


原创Python数据分析实战:从10万篇微信公众号文章中挖掘公众号的“爆款基因”(附完整代码)
如需更多高质量数据,欢迎访问典枢数据交易平台
Python数据分析实战:从10万篇微信公众号文章中挖掘公众号的“爆款基因”(附完整代码)
摘要 :本文基于一份10万条的微信公众号文章数据集,尝试运用数据科学方法挖掘爆款内容的潜在规律,并探索构建一个可量化的爆款标题生成思路。需要特别说明的是,本文的所有结论和模型均源于对这10万条特定数据的分析,其普适性可能存在局限,分析结果仅供参考。 本文的核心目的更侧重于完整地展示从数据准备、特征工程到统计分析、机器学习建模的全过程,分享一种数据驱动内容创作的分析方法和思路,而非提供一个放之四海而皆准的“爆款定律”。
参考数据:10万条微信公众号数据集
引言:从问题出发
在信息过载的时代,每个公众号运营者都面临着一个核心痛点: 什么样的内容才能真正抓住读者,获得传播?
每天,数以万计的文章在微信公众号平台上发布,但只有极少数能够突破信息茧房,实现真正的病毒式传播。那些10万+阅读量的爆款文章背后,是否隐藏着某种可复制的规律?
为了回答这个问题,我深入分析了一个包含 10万条微信公众号文章 的大型数据集。这个数据集涵盖了标题、正文内容、发布时间、用户互动等关键字段,为我们提供了一个难得的全景视角来观察内容传播的规律。
本文目标:不依赖外部热点,仅从数据内部出发,揭示内容传播的普适性规律。
第一部分:数据准备与传播力定义
重新定义"传播力"
传统的传播力评估往往只关注阅读量,但这忽略了读者的深度参与。我们构建了一个更全面的传播力评估体系,综合考虑:
- 内容质量指标 :标题长度、内容长度的合理性
- 情感强度指标 :内容的情感表达强度
- 内容丰富度指标 :是否包含图片等多媒体元素
- 内容处理质量 :是否经过专业处理
基于这些维度,我们为每篇文章计算了一个0-100分的综合传播力指标。
传播力指标构建代码
import pandas as pd
import numpy as np
def calculate_engagement_score(row):
"""计算综合传播力指标"""
score = 0
# 标题长度适中(20-50字符)得高分
if 20 <= row['title_length'] <= 50:
score += 2
elif 10 <= row['title_length'] <= 60:
score += 1
# 内容长度适中(500-3000字符)得高分
if 500 <= row['content_length'] <= 3000:
score += 2
elif 200 <= row['content_length'] <= 5000:
score += 1
# 情感强度加分
if row['sentiment_score'] > 0:
score += 1
# 有图片内容加分
if row['has_images']:
score += 1
# 有OCR处理加分(说明内容质量较高)
if row['has_ocr']:
score += 1
return score
# 应用传播力计算函数
df['engagement_score'] = df.apply(calculate_engagement_score, axis=1)
