


超2000万条高清短视频大数据集,覆盖人物风景动物美食纪录片多主题,1080p无水印视频素材支持大模型视觉识别训练、文生视频生成、推荐算法优化与跨学科科研应用
引言与背景
随着人工智能和计算机视觉技术的飞速发展,高质量视频数据已成为训练先进模型、推动多模态学习与内容生成创新的关键资源。本数据集汇集了海量原始视频素材,覆盖广泛主题,不仅为学术研究提供了丰富的实验基础,还在工业应用中发挥着重要作用,例如提升视频内容理解精度、赋能文生视频模型训练,以及优化推荐系统和自动化内容生产。通过利用这些数据,研究者和开发者可以加速算法迭代,降低模型训练成本,并推动AI在娱乐、教育、营销等领域的实际落地。
数据基本信息
本数据集规模庞大,包含超过2000万条原始视频素材,每条视频时长从10秒到10分钟以上不等,确保了数据的多样性和实用性。视频格式以avi、mp4和wmv为主,分辨率均达到1080p或更高,保证了高清视觉质量,且所有素材均无水印,适合直接用于模型训练和分析。数据覆盖多种主题类型,包括人物、风景、动物、美食和纪录片等,标注信息针对视频主题和描述进行了有效处理,并可提供定制化标签服务,例如添加对象检测、场景分类或情感分析标注,以满足特定项目需求。数据集经过初步整理,确保一致性和可访问性,适用于大规模机器学习任务。
| 优势 | 说明 |
|---|---|
| 海量与高清 | 超过2000万条视频,分辨率1080p及以上,提供丰富且清晰的视觉素材,支持高精度模型训练。 |
