数据采集与融合技术作业1
作业1
(1)用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
在数据时代,获取权威的高校排名数据对升学参考、研究分析等场景都很有价值。软科中国大学排名是国内极具影响力的高校排名之一,本文将通过 Python 代码实现 2020 年软科中国大学排名数据的爬取与保存,带你走进简单实用的网页爬虫世界。
一、爬取前的准备:工具与环境
核心库介绍
- BeautifulSoup:用于解析 HTML 页面,快速提取目标数据,是网页爬虫的常用解析工具。
- urllib.request:Python 内置的 HTTP 请求库,无需额外安装,可直接用于获取网页内容。
- os:用于创建本地文件夹,处理文件路径相关操作。
二、实验完整过程
导入所需库
from bs4 import BeautifulSoup
from urllib import request
import os
使用 try-except 捕获异常,避免程序因错误中断。先判断是否存在 "download_uni" 文件夹,不存在则创建,用于存储爬取的数据文件;随后以 UTF-8 编码打开文件,准备写入爬取到的排名信息。
try:
if not os.path.exists("download_uni"):
os.mkdir("download_uni")
f=open("download_uni/university","w",encoding="utf-8")
指定目标 URL 为 2020 年软科中国大学排名页面,通过 urlopen 发送 GET 请求获取网页响应,读取响应内容后解码为 UTF-8 格式的字符串,再用 BeautifulSoup 结合 lxml 解析器对 HTML 进行解析,生成可操作的解析对象。
url="http://www.shanghairanking.cn/rankings/bcur/2020"
resp=request.urlopen(url)
html=resp.read().decode()
soup=BeautifulSoup(html,"lxml")
通过观察网页结构,可以发现所需的数据都在一个class 为 "rk-table" 的元素中
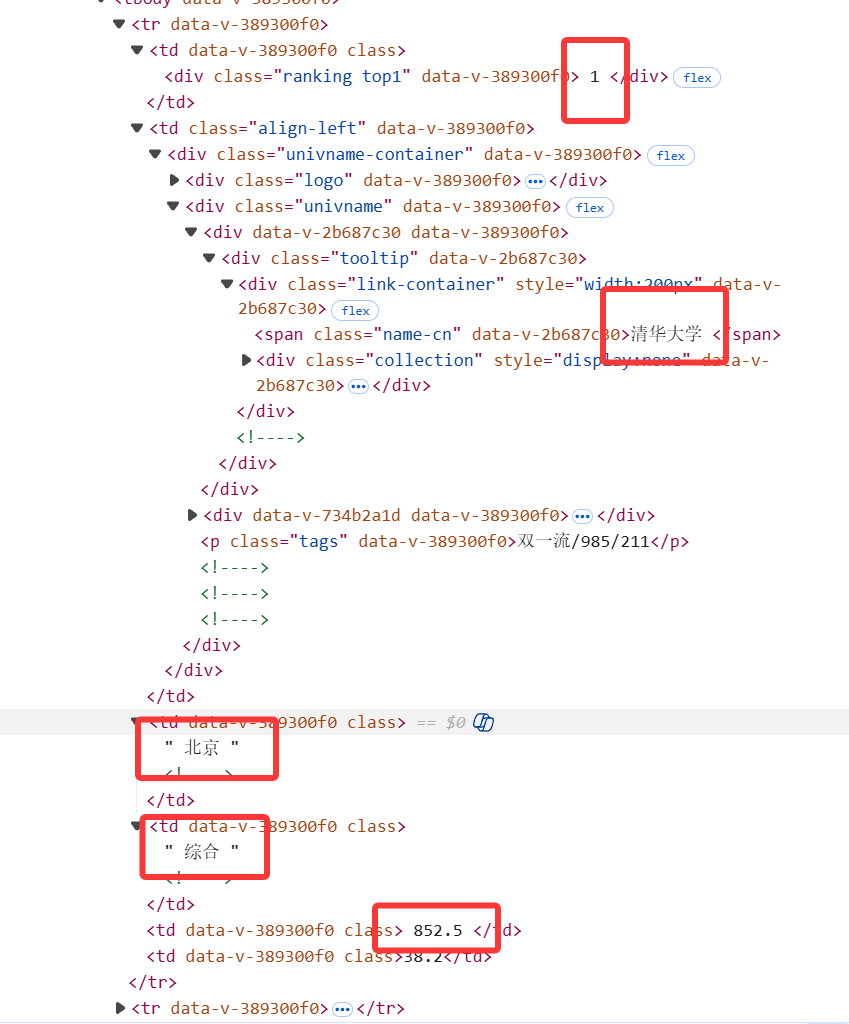
通过 CSS 选择器定位 class 为 "rk-table" 的表格,提取所有行(tr 标签)。若未找到目标表格,打印提示信息并退出程序,避免后续代码报错。
trs=soup.select("table[class='rk-table'] tr")
if not trs:
print("未找到排名表格")
exit()
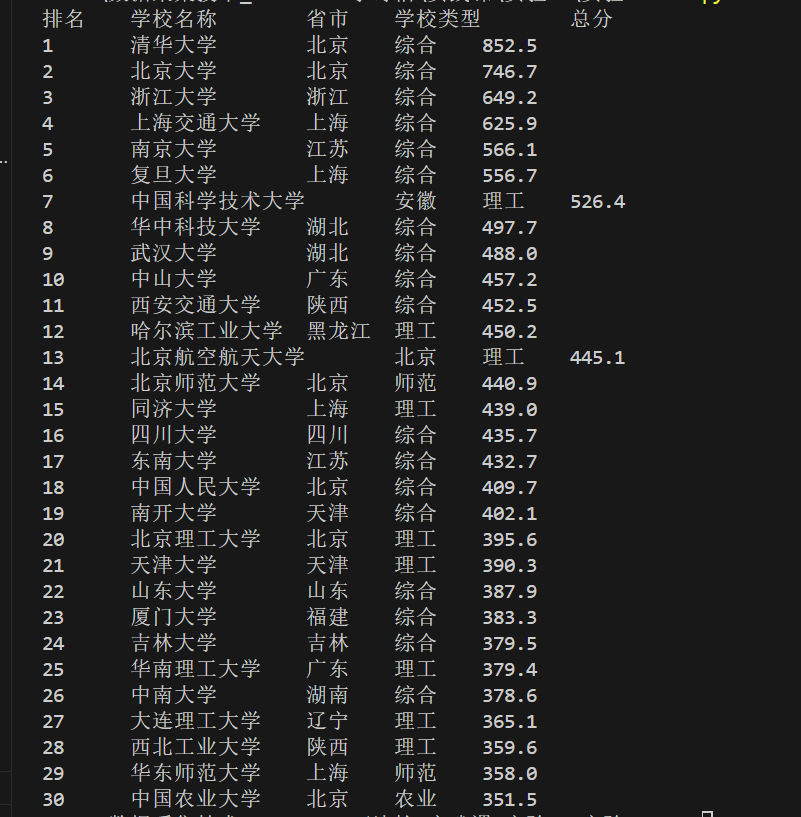