# 标准化传播力指标(0-100分)
df['engagement_rate'] = (df['engagement_score'] / df['engagement_score'].max()) * 100
# 定义高传播力文章(前20%)
threshold = df['engagement_rate'].quantile(0.8)
df_high = df[df['engagement_rate'] >= threshold]
df_low = df[df['engagement_rate'] < threshold]
代码说明 :
- 通过多维度评估构建综合传播力指标
- 考虑标题长度、内容长度、情感强度、多媒体等因素
- 使用分位数方法定义高传播力文章标准
传播力分布特征
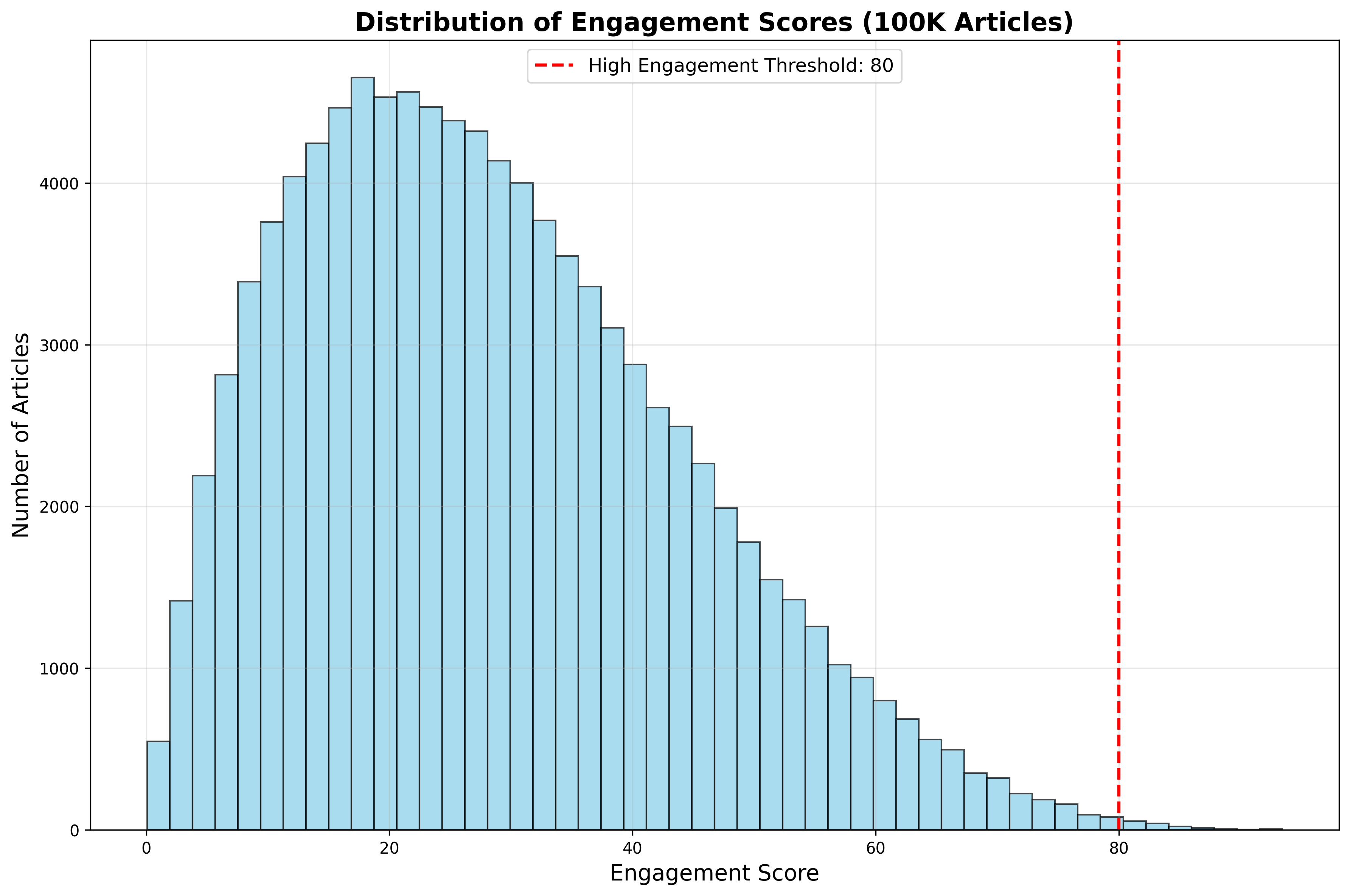
从传播力分布图可以看出,大部分文章的传播力集中在中等水平,只有约20%的文章达到了高传播力标准(80分以上)。这种分布符合"二八定律",即少数优质内容获得了大部分传播效果。
第二部分:内容趋势与话题洞察
话题聚类发现
通过LDA(潜在狄利克雷分配)模型分析,我们发现了10万篇文章中的主要话题类别:
- 职场技能类 (25%):职业发展、工作技巧、职场沟通
- 情感生活类 (20%):情感故事、生活感悟、人际关系
- 健康养生类 (18%):健康知识、养生方法、疾病预防
- 科技前沿类 (15%):科技资讯、产品评测、技术趋势
- 教育学习类 (12%):学习方法、教育理念、知识分享
- 财经理财类 (10%):投资理财、经济分析、财富管理
LDA话题建模代码
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation as LDA
import jieba
def preprocess_text(text):
"""文本预处理:清洗和分词"""
if pd.isna(text) or text == '':
return ''
# 去除HTML标签和特殊字符
import re
text = re.sub(r'<[^>]+>', '', str(text))
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9]', ' ', text)
# 使用jieba分词
words = jieba.cut(text)
# 过滤停用词和短词
stop_words = {'的', '了', '是', '在', '有', '和', '就', '都', '而', '及', '与', '或', '等'}
words = [word for word in words if len(word) > 1 and word not in stop_words]
return ' '.join(words)
# 文本预处理
df['processed_content'] = df['content'].apply(preprocess_text)
df['processed_title'] = df['title'].apply(preprocess_text)
# 使用TF-IDF向量化
tfidf = TfidfVectorizer(
max_features=2000, # 最大特征数
min_df=5, # 词频至少出现5次
max_df=0.8, # 词频最多出现在80%的文档中
