Python网络爬虫规则之Request库入门
Requests库是Python的第三方库,它是目前公认的爬取网页最好的第三方库。Requests库有两个特点,它很简单简单,也很简洁,甚至用一行代码从网页上获得相关的资源。Requests库的更多信息可以在https://requests.readthedocs.io/en/master/上获得。
(1).Requests库的安装
在命令行下使用pip命令安装Requests库,命令pip install requests。注意:需要将Python目录和其目录下的Scripts目录加到环境变量中。
安装完成后,进行一个简单的测试。启动Python自带的IDLE
>>> import requests
>>> r = requests.get("http://www.baidu.com")
>>> r.status_code #状态码
200
>>> r.encoding='utf-8' #更改编码为utf-8
>>> r.text #打印网页内容
'<!DOCTYPE html>\r\n<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8>
<meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=t
ext/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body
link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wra
pper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form i
d=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden
name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hi
dden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=w
d class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submi
t id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com
name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href
=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>
视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.
com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</
a> </noscript> <script>document.write(\'<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=\'+ encod
eURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ \'" name="tj
_login" class="lb">登录</a>\');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="displa
y: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu
.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baid
u.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <
img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>\r\n'
(2).Requests库的7个主要方法
| 方法 | 说明 |
| requests.request() | 构造一个请求,支持以下各个方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTTP网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTTP网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTTP页面提交删除请求,对应于HTTP的DELETE |
1)Requests库的request()方法
request()方法是所有方法的基础方法,它有三个参数method、url和一组控制访问参数**kwargs。其中,method表示通过request()实现的请求方式,;url指获取页面的url链接;**kwargs是13个控制访问参数。
method共有7种请求方式,分别是GET/HEAD/POST/PUT/PATCH/delete/OPTIONS。前6种是HTTP协议对应的请求功能,而OPTIONS事实上是向服务器获取一些服务器和客户端能够打交道的参数,并不与获取资源直接相关,因此我们在平时使用中用的比较少。在这7种请求方式中,如果选定了一种,我们可以使用request()直接实现,也可以用Requests库的对应方法,当然Requests库的对应方法也是基于request()方法封装起来的。
**kwargs共有13个控制访问参数,均为可选项,使用时必须采用命名方式使用。第一个参数是params,是指能够增加到url中的字典或字节序列参数,实例如下:
>>> import requests
>>> kv={'key1':'value1','key2':'value2'}
>>> r=requests.request('GET','http://python123.io/ws',params=kv)