先写入表格表头(排名、学校名称、省市、学校类型、总分),并在控制台打印表头。接着遍历表格行(跳过第一个表头行),通过 find_all 提取每行的所有单元格(td 标签),分别提取排名、学校名称等目标数据,用 strip () 去除多余空格。将提取的数据同时打印到控制台和写入文件,最后关闭文件确保数据保存完整。
f.write("排名\t学校名称\t省市\t学校类型\t总分\n")
print("排名\t学校名称\t省市\t学校类型\t总分")
for tr in trs[1:]:
tds=tr.find_all("td")
# 提取排名
rank=tds[0].text.strip()
# 提取学校名称
name=tds[1].find(name="div" ,attrs={"class":"link-container"}).text.strip()
# 提取省市
prov=tds[2].text.strip()
# 提取学校类型
style=tds[3].text.strip()
# 提取总分
grade=tds[4].text.strip()
print(rank+"\t"+name+"\t"+prov+"\t"+style+"\t"+grade)
f.write(rank+"\t"+name+"\t"+prov+"\t"+style+"\t"+grade+"\n")
f.close()
except Exception as err:
print(err)
结果
(2)心得体会
作业1是对照着课本项目《爬取图书网站》写的,我更加熟练BeautifulSoup的使用。
作业2
(1)用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
在电商平台日益发达的今天,我们经常需要对不同商品进行价格比较以获得最优惠的购物体验。本项目将设计一个定向爬虫,爬取某商城中以 "书包" 为关键词的搜索结果,提取商品名称和价格信息,帮助用户快速比价。
一、爬取前的准备:工具与环境
核心库介绍
- requests 库:用于发送 HTTP 请求,获取网页内容
- re 库:用于通过正则表达式解析网页,提取所需信息
- BeautifulSoup:辅助解析 HTML
- Selenium:处理动态渲染页面
二、实验完整过程
小网站
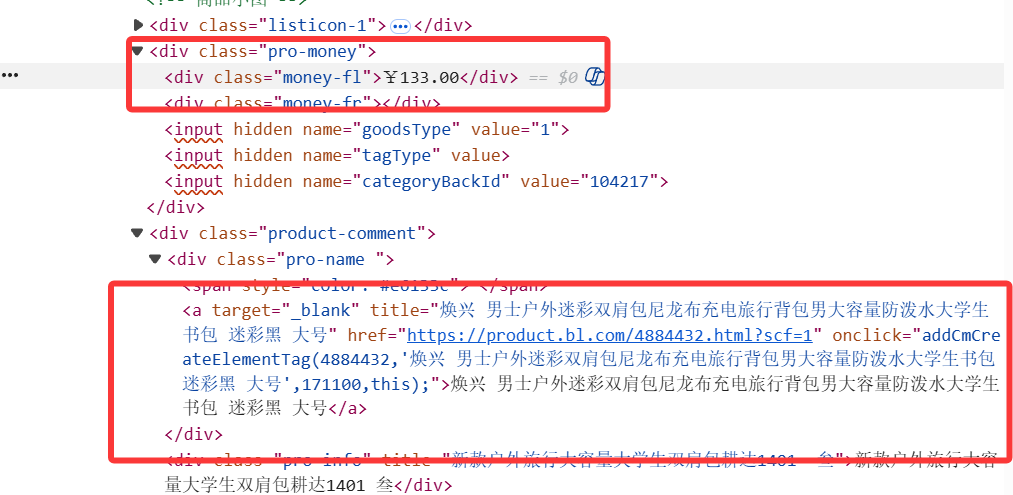
观察网站结构,得到正则表达式
price = re.search(r'<div class="money-fl">¥(\d*.\d*)</div>', html)
name=re.search(r'<a target="_blank" title="([^"]*)"', html)
from urllib import request
import re
try:
url = "https://search.bl.com/k-%25E4%25B9%25A6%25E5%258C%2585.html?bl_ad=P668822_-_%u4E66%u5305_-_5"
resp = request.urlopen(url)