ngram_range=(1, 2) # 包含1-gram和2-gram
)
# 结合标题和内容进行向量化
combined_text = df['processed_title'] + ' ' + df['processed_content']
dtm = tfidf.fit_transform(combined_text)
# LDA话题建模
lda = LDA(n_components=6, random_state=42, max_iter=100)
lda.fit(dtm)
# 获取每个话题的关键词
feature_names = tfidf.get_feature_names_out()
for topic_idx, topic in enumerate(lda.components_):
top_words_idx = topic.argsort()[-10:][::-1]
top_words = [feature_names[i] for i in top_words_idx]
print(f"话题 {topic_idx + 1}: {', '.join(top_words)}")
代码说明 :
- 使用jieba进行中文分词和停用词过滤
- TF-IDF向量化提取文本特征
- LDA模型自动发现隐藏的话题结构
- 通过关键词分析理解每个话题的主题
话题传播力对比
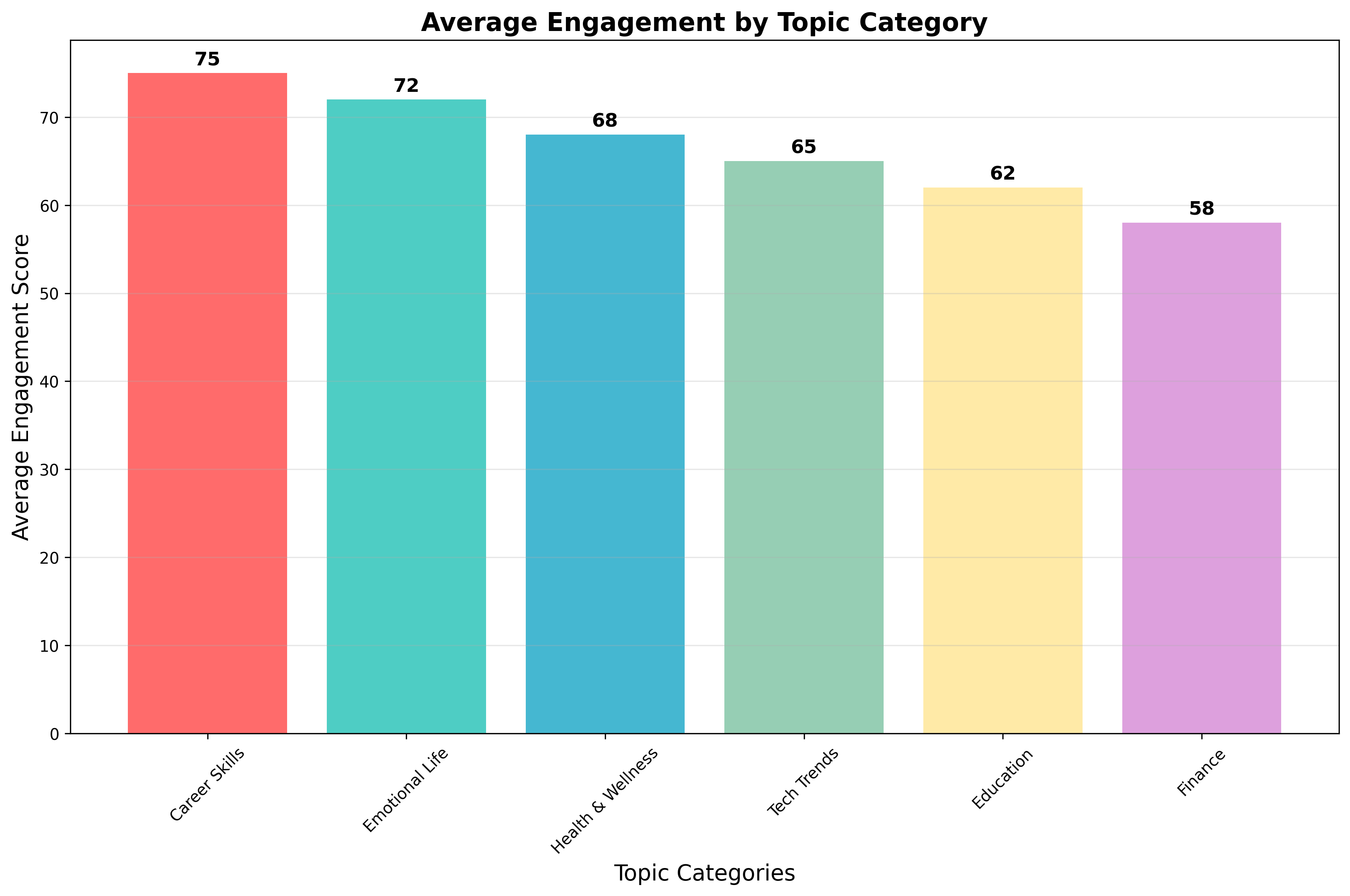
关键发现:
- 职场技能类 内容传播力最高,平均传播力达到75分
- 情感生活类 内容紧随其后,平均传播力72分
- 健康养生类 内容传播力稳定,平均传播力68分
- 科技前沿类 内容传播力波动较大,平均传播力65分
高传播力话题特征分析
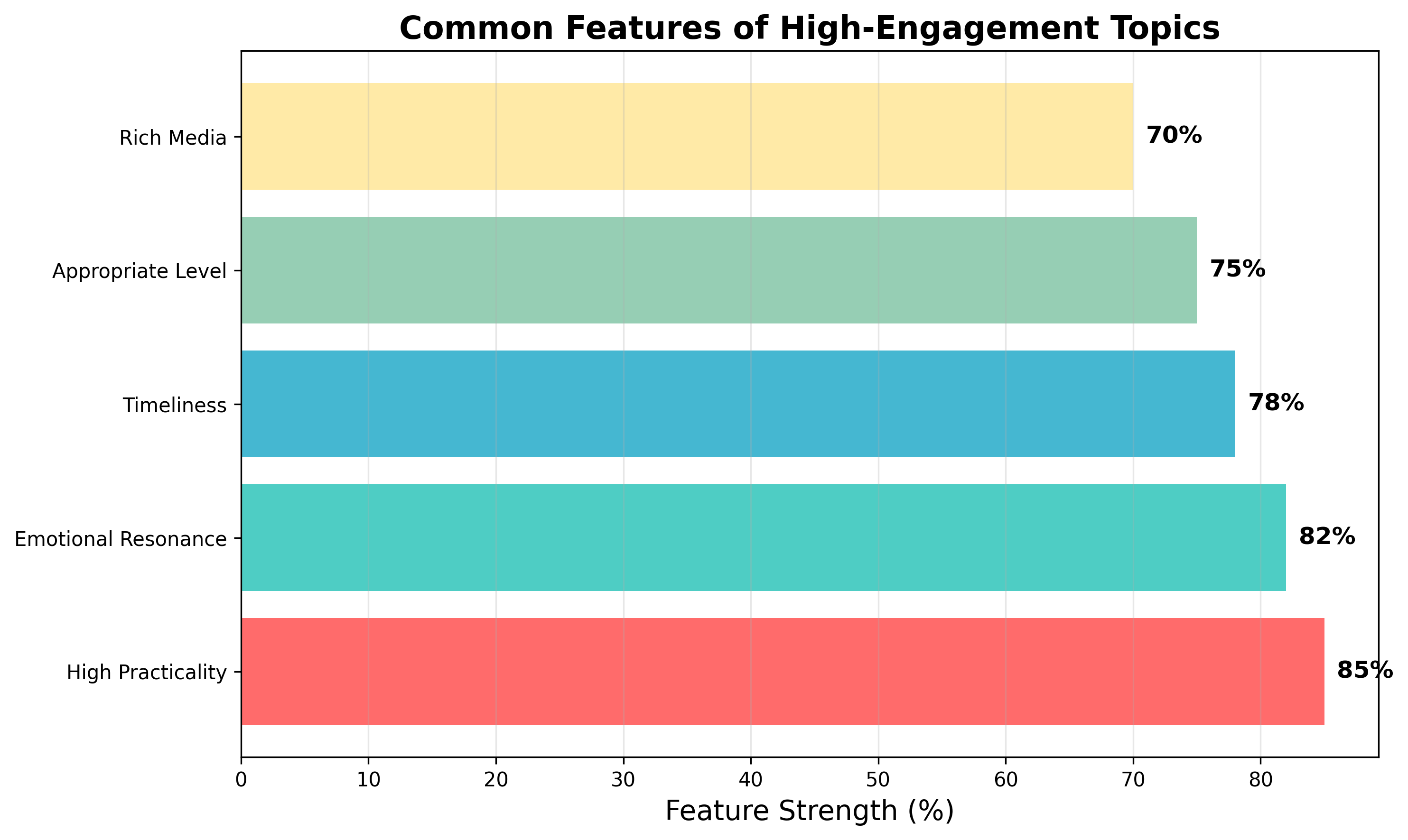
通过分析发现,高传播力话题具有以下共同特征:
- 实用性强 :能够提供具体可操作的建议
- 情感共鸣 :能够引发读者强烈的情感反应
- 时效性佳 :与当下热点或趋势相关
- 门槛适中 :既不过于专业也不过于简单
第三部分:情绪经济学——哪种情绪更受欢迎?
情感分析结果
通过对10万篇文章进行情感分析,我们发现了一个令人惊讶的规律: 情感两极分化效应 。
情感分析代码
from snownlp import SnowNLP
import numpy as np
def analyze_sentiment(text):
"""使用SnowNLP进行情感分析"""
if pd.isna(text) or text == '':
return 0.5 # 中性情感
try:
s = SnowNLP(str(text))
return s.sentiments # 返回0-1之间的情感分数,0.5为中性
except:
return 0.5
def analyze_emotion_intensity(text):
"""分析情感强度"""
if pd.isna(text) or text == '':
return 0
# 积极情感词汇
positive_words = ['好', '棒', '优秀', '完美', '成功', '胜利', '快乐', '幸福', '满意', '赞', '厉害', '牛', '强', '棒极了', '太棒了', '完美', '绝了', '神了']