| 主题多样性 | 涵盖人物、风景、动物、美食、纪录片等多个类别,增强数据的泛化能力,适用于跨领域应用。 |
| 无水印 | 所有视频均无水印,避免了干扰因素,确保模型训练的纯净输入,提升输出质量。 |
| 可定制化标注 | 支持根据用户需求添加个性化标签,如主题细分、对象标注或元数据扩展,提高数据的灵活性和实用性。 |
| 样例获取方式 | 多类型原始视频素材数据集_视频数据集-典枢 |
应用场景
大模型视觉识别与视频内容理解
该数据集可用于训练大规模视觉识别模型,如卷积神经网络(CNN)或视觉变换器(ViT),以提升视频中的对象检测、场景分类和行为识别精度。通过分析高清视频素材,模型可以学习复杂视觉特征,例如识别风景中的自然元素或人物动作序列,从而应用于安防监控、智能驾驶或内容审核系统。在实际应用中,结合定制化标注,开发者可以构建端到端的视频理解管道,自动化提取关键信息,减少人工干预,提高效率。例如,在电商领域,模型可自动分析产品视频中的特征,增强搜索和推荐功能,为用户提供更精准的体验。
文生视频模型训练与多模态生成
对于文生视频(text-to-video)任务,本数据集提供了丰富的配对数据(视频与描述),可用于训练生成对抗网络(GANs)或扩散模型,实现从文本描述生成高质量视频内容。这类应用在娱乐、广告和教育行业中具有巨大潜力,例如自动创建短视频内容或虚拟场景。通过利用数据中的多主题多样性,模型能更好地理解不同语境下的视觉表达,提升生成内容的真实性和多样性。实际项目中,可结合先进的多模态学习框架,如CLIP或DALL-E的变体,推动创新应用如自动化视频制作工具,帮助内容创作者快速产出个性化作品,降低创作门槛。