>>> print(r.url)
https://python123.io/ws?key1=value1&key2=value2
第二个参数data,是指字典、字节序列或文件对象,作为Request的内容部分,重点向服务器提供或提交资源时使用,实例如下:
>>> import requests
>>> kv={'key1':'value1','key2':'value2'}
>>> r=requests.request('POST','http://python123.io/ws',data=kv)
第三个参数json,是指JSON格式的数据,它也是作为Request的内容部分,可以像服务器提交,实例如下:
>>> import requests
>>> kv={'key1':'value1'}
>>> r=requests.request('POST','http://python123.io/ws',json=kv)
第四个参数headers,字典类型,是指向某一个url访问时所发起的http的头字段,简单说我们可以用这个字段来定制访问某一个url的http的协议头,实例如下:
>>> import requests
>>> hd={'user-agent':'Chrome/10'}
>>> r=requests.request('POST','http://python123.io/ws',headers=hd)
第五个参数cookies,字典类型或CookieJar,指的是从http协议中解析cookie。
第六个参数auth,元组类型,它是支持HTTP认证功能。
第七个参数files,字典类型,顾名思义它是向服务器传输文件时使用的字段,实例如下:
>>> import requests
>>> fs={'file':open('data.xls','rb')}
>>> r=requests.request('POST','http://python123.io/ws',files=fs)
第八个参数timeout,是指设定的超时时间,以秒为单位,实例如下:
>>> import requests
>>> r=requests.request('GET','http://www.baidu.com',timeout=10)
第九个参数proxies,字典类型,可以为我们爬取网页设定相关的访问代理服务器,可以增加登陆认证,使用这个参数可以有效的隐藏用户爬取网页的源IP地址信息,能够有效的防止对爬虫的逆追踪,实例如下:
>>> import requests
>>> pxs={'http':'http://user:pass@10.10.10.1:1234','https':'https://10.10.10.1:4321'}
>>> r=requests.request('GET','http://www.baidu.com',proxies=pxs)
第十个参数allow_redirects,这个参数是一个开关,表示允不允许对URL重定向,默认为True。
第十一个参数stream,这个参数也是一个开关,表示对获取的内容是否进行立即下载,默认为True。
第十二个参数verify,这个参数还是一个开关,表示是否认证SSL证书,默认True。
第十三个参数cert,是保存本地SSL证书路径的字段。
理解了request()方法后面的方法就容易理解很多。
2)Requests库的get()方法
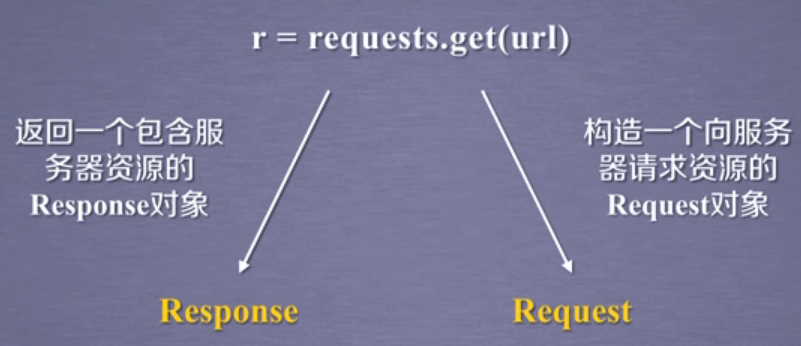
get()方法是Requests库的最常用方法。获得一个网页最简单的一行代码就是r=requests.get(url),这里我们通过给定get()方法和url参数来构造一个向服务器请求支援的Request对象,这个对象是Requests库内部生成,另外requests.get()函数返回内容用变量r来表示,这个r是一个包含从服务器返回的所有相关资源的Response对象。
requests.get()函数的完整使用方法有三个参数,包括url,params和一组更多的相关参数,具体表现为requests.get(url,params=None,**kwargs)。其中url是获得页面的url链接;params指的是在url中增加的额外参数,它可以是字典或字节流格式,是一个可选参数;**kwargs是12个控制访问的参数,它也是可选参数,具体可以看request()方法中的解释。

如果打开Requests库get()方法源代码,可以看到get()方法实际使用了request()方法来封装。也就是说Requests库一共提供了7个常用方法,除了第一个request()方法是基础方法外,其他的6个方法都是通过调用request()方法来实现的。事实上可以认为Requests库只有一个方法,就是request()方法,但是为了使大家编写程序更加方便,所以它提供了额外6个方法。

在r=requests.get(url)这一行代码中,最重要的两个对象是Response对象和Request对象,其中获得网络内容相关的Response对象又是重中之重,它包含了爬虫返回的全部内容。
>>> import requests
>>> r=requests.get("http://www.baidu.com")
>>> print(r.status_code) #检测状态码
200
>>> type(r) #检测r的类型
<class 'requests.models.Response'>
>>> r.headers #返回get()请求获得的头部信息
{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip',
'Content-Type': 'text/html', 'Date': 'Tue, 12 May 2020 14:02:02 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:36 GMT', 'Pragma':
'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
