedList
LinkedList
链表的特点也有很多,最大的特点是它的不连续内存空间
1.内存地址不连续,各个元素指针包含上一个元素指针和下一个元素的指针
2.增删速度快(只需要更改上一个元素和下一个元素的引用地址就行,自由度高)
3.使用索引来访问元素
缺点
1.查询速度慢(需要逐个查询下一个或者上一个的元素的指针)
2.需要泛型来指定元素
建立方法和ArrayList相同,这里不再演示了
|
方法 |
解释 |
|
element() |
获取第一个元素 |
|
get(int i) |
获取索引元素 |
|
set(int i,E e) |
替换指定位置的元素 |
|
add(int i,E e) |
增加元素到末尾,可传入第一参数指定加入的索引位置 |
|
addAll(int i,Collection c) |
按照指定元素的迭代器,将集合中的所有元素追加到指定集合的末尾,可传入第一参数指定加入的所有位置 |
|
indexOf(E e) |
获取元素索引 |
|
push(E e) |
栈方法,将元素推入到集合末尾 |
|
pop(E) |
栈方法,将末尾元素从集合中弹出到栈中 |
|
remove(O o) |
删除第一个元素,可传入第二参数删除指定元素 |
|
clear() |
清空元素 |
|
toArray(new String[0]) |
转换为数组 |
有关于排序,List中已经给出了sort的默认实现,我们只需要传入一个比较器就可以了但它不在本章的讨论范围,传入的比较器可以是函数形式也可以是匿名比较器
ArrayList<Integer> list = new ArrayList<>();
list.sort((o1, o2) -> Integer.compare(o1,o2));如果对象尚未实现compare方法,自然也是无法传入排序的,实际上只需要传入-1(代表这个参数1小于参数2),0(参数相减等于0代表相等),1(参数1大于参数2),就可以判断出参数位置了
/**
* @param x 代表 参数1
* @param y 代表 参数2
* @return 0代表两数相等
1代表参数1大于参数2
-1代表参数1小于参数2
* @since Integer源码,来自JDK-1.7
*/
public static int compare(int x, int y) {
return (x < y) ? -1 : ((x == y) ? 0 : 1);
}不深入探究了,玩法还是蛮多的
第三节:理解HashSet
HashSet集合接口
特点
1.无序的存储方式
2.不允许项目重复(根据hash算法来存储,所以能筛选出重复内容)
3.允许null值
4.底层使用的是散列表,使用hashcode作为key,内容作为value(New Object)存储
如果新增了一个元素
首先验证hashcode是否相等,如果相等则对比底层的每个元素是否equals()对象。
这里就比较高级了,有很多很多名词,似乎从来没见过,hashcode是什么?散列表又是什么玩意?不着急我们一 一说明
首先HashSet 实际上就是HashMap的一种变种,它在存储对象的时候,对象也必须实现两种必备的方法:
equals & hashcode
@Override
public int hashCode() {
return super.hashCode();
}
@Override
public boolean equals(Object obj) {
return super.equals(obj);
}为什么要实现hashCode?在HashMap存储对象的时候,会计算对象的HashCode值,所以必定会用到对象的hashCode方法,不去实现它你是没办法存储到HashMap中的,例如Null对象,它没有hashcode,自然无法作为键存储。
为什么要实现equals?如果你的对象计算出来的HashCode嘿,巧了,和我HashMap中的某一个对象的HashCode相同(我们称之为hash碰撞),那么我们就要比较两者是不是同一个对象,如果不是,那么会存储到同一个hash索引下(它是一个链表)。
理解就可以了,HashSet的内容你会在理解HashMap的时候茅塞顿开!
我们看一部分HashSet的源码:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
@java.io.Serial
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
}你看HashSet底层是不是使用了HashMap?我们可以看到它所有的方法几乎都是使用的HashMap的方法:
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}😂移除就是HashMap的移除,增加就是HashMap的增加,HasMap 是Key,Value键值对的形式存储的,你不学HashMap怎么用HashSet呀,别着急,你就把它当作List用,它的特点就是不能存储重复值,其它功能都是一样的。
你要问我HashMap的数据结构是什么?动态数组+链表实现的,极其罕见的情况下链表会转换为红黑树,是不是一脸蒙圈,别着急,目前的阶段只是将它当作去除重复值的List即可,HashMap我们以后会慢慢解析,它特性较多,也是面试重灾区。
建立HashSet:
HashSet<String> set = new HashSet<>();
|
方法 |
解释 |
|
add() |
增加条目到set中 |
|
size() |
返回元素个数 |
|
remove() |
移除某个元素 |
|
contains(O o) |
如果集合中包含某个对象,就返回true |
反正HashSet的方法就是HashMap的方法,所以额外的,我们简单学习下HashMap的使用方法:
特点
1.查询速度很快(其实就是数组,索引是hashCode)
2.底层是散列表无序存储(hashCode算出来的索引就是乱的,所以没法保证顺序)
3.Key不允许重复(如果重复,则覆盖原来的值。判断依据是判断key的hashcode和equals是否一致)
新建立HashMap
HashMap<Integer,String> map = new HashMap<>();
|
方法 |
解释 |
|
put(k,v) |
键入一对值进入map |
|
get(k) |
键入key,返回value值,如果不存在,则返回true |
|
containsKey(k) |
判断是否包含输入的键 |
|
containsValue(v) |
判断是否包含输入的值 |
|
remove(k) |
输入一个key,移除其映射,返回其对象。可传入第二参数,value值是否对应。 |
|
keySet() |
将所有的键以集合的方式返回 |
|
values() |
将所有的值以Collection的方式返回 |
|
entrySet() |
将所有的键值对以Set<Map.Entry<k,v>>的形式返回。 |
|
getKey() |
返回Entry的键 |
|
getValue() |
返回Entry的值 |
|
forEach() |
传入一个函数,使其对键、值得每一项做一个操作。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号