html = resp.read().decode()
price = re.search(r'<div class="money-fl">¥(\d*.\d*)</div>', html)
name=re.search(r'<a target="_blank" title="([^"]*)"', html)
i=1
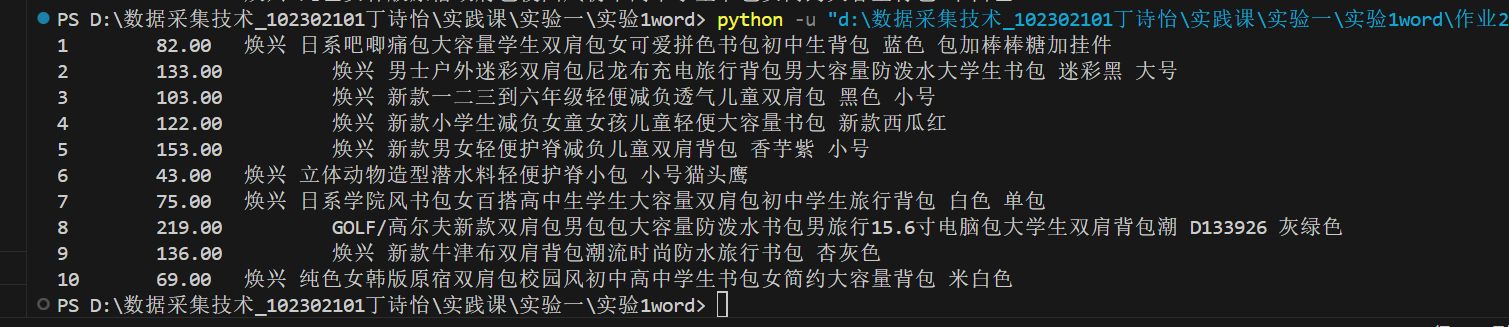
while price!=None and name!=None:
print(i,"\t",price.group(1),"\t",name.group(1))
html=html[name.end():]
price = re.search(r'<div class="money-fl">¥(\d*.\d*)</div>', html)
name=re.search(r'<a target="_blank" title="([^"]*)"', html)
except Exception as err:
print(err)
结果
淘宝
将要爬取的html输出,发现并没有我们所需要的html树结构
from urllib import request
try:
url=url = "https://uland.taobao.com/sem/tbsearch?bc_fl_src=tbsite_T9W2LtnM&channelSrp=bingSomama&clk1=8294ab7a6b5e3f32bb18ef6ea81f248d&commend=all&ie=utf8&initiative_id=tbindexz_20170306&keyword=%E4%B9%A6%E5%8C%85&localImgKey=&msclkid=755f439a279d1844fb1e2b75738ed163&page=1&preLoadOrigin=https%3A%2F%2Fwww.taobao.com&q=%E4%B9%A6%E5%8C%85&refpid=mm_2898300158_3078300397_115665800437&search_type=item&sourceId=tb.index&spm=tbpc.pc_sem_alimama%2Fa.search_manual.0&ssid=s5-e&tab=all"
resp=request.urlopen(url)
html=resp.read().decode()
print(html)
except Exception as err:
print(err)

询问大模型,明白核心问题是淘宝页面是动态渲染的,而爬取的是初始 HTML(只包含加载脚本),但商品数据(价格、名称)是后续通过 JS 动态生成的,正则自然匹配不到内容。
上网找资料,翻阅课本,发现课本第五章使用Selenium解决这个问题,仿写后仍被淘宝反爬,跟着csdn修改代码,使用随机User-Agent池和最常见的请求头。