视频推荐系统与个性化内容优化
该数据集支持视频推荐算法的开发,通过分析视频主题、时长和用户交互元数据,训练协同过滤或深度学习推荐模型,以提升内容分发的精准度。例如,平台可以利用这些数据识别热门趋势或用户偏好,优化视频流推荐,增强用户参与度和留存率。结合定制化标签,系统可以细分内容类别,实现更细粒度的个性化,如根据用户历史行为推荐特定主题的美食或纪录片视频。这不仅适用于短视频平台,还可扩展至在线教育或企业培训场景,提供自适应学习路径,推动智能内容生态的建设。
学术研究与跨学科创新
在学术领域,本数据集为计算机视觉、人工智能和社会科学的研究提供了宝贵资源,支持探索视频内容的情感分析、文化趋势或人类行为模式。研究人员可利用这些数据开展跨学科项目,如结合心理学分析视频中的情感表达,或使用经济学方法研究内容传播规律。通过开放数据访问,可以促进合作创新,加速新技术如联邦学习或隐私保护计算在视频处理中的应用,最终贡献于更广泛的社会效益,如改善媒体素养或推动数字化转型。
数据样例


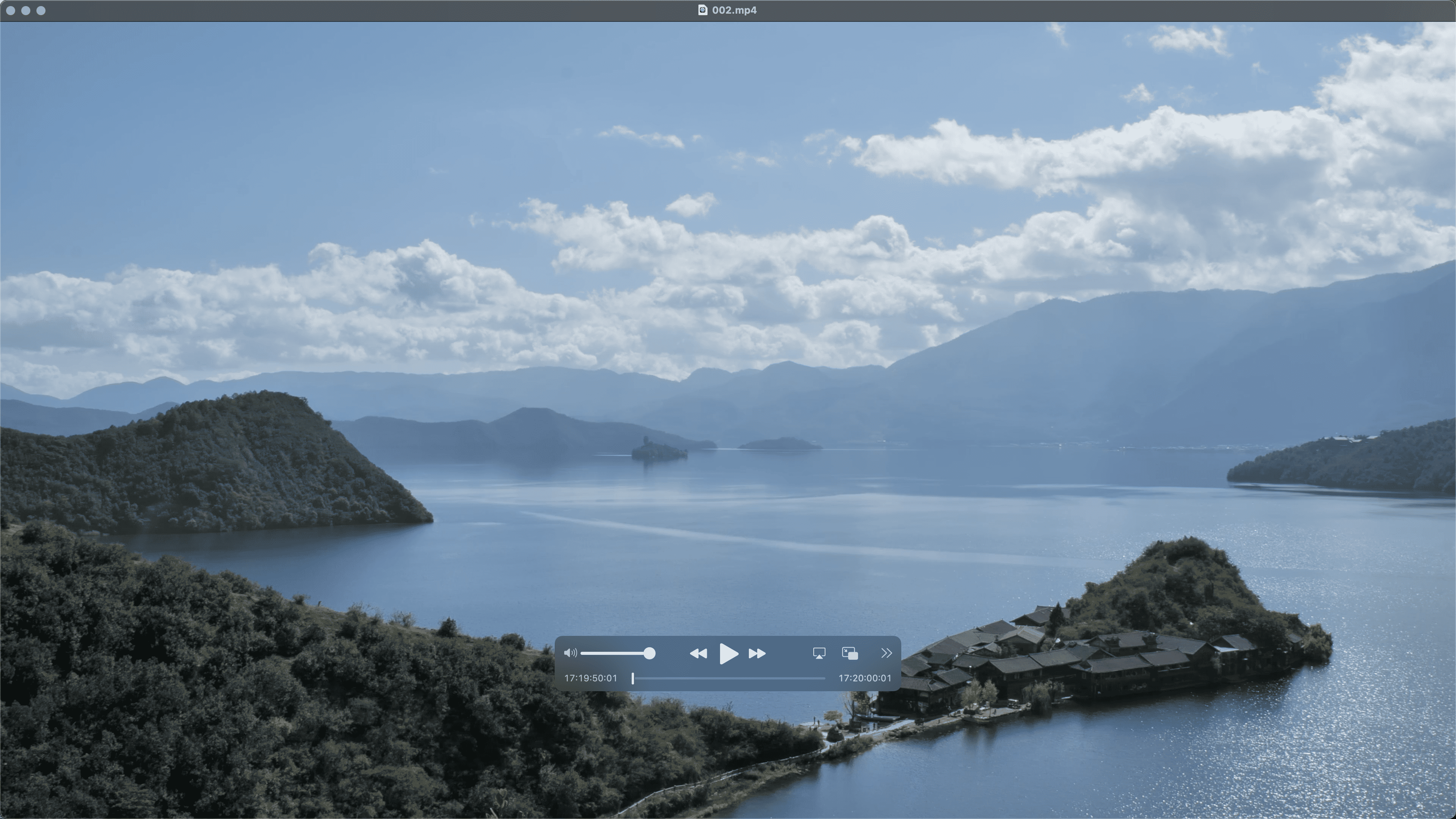
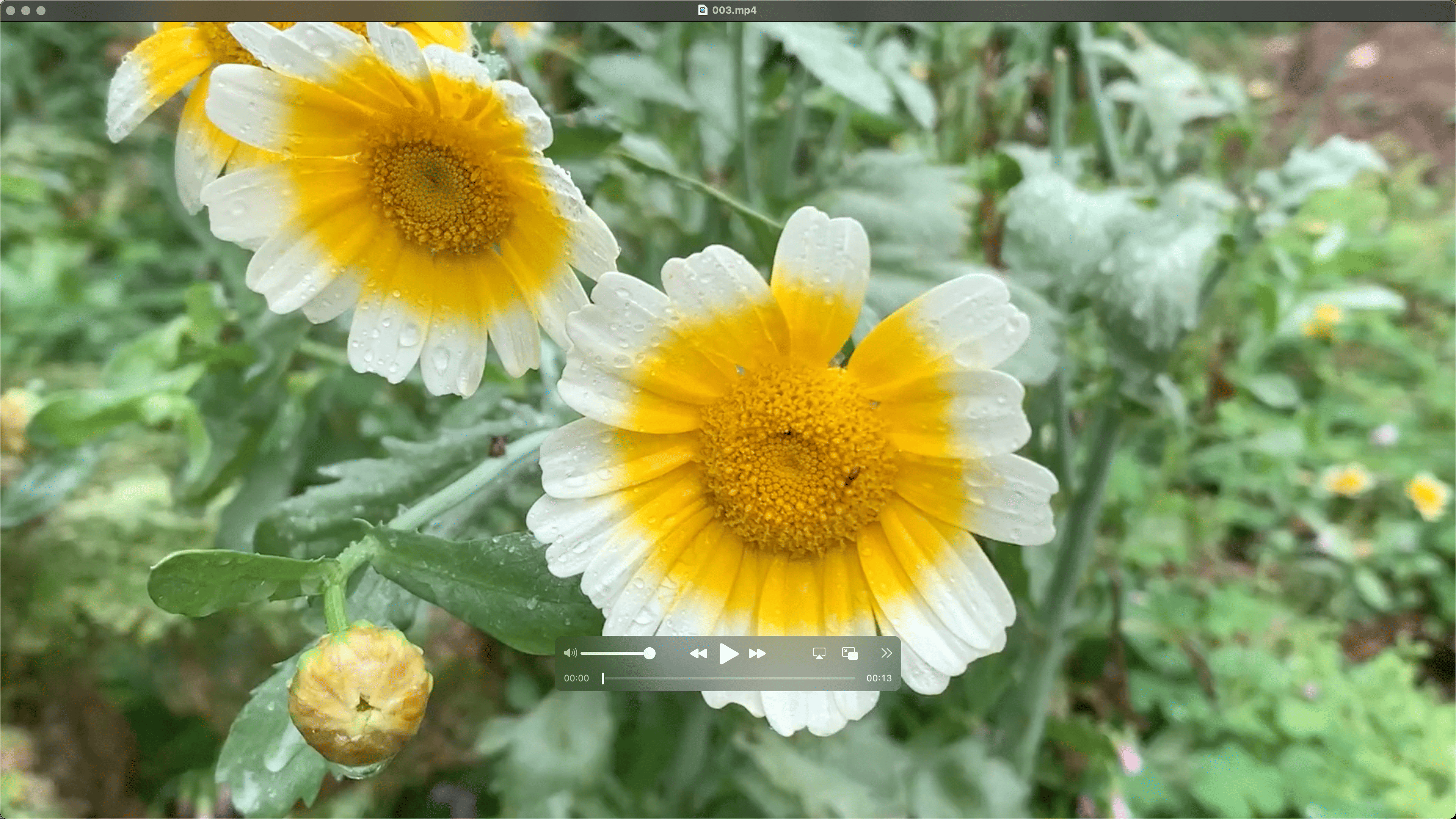
本文由CSDN博客爬虫自动获取并转换为Markdown格式


 浙公网安备 33010602011771号
浙公网安备 33010602011771号