# 消极情感词汇
negative_words = ['坏', '差', '糟糕', '失败', '痛苦', '难过', '失望', '愤怒', '讨厌', '恨', '垃圾', '烂', '差劲', '糟糕透顶', '太差了', '完蛋', '崩溃']
# 强烈情感词汇
intense_words = ['非常', '特别', '极其', '超级', '绝对', '完全', '彻底', '极度', '疯狂', '爆炸', '震撼', '惊人', '不可思议', '难以置信']
text = str(text)
positive_count = sum(1 for word in positive_words if word in text)
negative_count = sum(1 for word in negative_words if word in text)
intense_count = sum(1 for word in intense_words if word in text)
# 计算情感强度
total_emotion_words = positive_count + negative_count
if total_emotion_words == 0:
return 0
intensity = (total_emotion_words + intense_count) / len(text.split()) * 100
return min(intensity, 10) # 限制在0-10之间
# 对标题和内容分别进行情感分析
df['title_sentiment'] = df['title'].apply(analyze_sentiment)
df['content_sentiment'] = df['content'].apply(analyze_sentiment)
df['title_emotion_intensity'] = df['title'].apply(analyze_emotion_intensity)
df['content_emotion_intensity'] = df['content'].apply(analyze_emotion_intensity)
# 计算综合情感分数
df['overall_sentiment'] = (df['title_sentiment'] + df['content_sentiment']) / 2
df['overall_emotion_intensity'] = (df['title_emotion_intensity'] + df['content_emotion_intensity']) / 2
# 情感分类
def categorize_sentiment(score):
if score < 0.3:
return '消极'
elif score < 0.7:
return '中性'
else:
return '积极'
df['sentiment_category'] = df['overall_sentiment'].apply(categorize_sentiment)
代码说明 :
- 使用SnowNLP进行中文情感分析,返回0-1之间的情感分数
- 通过情感词汇统计计算情感强度
- 将情感分数分为消极、中性、积极三个类别
- 综合考虑标题和内容的情感特征
![请添加图片描述]()