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36'
]
headers = {
'User-Agent': random.choice(USER_AGENTS),
'Referer': 'https://www.taobao.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive'
}
安装Selenium
pip install Selenium
查看谷歌浏览器版本
下载对应版本的谷歌驱动
把下载好的.exe文件放到py的安装目录下
爬取过程
def parsePage(uinfo, data):
#价格
plt1 = re.findall(r'"Price--priceInt--BXYeCOI">(\d+)', data)
plt2 = re.findall(r'"Price--priceFloat--rI_BYho">([\d.]+)', data)
#名字
soup = BeautifulSoup(data, "lxml")
tlt = soup.find_all("div", attrs={"class": "Title--title--wJY8TeA"})
max_len = min(len(tlt), len(plt1), len(plt2))
for i in range(max_len):
zheng = plt1[i] if plt1[i].strip() else "0"
xiao = plt2[i] if plt2[i].strip() else ".00"
price = zheng + xiao
name_elem = tlt[i].find("span", attrs={"class": True})
name = name_elem.text.strip() if name_elem else f"未知商品_{i+1}"
uinfo.append([i + 1, price, name])
return uinfo
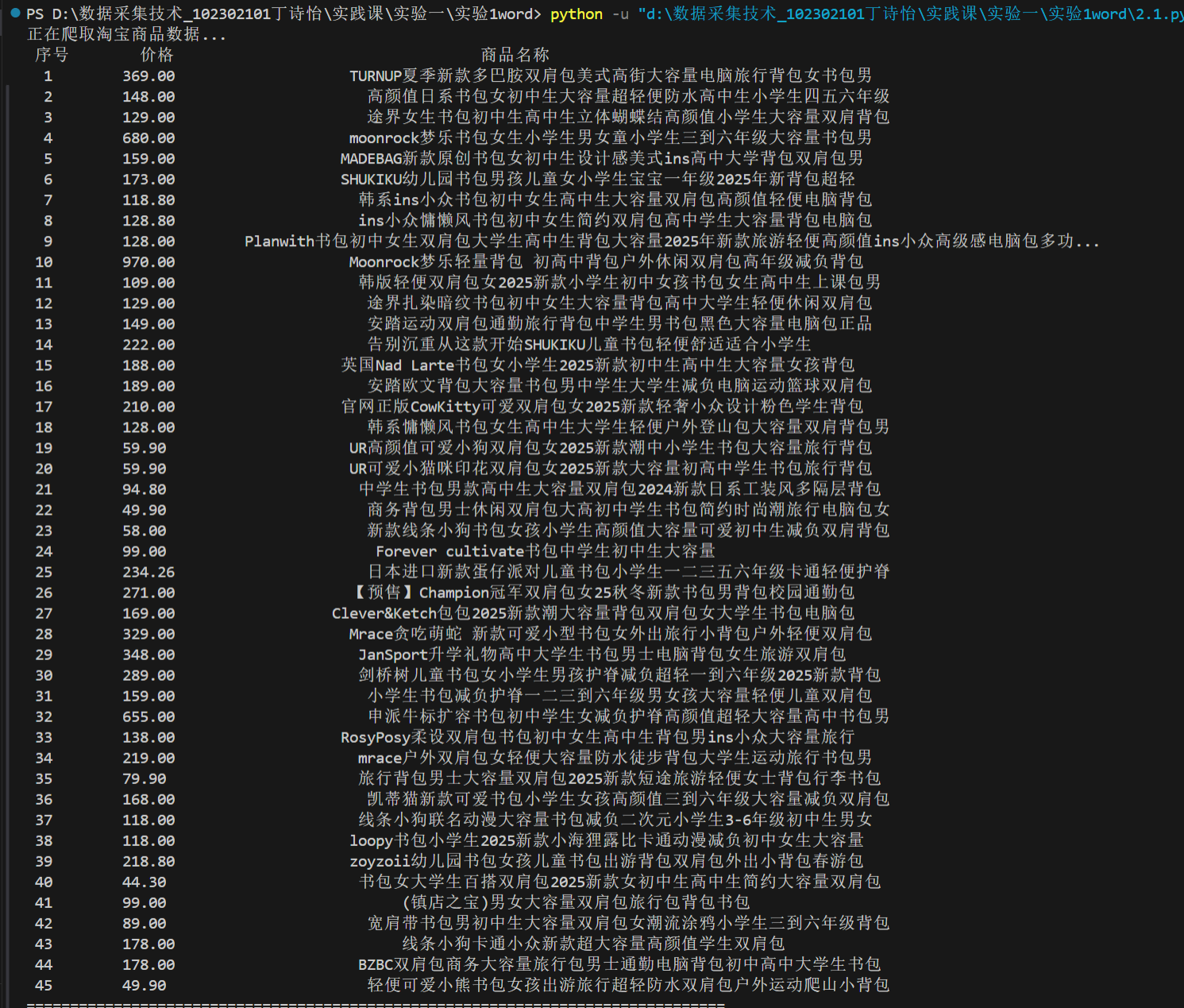
运行结果
完整代码
import re
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import random
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36'
]
def getHTMLText(url):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--disable-blink-features=AutomationControlled') # 隐藏自动化标识
chrome_options.add_experimental_option('excludeSwitches', ['enable-logging'])