Response对象包含了服务器返回的所有信息,同时也包含了我们去请求的request()信息。在Response对象中最常用的有如下五个属性,这五个属性是访问网页最常用和最必要的属性。
| 属性 | 说明 |
| r.status_code | HTTP请求的返回状态,200表示连接成功 |
| r.text | HTTP响应内容的字符串形式,即url对应的网页内容的字符串形式 |
| r.encoding | 从HTTP header中猜测的响应内容的编码方式 |
| r.apparent_encoding | 从响应的内容文本中分析出来的编码方式,是备选编码方式 |
| r.content | HTTP响应内容的二进制方式,例如图片 |
在使用get()方法获取网上资源的时候,有一个基本的流程。首先使用r.status_code来检查返回的Response对象的状态,如果返回的状态码是200,那么就可以使用r.text,r.encoding,r.apparent_encoding,r.content等属性去解析返回的内容,如果返回的状态码是非200,那么说明这次url的访问因为某种原因出错或产生异常了。
r.encoding的编码方式是从HTTP header中的charset字段获得,如果HTTP header中有这样一个字段,说明访问的服务器对资源的编码是有要求的,而这样的编码会获得回来并存于r.encoding中。但是并不是所有的服务器对资源编码都有相关要求,如果HTTP header中不存在charset,则默认将编码设为ISO-8859-1,这个默认编码并不能解析中文。所以Requests库提供了另一个备选编码,也就是r.apparent_encoding,这个编码是根据HTTP的内容部分去分析内容中出现文本可能的编码形式。原则上来说r.apparent_encoding的编码比r.encoding更加准确,当我们使用r.encoding并不能正确的解码返回的内容时,我们要用r.apparent_encoding来解码相关的信息。
3)Requests库的head()方法
head()方法完整形式是requests.head(url,**kwargs),url是获得页面的url链接,**kwargs是13个控制访问参数。
>>> import requests
>>> r=requests.head('http://httpbin.org/get')
>>> r.headers
{'Date': 'Tue, 04 Aug 2020 12:57:54 GMT', 'Content-Type': 'application/json', 'Content-Length': '305', 'Connection': 'keep-alive',
'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}
>>> r.text
''
requests.head()获取HTML网页的头信息,可以看到此时的Response对象没有HTML响应的内容,所以head()方法可以用很少的网络流量来获取网络资源的概要信息。
4)Requests库的post()方法
post()方法完整形式是requests.post(url,data=None,json=None,**kwargs),url是更新页面的url链接,data、json、**kwargs都可以在request()方法中找到,只不过这里的**kwargs是11个控制访问参数。
>>> import requests
>>> payload = {'key1': 'value1','key2': 'value2'}
>>> r=requests.post('http://httpbin.org/post',data=payload)
>>> print(r.text)
{
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.23.0",
"X-Amzn-Trace-Id": "Root=1-5f295df4-20801738891519a088c8d7c0"
},
"json": null,
"origin": "157.0.138.63",
"url": "http://httpbin.org/post"
}
当我们想URL资源POST一个字典或键值对的时候,那么键值对会默认的被存储到表单form的字段下
>>> import requests
>>> r=requests.post('http://httpbin.org/post',data='ABC')
>>> print(r.text)
{
"args": {},
"data": "ABC",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "3",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.23.0",
"X-Amzn-Trace-Id": "Root=1-5f295edb-2286dede6fb188cfadf8063b"
},
"json": null,
"origin": "157.0.138.63",
"url": "http://httpbin.org/post"
}
如果不提交键值对,而向URL资源POST一个字符串的时候,那么字符串会默认存储到data字段。
5)Requests库的put()方法
put()方法完整形式是requests.put(url,data=None,**kwargs),url是更新页面的url链接,data、**kwargs都可以在request()方法中找到,只不过这里的**kwargs是12个控制访问参数。
put()方法与post()方法类似只是会将原有的字段覆盖掉。
>>> import requests
>>> payload={'key1':'value1','key2':'value2'}
>>> r=requests.put('http://httpbin.org/put',data=payload)
>>> print(r.text)
{
