



第五章 字符串及正则表达式
实例01:使用字符串拼接输出一个关于程序员的笑话
在IDLE中创建一个名称为programmer_splice.py的文件,然后在该文件中定义两个字符串变量,分别记录两名程序说的话,再将两个字符串拼接到一起,并且在中间拼接一个转义字符串(换行符),最后输出。
代码如下:
programmer_1 = '程序员甲:搞IT太辛苦了,我想换行......怎么办?' programmer_2 = '程序员乙:敲一下回车键' print(programmer_1 + '\n' + programmer_2)
运行结果如下:

实例02:截取身份证号码中的出生日期
在 IDLE中创建一个名称为idcard.py 的文件,然后在该文件中定义3个字符串变量,分别记录两名程序说的话,再从程序员甲说的身份证号中截取出出生日期,并组合成“YYYY年MM月DD日”格式的字符串将两个字符串拼接到一起,并且在中间拼接一个转义字符串(换行符),最后输出,输出截取到的出生日期和生日。
代码如下:
programer_1 = '你知道我的生日吗?' print('程序员甲说:', programer_1) programer_2 = '输入你的身份证号码。' print('程序员乙说:', programer_2) idcard = '123456199006277890' #截取生日 birthday = idcard[6:10] + '年' + idcard[10:12] + '月' +idcard[12:14] + '日' print('程序员乙说:', '你是' + birthday + '出生的,所以你的生日是' + birthday[5:])
运行结果如下:

实例03:输出被@的好友名称
在IDLE中创建一个名称为atfriend.py的文件,然后在该文件中定义一个字符串,内容为“@明日科技@扎克伯格@俞敏洪”,然后使用split()方法对该字符串进行分割,从而获取出好友名称,并输出。
代码如下:
str1 ='@明日科技 @扎克伯格 @俞敏洪' list1 = str1.split(' ') #用空格分割字符串,分成各个元素 #['@明日科技', '@扎克伯格', '@俞敏洪'] print('您@的好友有:') for item in list1: print(item[1:]) #输出每个好友名时,去掉@符号
运行结果如下:

实例04:通过好友列表生成全部被@的好友
在IDLE中创建一个名称为atfriend-join.py 的文件,然后在该文件中定义一个列表,保存一些好友名称,然后使用join()方法将列表中每个元素用空格+@符号进行连接,再在连接后的字符串前添加一个@符号,最后输出。
代码如下:
list_friend = ['明日科技', '扎克伯格', '俞敏洪', '马云', '马化腾'] #好友列表 str_friend = ' @'.join(list_friend) #用 空格+@ 符号进行连接 #使用join()方法时,第一个元素前不加分隔符,所以需要在前面加上@符号 at = '@' + str_friend print('您要@的好友:', at)
运行结果如下:

实例05:不区分大小写验证会员名是否唯一
在IDLE中创建一个名称为checkusername.py的文件,然后在该文件中定义一个字符串,内容为已经注册的会员名称,以”|“进行分隔,然后使用lower()方法将字符串全部转换为小写字母,接下来再应用input()函数从键盘中获取一个输入的注册名称,也将其全部转换为小写字母,再应用if……else语句和in关键字判断转换后的会员名是否存在转换后的会员名称字符串中,并输出不同的判断结果。
代码如下:
#假设已经注册的会员名称保存在一个字符串中,以“|”进行分隔 username_1 = '|MingRi|mr|mingrisoft|wGH|MRSoft|' username_2 = username_1.lower() #将会员名称字符串转换为小写 regname_1 = input('输入要注册的会员名称:') regname_2 = '|' + regname_1.lower() + '|' #将要注册的会员名称转换为小写 if regname_2 in username_2: print('会员名', regname_1, '已经存在!') else: print('会员名', regname_1, '可以注册!')
运行结果如下:


实例06:格式化不同的数值类型数据
在IDLE中创建一个名为formatnum.py的文件,然后在该文件中将不同类型的数据进行格式化并输出。
代码如下:
import math #以货币形式显示 print('1251+3950的结果是(以货币形式显示) : ¥{:,.2f}元'.format(1251+3950)) print('{0:.1f}用科学计数法表示:{0:E}'.format(120000.1)) #用科学计数法表示 print('Π取5位小数:{:.5f}'.format(math.pi)) #输出小数点后5位 print('{0:d}的16进制结果是:{0:#x}'.format(100)) #输出十六进制数 print('天才是由{:.0%}的灵感,加上 {:.0%}的汗水。'.format(0.01, 0.99))
运行结果如下:

实例07:验证输入的手机号码是否为中国移动的号码
在IDLE中创建一个名为checkmobile.py的文件,然后在该文件中导入Python的re模块,再定义一个验证手机号码的模式字符串,最后应用该模式字符串验证两个手机号码,并输出验证结果。
代码如下:
import re pattern = r'(13[4-9]\d{8})$|(15[01289]\d{8})$' #匹配手机号是:13 + 一位(4~9)数 + 8位数 或 15 + 一位[01289]数 + 8位数 mobile = '13634222222' match = re.match(pattern, mobile) if match == None: print(mobile, '不是有效的中国移动手机号码。') else: print(mobile, '是有效的中国移动手机号码。') mobile = '13144222221' match = re.match(pattern, mobile) if match == None: print(mobile, '不是有效的中国移动手机号码。') else: print(mobile, '是有效的中国移动手机号码。')
运行结果如下:

实例08:验证是否出现危险字符
在IDLE中创建一个名为checktnt.py的文件,然后在该文件中导入Python的re模块,再定义一个验证危险字符的模式字符串,最后应用该模式字符串验证两段文字,并输出验证结果。
代码如下:
import re pattern = r'(黑客)|(抓包)|(监听)|(Trojan)' #模式字符串 about = '我是一名程序员,我喜欢看黑客方面的图书,想研究一下Trojan。' match = re.search(pattern, about) if match == None: print(about, '@ 安全!') else: print(about, '@ 出现了危险词汇!') about = '我是一名程序员,我喜欢看计算机网络方面的图书,喜欢开发网站。' match = re.search(pattern, about) if match == None: print(about, '@ 安全!') else: print(about, '@ 出现了危险词汇!')
运行结果如下:

实例09:替换出现的危险字符
在IDLE中创建一个名为checktnt.py的文件,然后在该文件中导入Python的re模块,再定义一个验证危险字符的模式字符串,并应用该模式字符串验证两段文字,若出现危险字符则使用sub()方法进行替换。
代码如下:
import re pattern = r'(黑客)|(抓包)|(监听)|(Trojan)' #模式字符串 about = '我是一名程序员,我喜欢看黑客方面的图书,想研究一下Trojan。' sub = re.sub(pattern, '@_@', about) #模式替换 print(sub) about = '我是一名程序员,我喜欢看计算机网络方面的图书,喜欢开发网站。' sub = re.sub(pattern, '@_@', about) #模式替换 print(sub)
运行结果如下:

实例10:输出被@的好友名称(应用正则表达式)
在IDLE中创建一个名称为atfriendsplit1.py的文件,然后在该文件中定义一个字符串,内容为”@明日科技 @扎克伯格 @俞敏洪“,然后使用split()方法对该字符串进行分割,从而获取出好友名称,并输出。
代码如下:
import re str1 ='@明日科技 @扎克伯格 @俞敏洪' pattern = r'\s*@' #\s匹配单个的空白符,*匹配前面的字符零次或多次 list1 = re.split(pattern, str1) #用空格和@或单独的@分割字符串 print('您@的好友有:') for item in list1: if item != "": #输出不为空的元素 print(item)
运行结果如下:

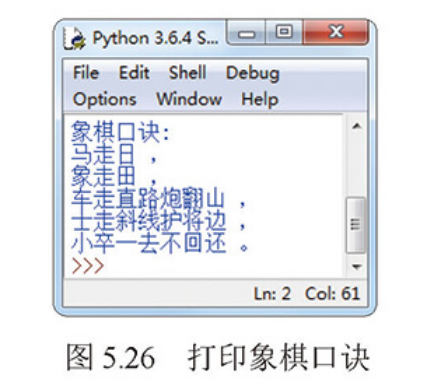
实战一:打印象棋口诀
下象棋前需要了解以下象棋口诀:
① 马走日
② 象走田
③ 车走直路炮翻山
④ 士走斜线护将边
⑤ 小卒一去不回还
应用字符串保存上面的象棋口诀并加上正确的标点符号输出。效果如图所示:
代码如下:
str1 = '马走日' str2 = '象走田' str3 = '车走直路炮翻山' str4 = '士走斜线护将边' str5 = '小卒一去不回还' s1 = ',' s2 = '。' print("象棋口诀:") print(str1 + s1) print(str2 + s1) print(str3 + s1) print(str4 + s1) print(str5 + s2)
运行结果如下:

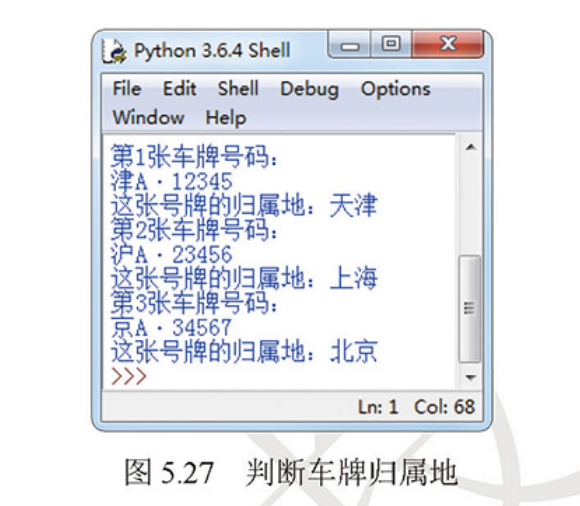
实战二:判断车牌归属地
根据车牌号码可以知道该车辆的归属地,本实战将实现输出指定车牌的归属地功能。效果如图所示:
代码如下:
str1 = '津A·12345','沪A·23456','京A·34567' for i in range(len(str1)): print('第' + str(i + 1) + '张车牌号码:\n' + str1[i]) if str1[i][0] == '津': #判断第i个元素的第0个字段是否符合条件 print("这张号牌的归属地:天津") elif str1[i][0] == '沪': print("这张号牌的归属地:上海") elif str1[i][0] == '京': print("这张号牌的归属地:北京")
运行结果如下:

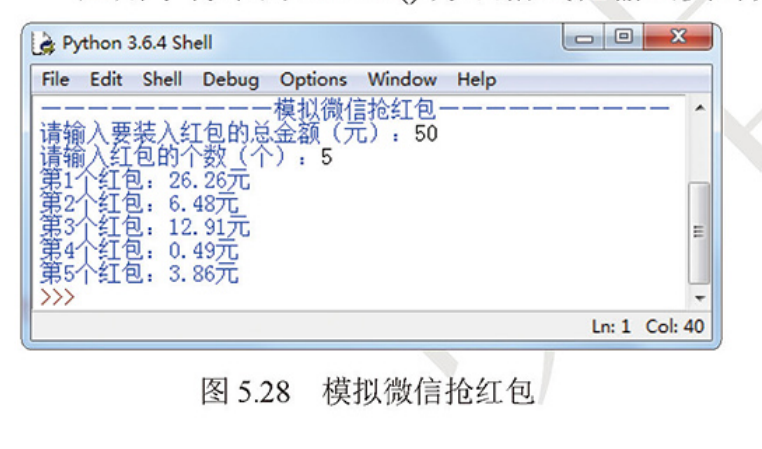
实战三:模拟微信抢红包
模拟微信抢红包(提示:本实例实现时需要应用生成随机数的random模块),效果如图所示:
代码如下:
import random import decimal print("--------------模拟微信抢红包-------------") money = float(input("请输入要装入红包的总金额(元):")) count = int(input("请输入红包的个数(个):")) for num in range(1, count + 1): # 1 ~ count if num == count: end = money #最后一人得剩余红包金额 else: end = random.uniform(0.01, money) #随机在0.01到红包总金额中取一个数 end = round(end, 2) #取小数点后两位 money = money - end money = round(money, 2) #取小数点后两位 print("第" + str(count) + "个红包:" + str(end) + "元")
运行结果如下:

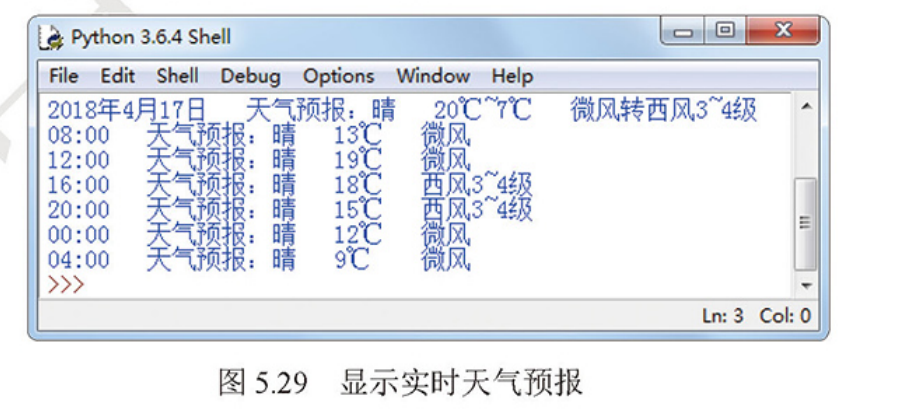
实战四:显示实时天气预报
应用字符串的format()方法格式化输出实时天气预报,效果如图所示。
代码如下:
weather='2018年4月17日 \t 天气预报:{:s} \t 20C~7°℃ \t 微风转西风3~4级\n \ 08:00 \t 天气预报:{:s} \t 13℃ \t 微风\n\ 12:00 \t 天气预报:{:s} \t 19℃ \t 微风\n\ 16:00 \t 天气预报:{:s} \t 18℃ \t 西风3~4级\n\ 20:00 \t 天气预报:{:s} \t 15℃ \t 西风3~4级\n\ 00:00 \t 天气预报:{:s} \t 12℃ \t 微风\n\ 04:00 \t 天气预报:{:s} \t 9℃ \t 微风' ans = weather.format('晴', '晴', '晴', '晴', '晴', '晴', '晴') print(ans)
运行结果如下:

实践1:匹配出由“数字、字母、特殊字符”这三种字符组成的8位密码
代码如下:
import re pattern = r"^(?![A-Za-z0-9]+$)(?![a-z0-9\\W]+$)(?![A-Za-z\\W]+$)(?![A-Z0-9\\W]+$)^.{8}$" string = ["asdf!@#$123123", "12138111", "@a345678"] for item in string: res = re.search(pattern, item) if res: print(item, "匹配成功") else: print(item, "匹配失败,不是由数字、字母、特殊字符组成的8位密码") # ^字符串开始 $字符串结尾 {8}8位 # "[A-Za-z0-9]"匹配大小写字母和数字其中一个字符, # "^[A-Za-z0-9]$"匹配只有一个大小写字母和数字字符的字符串 # +号:重复1到多次,"^[A-Za-z0-9]+$"匹配由多个数字大小字母组成的字符串 # ?!:不匹配 # (?![A-Za-z0-9]+$) 不匹配由多个 数字+大小写字母 组成的字符串 # (?![a-z0-9\\W]+$) 不匹配由多个 数字+小写字母+特殊字符 组成的字符串 # (?![A-Za-z\\W]+$) 不匹配由多个 大小写字母+特殊字符 组成的字符串 # (?![A-Z0-9\\W]+$) 不匹配由多个 数字+大写字母+特殊字符 组成的字符串 # ^.匹配除换行符以外的任意字符,因为排除了上面的组合,就剩下4种都包含的组合, # 即含有数字、大小写字母、特殊字符的组合
运行结果如下:

实践2:正则表达式(re模块)实践二:匹配出身份证属于广东省的身份证号码(提示:广东省身份证的开头两位数字为44)
代码如下:
import re # 44+13位数字 或 44+16位数字 或 44+15位数字+一位数字/X/x pattern = r"(^44\d{13}$)|(^44\d{16}$)|(^44\d{15})(\d|X|x)$" id = ["441502200211111234","441234567890111X","431212121212121","40111111111111X",] for item in id: if (len(item) == 15) or (len(item) == 18): search = re.search(pattern, item) # 模式匹配 if search == None: # 匹配失败 print(item + "不是广东省的身份证号码,头两位数字为:" + item[0:2]) else: # 匹配成功 print(item + "是广东省的身份证号码,头两位数字为:" + item[0:2]) else: #不符合长度要求 print(item + "不符合身份证号码格式")
运行结果如下:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号