chrome_options.add_experimental_option('useAutomationExtension', False)
chrome_options.add_argument(f'user-agent={random.choice(USER_AGENTS)}')
driver = webdriver.Chrome(options=chrome_options)
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})' # 进一步规避反爬
})
try:
driver.get(url)
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "Title--title--wJY8TeA"))
)
data = driver.page_source
except Exception as err:
print(err)
data = ""
finally:
driver.quit()
return data
def parsePage(uinfo, data):
plt1 = re.findall(r'"Price--priceInt--BXYeCOI">(\d+)', data)
plt2 = re.findall(r'"Price--priceFloat--rI_BYho">([\d.]+)', data)
soup = BeautifulSoup(data, "lxml")
tlt = soup.find_all("div", attrs={"class": "Title--title--wJY8TeA"})
max_len = min(len(tlt), len(plt1), len(plt2))
for i in range(max_len):
zheng = plt1[i] if plt1[i].strip() else "0"
xiao = plt2[i] if plt2[i].strip() else ".00"
price = zheng + xiao
name_elem = tlt[i].find("span", attrs={"class": True})
name = name_elem.text.strip() if name_elem else f"未知商品_{i+1}"
uinfo.append([i + 1, price, name])
return uinfo
def printGoodslist(uinfo):
tplt = "{0:^5}\t{1:^12}\t{2:^60}"
print(tplt.format("序号", "价格", "商品名称"))
for i in uinfo:
name = i[2][:55] + "..." if len(i[2]) > 55 else i[2]
print(tplt.format(i[0], i[1], name))
def main():