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.23.0",
"X-Amzn-Trace-Id": "Root=1-5f296129-77148130765d9350836b3ec0"
},
"json": null,
"origin": "157.0.138.63",
"url": "http://httpbin.org/put"
}
6)Requests库的patch()方法
patch()方法完整形式是requests.patch(url,data=None,**kwargs),url是更新页面的url链接,data、**kwargs都可以在request()方法中找到,只不过这里的**kwargs是12个控制访问参数。
7)Requests库的delete()方法
delete()方法完整形式是requests.delete(url,**kwargs),url是删除页面的url链接,data、**kwargs都可以在request()方法中找到,只不过这里的**kwargs是13个控制访问参数。
(3).爬取网页的通用代码框架
代码框架就是一种将项目开发过程中的共性或通用部分功能进行抽象,提高开发效率,创建更为稳定的程序,并减少开发者重复编写代码的基本架构。进行项目开发时,开发者如果在代码框架基础上进行二次开发,即可大大简化开发过程,快速实现系统功能。并且能够帮助初学者创建规范、稳定的项目系统。
爬取网页的通用代码框架就是一组代码,它可以准确的、可靠的爬取网页的内容。
我们在用Requests库访问网页的时候,经常用requests.get(url),获得url的相关内容。但是这样的语句并不是一定成立的,因为网络连接有风险,所以这样的语句它的异常处理很重要。Requests库支持6种如下的常用连接异常:
| 异常 | 说明 |
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
Timeout是指发出URL请求到获得内容整个过程的超时异常,而ConnectTimeout仅指与远程服务器连接过程产生的超时异常。
Response对象返回了所有的网页内容,它也提供了一个专门与异常打交道的方法r.raise_for_status(),该方法能够判断返回的状态码,如果状态码不是200就会产生一个requests.HTTPError的异常。该方法还被用于爬取网页的通用代码框架中,具体如下:
def getHTMLText(url): #封装
try:
r=requests.get(url,timeout=30) #发送一个url请求
r.raise_for_status() #非200状态码产生一个HTTPError异常
r.encoding=r.apparent_encoding
return r.text
except: #处理异常
return "产生异常"
通用代码框架的最大作用是能够使得用户访问或爬取网页变得更有效,变得更稳定,变得更可靠。
(4).HTTP协议及Requests库方法
为了能够更好理解Requests的7个主要方法,需要去理解HTTP协议。HTTP协议,英文全称Hypertext Transfer Protocol,中文全称超文本传输协议,它是一种基于“请求与响应”模式的、无状态的应用层协议。简单来说,用户发起请求,服务器做相关响应,这就是“请求与响应”的模式。而无状态指的是第一次请求与第二次请求之间没有相关的关联。最后,应用层协议指的是该协议工作在应用层,在TCP协议之上。
HTTP协议一般采用URL作为定位网络资源的标识,URL格式如下:http://host[:port][path]。每一个URL需要以http://开头,后面有三个域,host是一个合法的Internet主机域名或IP地址;port指的是端口号,可以省略,默认端口号是80;path指的是请求资源的路径。由此可以认为,URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。
HTTP协议对资源有一些操作的功能,最主要的HTTP协议的操作方法一共有6个,而这6个方法对应了Requests库提供的6个主要函数,具体如下:
| 方法 | 说明 |
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的头部信息 |
| POST | 请求向URL位置的资源追加新的数据 |
| PUT | 请求向URL位置存储一个资源,覆盖原URL位置的资源 |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容 |
| DELETE | 请求删除URL位置存储的资源 |

我们可以把互联网或Internet当成一个云端,那么云端上存储的所有资源实际上只是使用URL来做相关的描述和标识。如果我们想获取这个资源,我们可以使用GET或HEAD方法,GET方法获得全部资源,HEAD方法获得头部信息。如果我们想把自己的资源放到URL对应的位置上,我们可以使用PUT、POST、PATCH方法。如果我们想删掉这个URL对应的现有资源,我们可以使用DELETE。

事实上, HTTP协议通过URL对资源做定位,通过这6个常用的方法对资源进行管理,每一次操作都是独立无状态的。在HTTP协议的世界里,网络通道和服务器都是黑盒子,它能看到的就是URL链接以及对URL的相关操作。
(5).PATCH和PUT的区别
举一个例子,假设URL位置有一组数据UserInfo,其中包括UserID,UserName等20个字段。当用户修改了UserName而其他不变时,此时采用PATCH仅需要提交UserName的局部更新请求;但采用PUT则必须将20个字段一并提交到URL,所有未提交的字段将被删除。
由此可见,PATCH最主要的好处就是节省网络带宽,当URL对应的资源是很庞大的资源时候,我们只要改其中一个,我们PATCH去修改这一个,而不需要用PUT去重新提交这么多资源,所以PATCH也是HTTP协议改良后的一个新增指令。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号