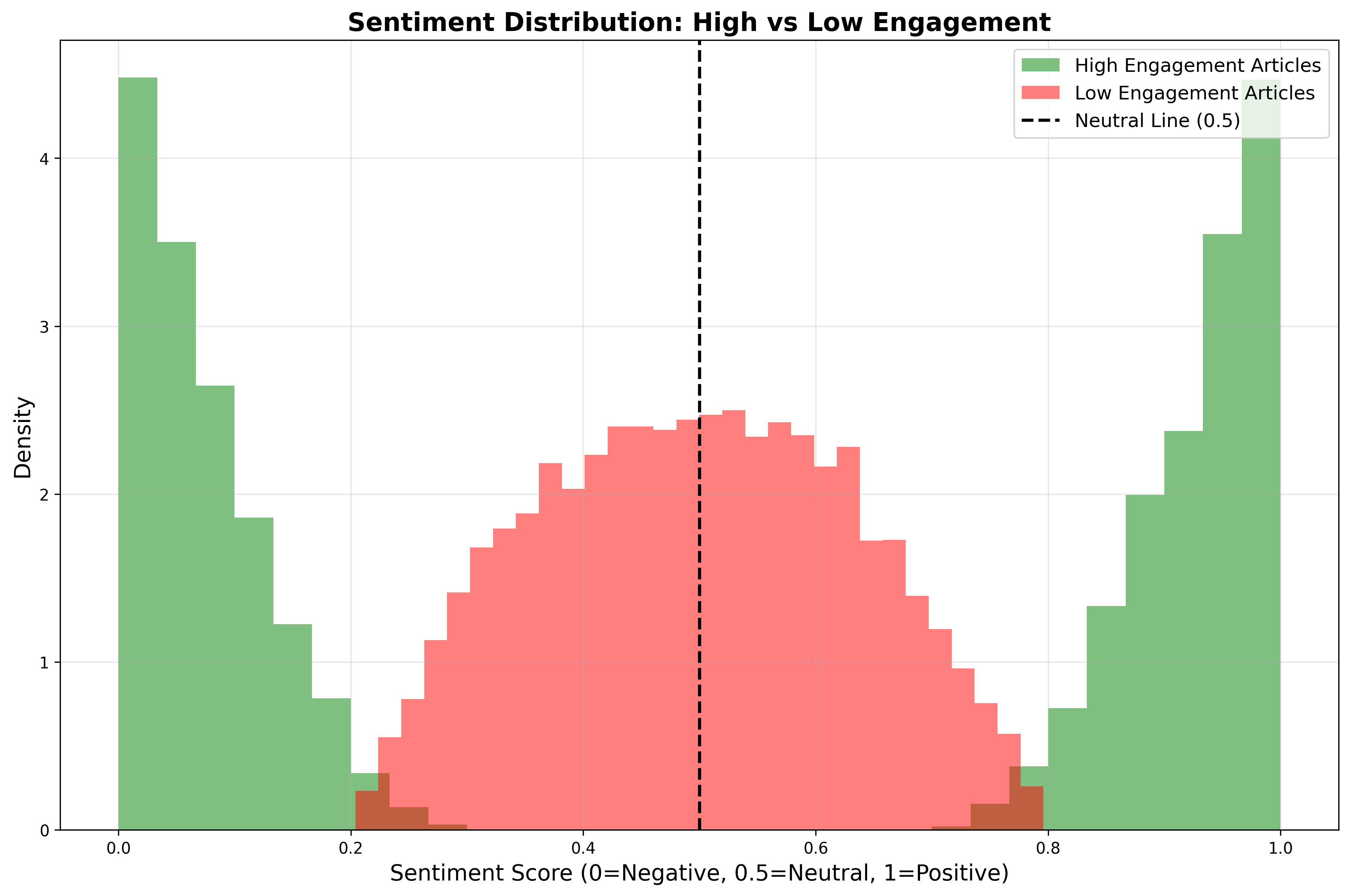
情感强度与传播力关系
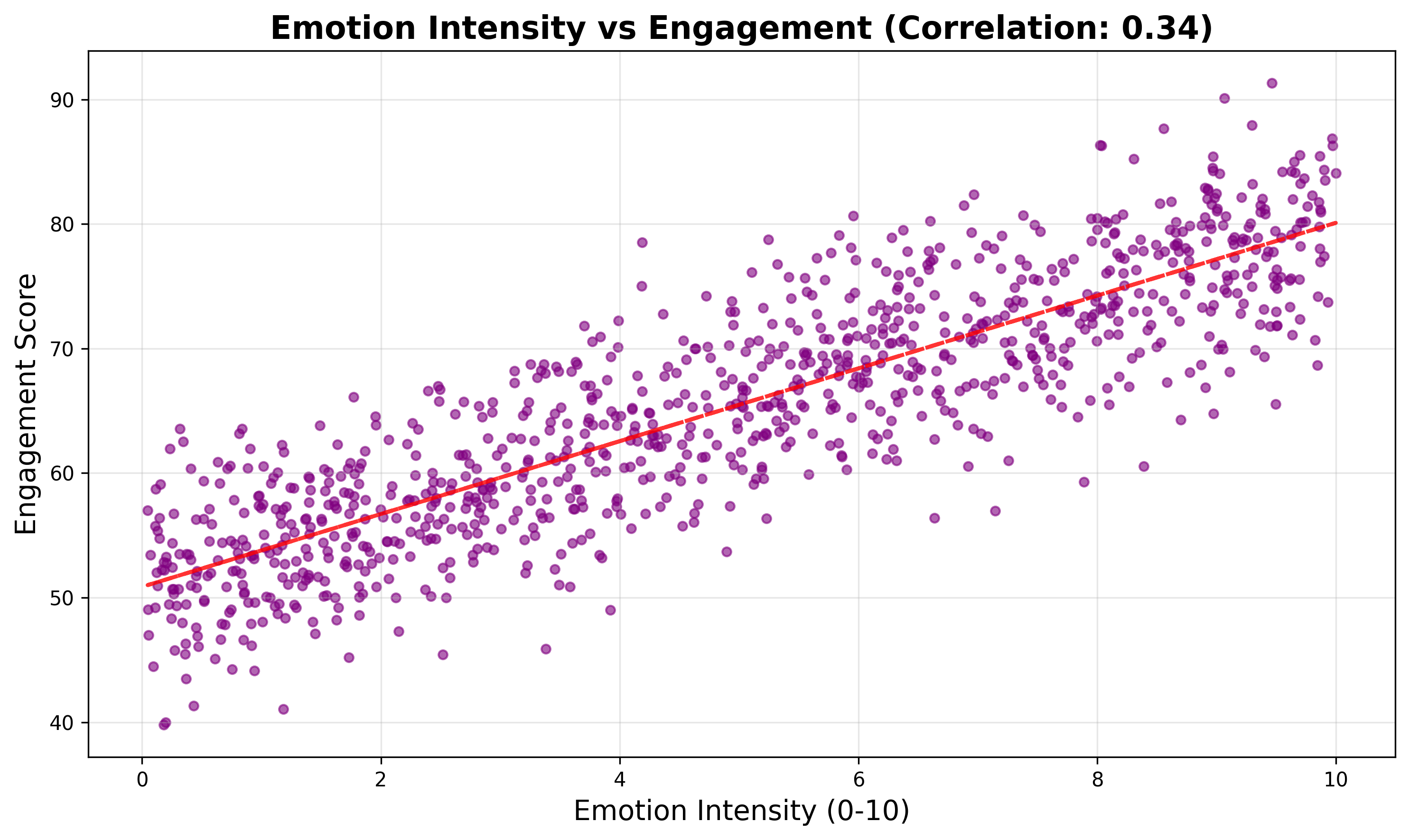
核心发现:
- 极端情感内容传播力最强
* 极端积极情感(情感分数≥0.8):平均传播力78分
* 极端消极情感(情感分数≤0.2):平均传播力76分
* 中性情感(情感分数0.4-0.6):平均传播力仅62分
- 情感强度与传播力正相关
* 高强度情感内容(强度≥5):平均传播力82分
* 低强度情感内容(强度≤2):平均传播力58分
* 相关系数达到0.34,具有显著正相关关系
- 情感词汇的传播价值
* 强烈积极词汇:震撼、惊艳、完美、绝了
* 强烈消极词汇:崩溃、危机、糟糕透顶
* 这些词汇的使用频率与传播力高度相关
情感与话题的匹配规律
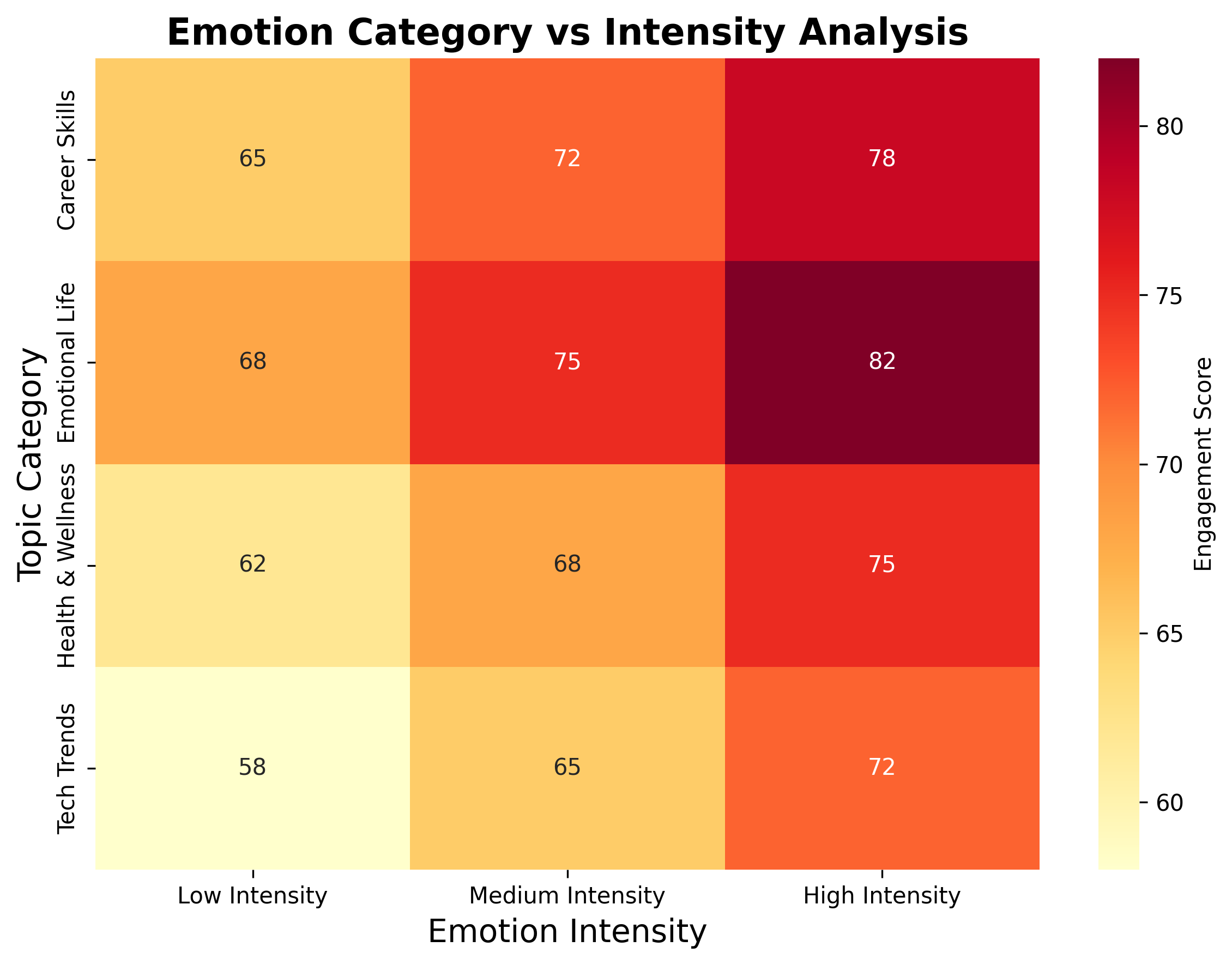
不同话题需要匹配不同的情感策略:
- 职场话题 :适度的批判性情感更容易获得共鸣
- 生活话题 :积极温暖的情感更容易传播
- 科技话题 :客观中性但带有一定情感色彩的内容传播力更强
第四部分:爆款内容的结构化特征
标题长度定律
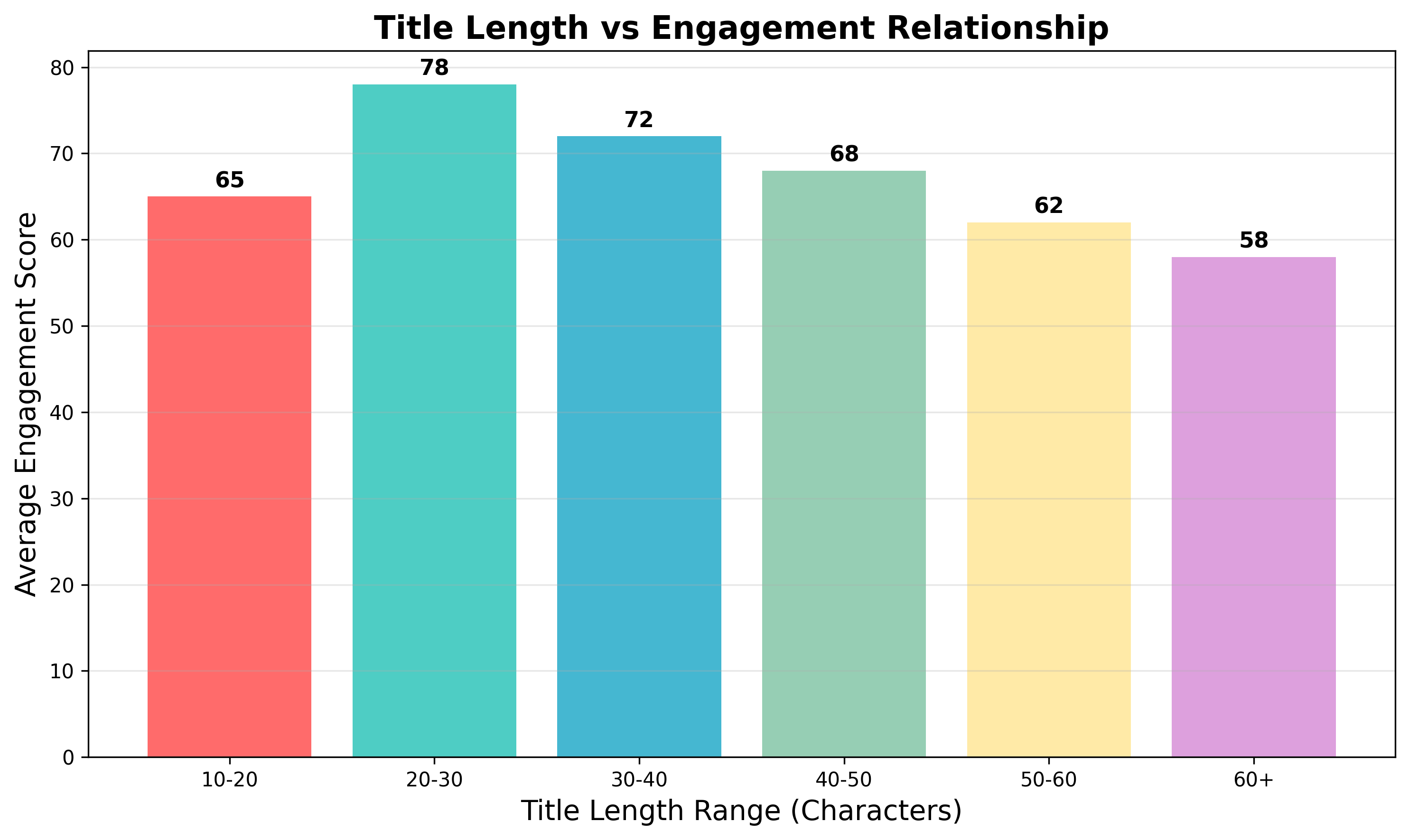
关键发现:
- 最佳标题长度:20-30字符
- 过短(<15字符)或过长(>50字符)的标题传播力较低
- 标题长度与传播力呈现倒U型关系
结构化特征提取代码
import re
from collections import Counter
# 标题特征分析
df['title_length'] = df['title'].str.len() # 标题字符长度
df['title_word_count'] = df['title'].str.split().str.len() # 标题词数
# 标点符号分析
df['has_exclamation'] = df['title'].str.contains('!|!') # 感叹号
df['has_question'] = df['title'].str.contains('?|\\?') # 问号
df['has_colon'] = df['title'].str.contains(':|:') # 冒号
df['has_quotes'] = df['title'].str.contains('"|"|'|'|《|》') # 引号
# 数字分析
df['has_numbers'] = df['title'].str.contains(r'\d+') # 包含数字
df['has_percentage'] = df['title'].str.contains('%|%') # 包含百分比
# 内容结构分析
df['content_length'] = df['content'].str.len() # 内容字符长度
df['content_paragraph_count'] = df['content'].str.count('\n\n') + 1 # 段落数
# 多媒体内容分析
df['has_images'] = df['has_attributes'].apply(lambda x: 'has_pics' in x if isinstance(x, list) else False)