url = "https://uland.taobao.com/sem/tbsearch?bc_fl_src=tbsite_T9W2LtnM&channelSrp=bingSomama&clk1=8294ab7a6b5e3f32bb18ef6ea81f248d&commend=all&ie=utf8&initiative_id=tbindexz_20170306&keyword=%E4%B9%A6%E5%8C%85&localImgKey=&msclkid=755f439a279d1844fb1e2b75738ed163&page=1&preLoadOrigin=https%3A%2F%2Fwww.taobao.com&q=%E4%B9%A6%E5%8C%85&refpid=mm_2898300158_3078300397_115665800437&search_type=item&sourceId=tb.index&spm=tbpc.pc_sem_alimama%2Fa.search_manual.0&ssid=s5-e&tab=all"
uinfo = []
data = getHTMLText(url)
uinfo = parsePage(uinfo, data)
printGoodslist(uinfo)
if __name__ == '__main__':
main()
(2)心得体会
作业2通过csdn与大模型的帮助,我成功爬取有反爬机制的淘宝网站。通过这个作业,我提前学习了课本第五章内容,并了解到Selenium 能模拟真实浏览器的加载过程,等待 JS 渲染完成后再获取页面内容,是爬取动态页面的常用方法。
作业3
(1)爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
一、爬取前的准备:工具与环境
核心库介绍
- urllib.request
- re:正则表达式库
- os:用于文件和目录操作
- urllib.parse.urljoin:生成完整的图片 URL
二、实验完整过程
观察网页很容易得到如下的爬取逻辑,方法与上面两个实验类似,不再赘述
from urllib import request
import re
import os
from urllib.parse import urljoin
try:
if not os.path.exists("download_img"):
os.mkdir("download_img")
base_url = "https://news.fzu.edu.cn/"
url = "https://news.fzu.edu.cn/yxfd.htm"
resp = request.urlopen(url)
html = resp.read().decode()
ls = re.findall(r'<img[^>]*>', html)
for l in ls:
src_match = re.search(r'src=["\']([^"\']+)["\']', l)