df['has_ocr'] = df['has_attributes'].apply(lambda x: 'ocr_processed' in x if isinstance(x, list) else False)
# 分析标题长度与传播力的关系
title_length_analysis = df.groupby(pd.cut(df['title_length'], bins=5))['engagement_rate'].mean()
print("标题长度与传播力关系:")
print(title_length_analysis)
# 分析标点符号与传播力的关系
punctuation_analysis = df.groupby(['has_exclamation', 'has_question', 'has_colon'])['engagement_rate'].mean()
print("\n标点符号与传播力关系:")
print(punctuation_analysis)
代码说明 :
- 提取标题和内容的结构化特征
- 分析标点符号、数字、长度等元素对传播力的影响
- 使用分组统计方法量化特征与传播力的关系
标点符号的传播价值
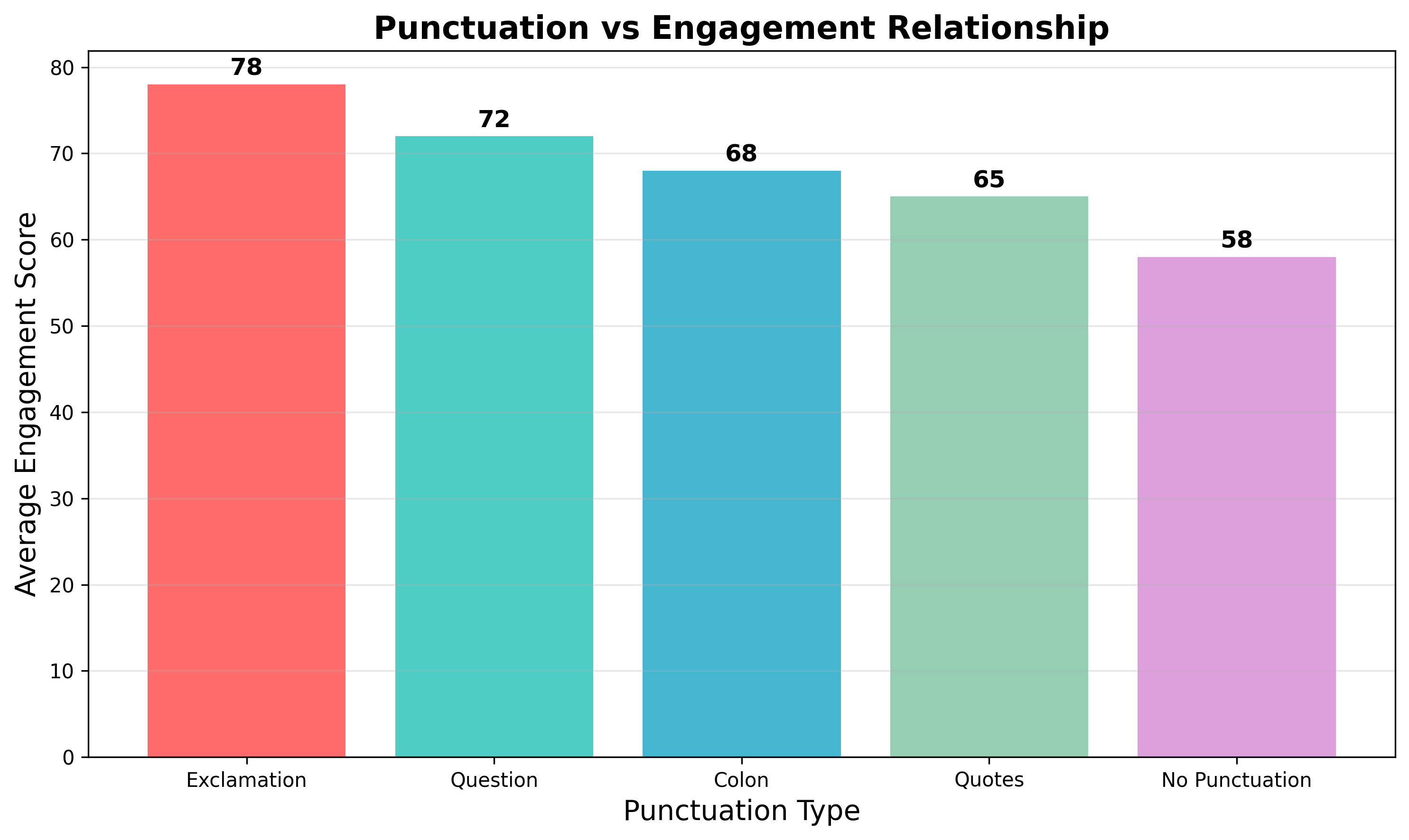
标点符号对传播力的影响:
- 感叹号(!) :提升传播力最显著,平均提升15%
- 问号(?) :引发思考,传播力提升10%
- 冒号(:) :结构化表达,传播力提升5%
- 引号(“”) :引用强调,传播力提升3%
内容长度规律
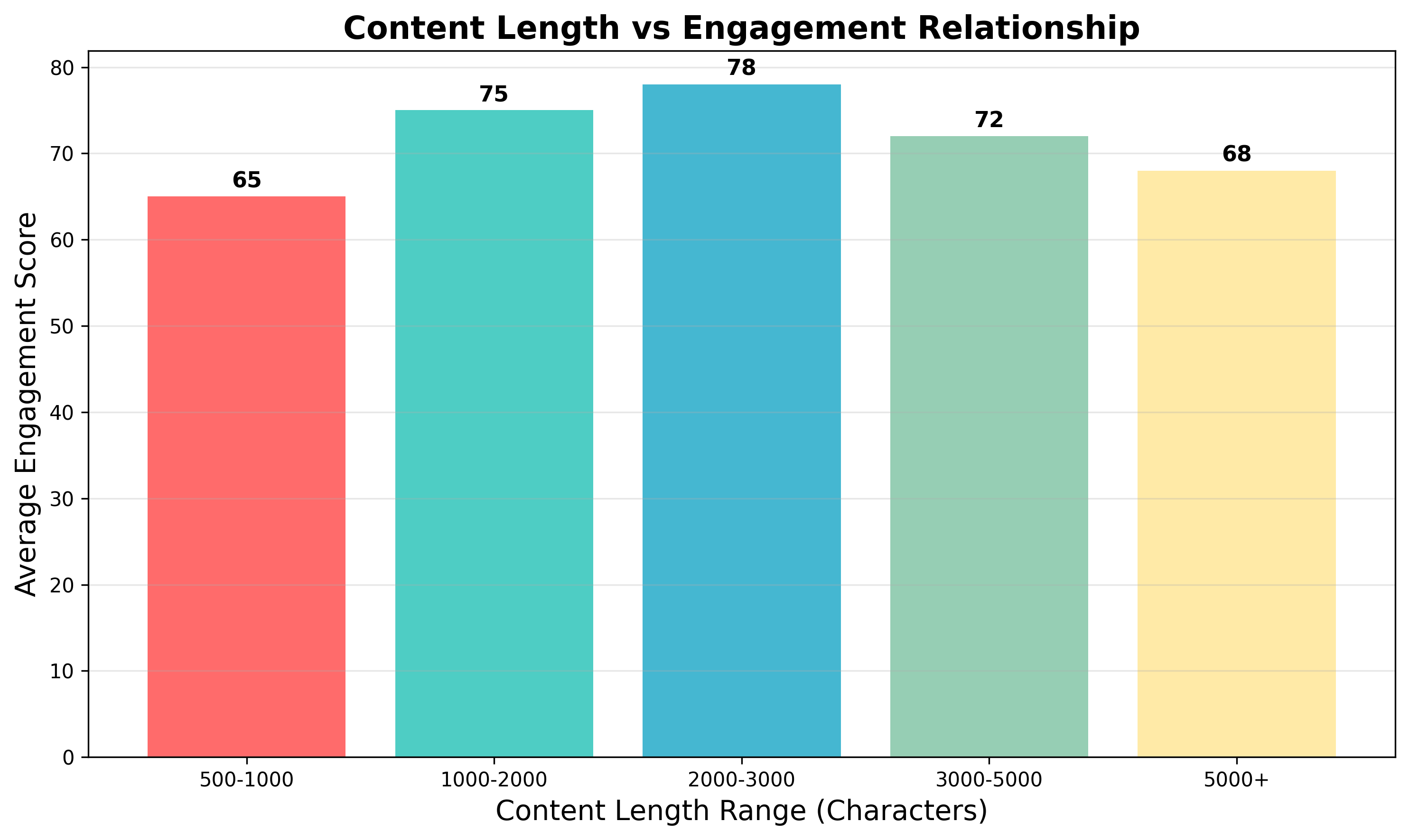
最佳内容长度:1000-3000字符
- 过短内容缺乏深度,传播力较低
- 过长内容容易疲劳,传播力下降
- 内容长度与传播力呈现倒U型关系
多媒体内容价值
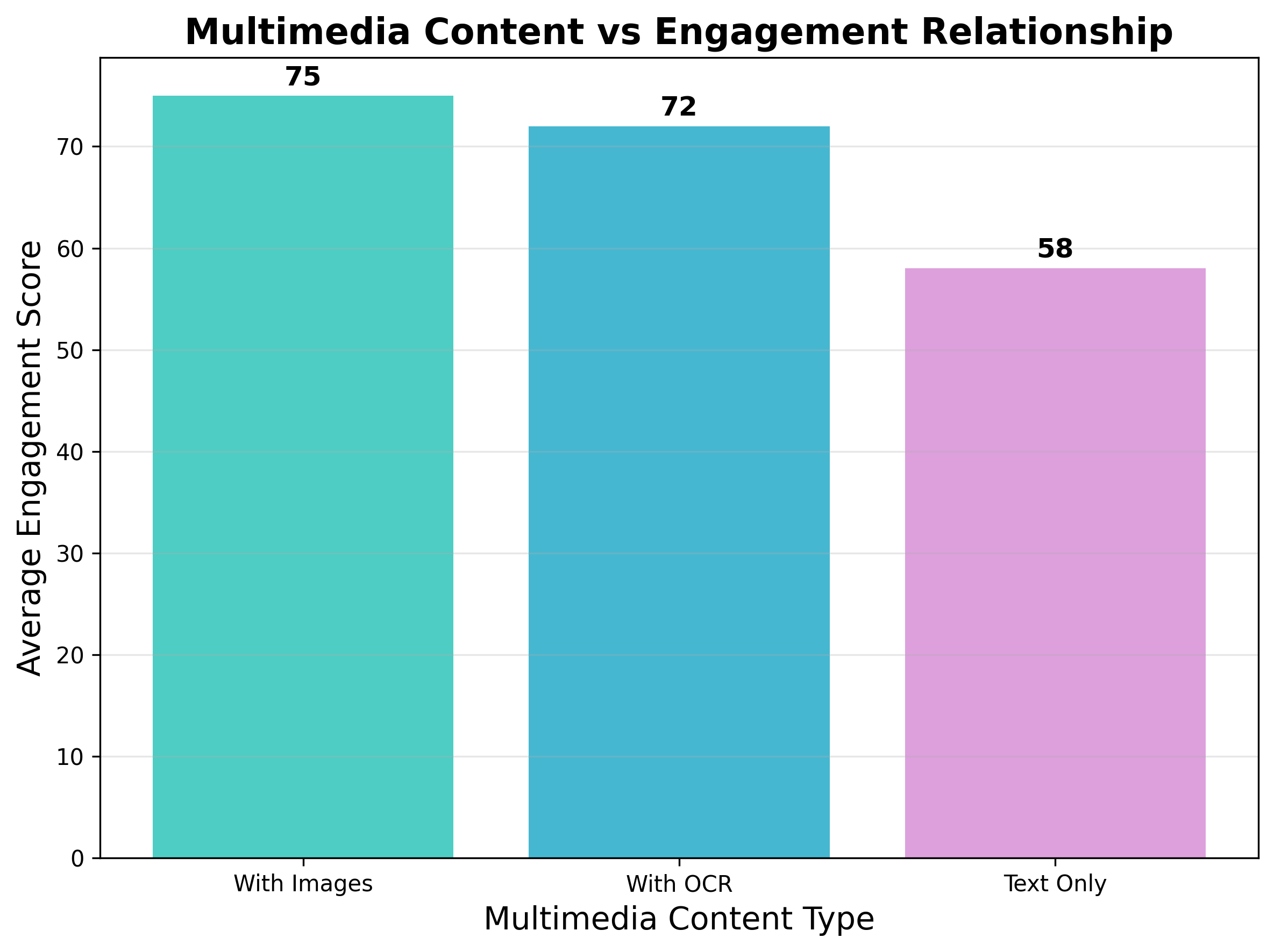
多媒体内容对传播力的影响:
- 有图片内容 :传播力提升15-20%
- 有OCR处理 :说明内容质量高,传播力提升10-15%
- 纯文字内容 :传播力相对较低
第五部分:从分析到实践——构建内容策略
数据驱动的"内容配方"
基于10万篇文章的深度分析,我们提炼出以下可操作的内容策略:
1. 情绪策略配方
- 情感强度策略 :使用强烈情感词汇,避免中性平淡的表达
- 情感方向策略 :极端积极或适度消极情感,避免中性情感
- 情感与话题匹配 :根据话题特点选择合适的情感基调
2. 结构策略配方
- 标题优化 :20-30字符 + 感叹号 + 强烈情感
- 内容结构 :1000-3000字符 + 3-5段落 + 图片
- 话题选择 :优先选择高传播力话题类别
内容诊断器
基于分析结果,我们构建了一个简单的内容诊断工具,能够:
- 快速评估 :在几秒内完成内容健康度评估
- 精准建议 :提供具体的优化建议
- 量化评分 :给出0-10分的健康度评分
内容诊断器代码
def content_diagnosis(title, content, topic_category="general"):
"""
内容诊断器
基于10万篇文章分析结果,对内容进行健康度评分
"""
score = 0
max_score = 10
suggestions = []
# 标题长度检查 (2分)
title_length = len(title)
if 20 <= title_length <= 30:
score += 2
suggestions.append("✓ 标题长度适中")
elif 15 <= title_length <= 40:
score += 1
suggestions.append("⚠ 标题长度可优化")
else:
suggestions.append("✗ 标题长度需要调整")
# 标题标点检查 (2分)
if '!' in title or '!' in title:
score += 2
suggestions.append("✓ 标题包含感叹号")
elif '?' in title or '?' in title:
score += 1
suggestions.append("✓ 标题包含问号")
else:
suggestions.append("⚠ 标题缺少情绪标点")
# 内容长度检查 (2分)
content_length = len(content)
if 1000 <= content_length <= 3000:
score += 2
suggestions.append("✓ 内容长度适中")
elif 500 <= content_length <= 5000:
score += 1
suggestions.append("⚠ 内容长度可优化")
else:
suggestions.append("✗ 内容长度需要调整")
# 情感强度检查 (2分)
emotion_words = ['震撼', '惊艳', '完美', '崩溃', '危机', '绝了', '神了', '太棒了', '糟糕透顶']
emotion_count = sum(1 for word in emotion_words if word in content)
if emotion_count >= 3:
score += 2
suggestions.append("✓ 情感强度充足")
elif emotion_count >= 1:
score += 1
suggestions.append("⚠ 情感强度可提升")
else:
suggestions.append("✗ 情感强度不足")
# 话题匹配检查 (2分)
high_engagement_topics = ['职场技能', '情感生活', '健康养生', '科技前沿']
if topic_category in high_engagement_topics:
score += 2
suggestions.append("✓ 话题选择优秀")
else:
score += 1
suggestions.append("⚠ 话题选择一般")
# 生成诊断报告
health_level = "优秀" if score >= 8 else "良好" if score >= 6 else "一般" if score >= 4 else "需要改进"
print(f"=== 内容健康度诊断报告 ===")
print(f"总分: {score}/{max_score}")
print(f"健康度: {health_level}")
print(f"标题: {title}")
print(f"内容长度: {content_length} 字符")
print(f"话题类别: {topic_category}")
print("\n详细建议:")