if not src_match:
continue
url_img = src_match.group(1)
if not url_img.lower().endswith(".jpg") and not url_img.lower().endswith(".jpeg") and not url_img.lower().endswith(".png") :
continue
full_img_url = urljoin(base_url, url_img)
try:
img_data = request.urlopen(full_img_url).read()
filename = os.path.basename(url_img)
save_path = os.path.join("download_img", filename)
with open(save_path, "wb") as f:
f.write(img_data)
print(f"已保存图片: {save_path}\n")
except Exception as e:
print(e)
except Exception as err:
print(err)
运行发现有报错信息
[Errno 22] Invalid argument: 'download_img\\10F0677E72A0B0DCCF5F798C6DB_865A6721_1F7.png?e=.png'
[Errno 22] Invalid argument: 'download_img\\0B2EC59649CA13BAC85941A8B12_D497950A_19B.png?e=.png'
[Errno 22] Invalid argument: 'download_img\\9D5EF45533E69056CF06F1A0115_9201CE3A_198.png?e=.png'
图片 URL 中包含特殊字符(如?),导致生成的文件名不符合 Windows 系统的命名规则。Windows 文件名中不允许包含?、*、:等特殊字符,需要对文件名进行清洗处理。
# 定义需要过滤的特殊字符
INVALID_CHARS = r'[\\/:*?"<>|]'
# 提取原始文件名,并清洗特殊字符
raw_filename = os.path.basename(url_img)
# 用正则替换所有不合法字符为下划线(_)
clean_filename = re.sub(INVALID_CHARS, '_', raw_filename)
运行可获得所有JPEG、JPG或PNG格式图片文件
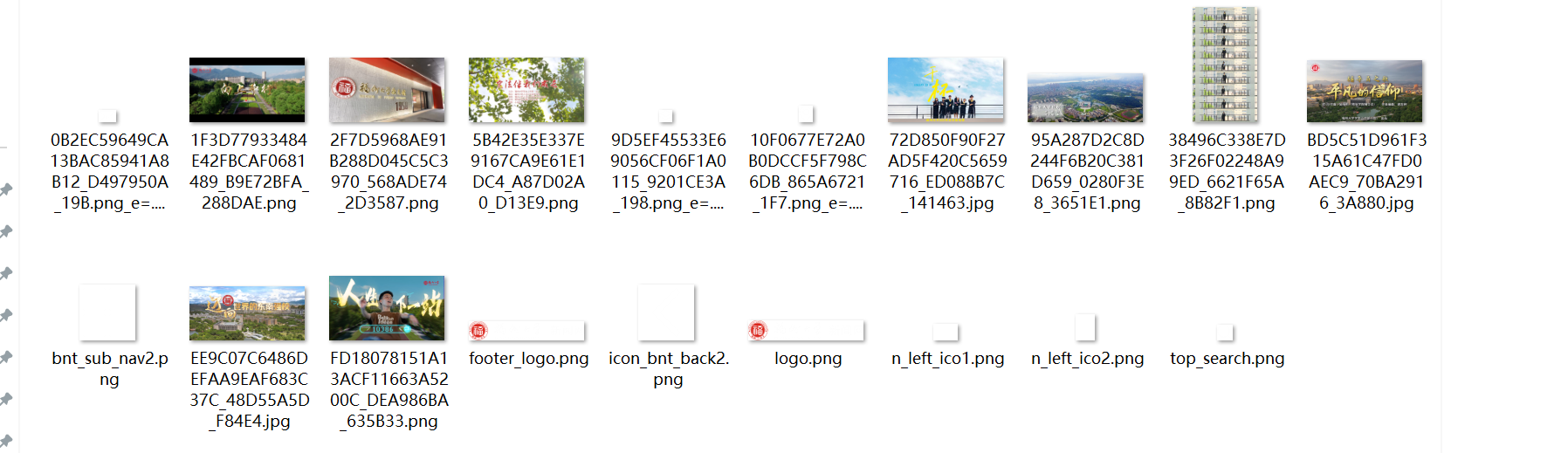
(2)心得体会
作业3是在课上的爬取jpg文件基础上拓展,我学习了如何使用 Python 的标准库来获取网页内容、解析 HTML、提取所需信息并保存到本地。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号