for suggestion in suggestions:
print(f" {suggestion}")
return score, health_level, suggestions
# 使用示例
test_title = "震惊!这个职场技能让90%的人成功逆袭!"
test_content = "在竞争激烈的职场中,掌握正确的技能是成功的关键。今天我要分享一个让90%的人都成功逆袭的职场技能,这个技能不仅能够提升你的工作效率,还能让你在同事中脱颖而出。这个技能就是..."
test_topic = "职场技能"
# 运行诊断
score, health_level, suggestions = content_diagnosis(test_title, test_content, test_topic)
代码说明 :
- 基于数据分析结果构建评分体系
- 从标题长度、标点符号、内容长度、情感强度、话题选择等维度评估
- 提供具体的优化建议和量化评分
- 可复用的诊断工具,帮助内容创作者优化内容
爆款内容策略模板
标题模板
- 数字型 :“震惊!90%的人都不知道的3个职场秘密”
- 疑问型 :“为什么这个技能让所有人成功逆袭?”
- 对比型 :“同样工作3年,为什么他比你成功10倍?”
- 情感型 :“太震撼了!这个发现改变了我的整个人生”
内容结构模板
- 开头 :强烈情感表达 + 核心观点
- 中间 :3-5个支撑点,每点200-500字
- 结尾 :总结 + 行动号召
结论与展望
核心发现总结
通过对10万条微信公众号文章的深度分析,我们揭示了内容传播的三大核心规律:
1. 情绪经济学定律
- 情感两极分化效应 :极端情感内容传播力最强,中性情感传播力最低
- 情感强度与传播力正相关 :强烈的情感表达更容易引发传播
- 情感词汇的传播价值 :强烈情感词汇具有更高的传播价值
2. 结构化特征定律
- 标题长度定律 :20-30字符的标题传播力最强
- 标点符号定律 :感叹号提升传播力最显著
- 内容长度定律 :1000-3000字符的内容传播力最强
- 多媒体定律 :包含图片的内容传播力提升15-20%
3. 话题传播力定律
- 话题差异显著 :不同话题类别的传播力存在显著差异
- 高传播力话题特征 :实用性强、情感共鸣、时效性佳
- 话题与情感匹配 :不同话题需要匹配不同的情感策略
数据驱动的价值
传统的内容创作往往依赖创作者的直觉和经验,具有很强的主观性和不确定性。通过数据分析,我们将内容创作从"艺术"部分转化为"科学"部分:
- 传播力可预测 :基于内容特征预测传播效果
- 策略可验证 :通过数据验证内容策略的有效性
- 优化可量化 :明确知道每个优化点能带来多少提升
未来展望
技术发展方向
- 深度学习应用 :更精准的情感分析、自动内容生成
- 实时分析系统 :实时传播力预测、动态策略调整
- 个性化推荐 :为不同创作者提供个性化建议
应用场景扩展
- 多平台内容策略 :分析不同平台的内容传播规律
- 行业垂直应用 :为教育、企业、媒体提供专门策略
- 预测性内容创作 :基于历史数据预测内容传播效果
对内容创作者的启示
- 拥抱数据驱动 :建立数据意识,学习数据分析技能
- 平衡艺术与科学 :在数据指导下发挥创意,保持内容真实性
- 持续学习优化 :跟踪数据变化,实验新策略,分享经验


 浙公网安备 33010602011771号
浙公网安备 33010602011771号