




day5 字典、集合、时间方法、异常处理、os模块(系统相关模块)、pickle模块写入文件
创建字典
# 创建字典
adict = {}
dict(['ab', 'cd']) # {'a': 'b', 'c': 'd'}
bdict = dict([('name', 'bob'), ('age', 25)]) # {'name': 'bob', 'age': 25}
cdict = {}.fromkeys(['zhangsan', 'lisi', 'wangwu'], 11) # {'zhangsan': 11, 'lisi': 11, 'wangwu': 11}
for key in bdict:
print('%s : %s' % (key, bdict[key])) # age : 25
print('%(name)s: %(age)s' % bdict) # bob: 25
adict['email'] = 'tom@tedu.cn' # {'email': 'tom@tedu.cn'}
删除、清除、弹出
bdict.pop('age') # 弹出age和age的值
bdict.clear() # 清除
del adict['email'] # 删除key
作用于字典的函数
--- len():返回字典中元素的数目
--- hash():本身不是为字典设计的,但是可以判断某个对象是否可以作为字典的键
print(cdict) # {'zhangsan': 11, 'lisi': 11, 'wangwu': 11}
print(len(cdict)) # 输出3,元素有3个
print(hash()) # 判断给定的数据是不是可变的,数据不可变才可以作为键
字典常用的方法
print(cdict.keys()) # dict_keys(['zhangsan', 'lisi', 'wangwu'])
print(cdict.values()) # dict_values([11, 11, 11])
print(cdict.items()) # dict_items([('zhangsan', 11), ('lisi', 11), ('wangwu', 11)])
# get 方法
print(cdict.get('zhangsan')) # 取出字典中zhangsan的值,没有返回None
print(cdict.get('age', 'not found')) # 取出字典中age的值,没有返回not found
adict.update({'phone': '13455667788'}) # 把phone更新到字典
print(adict)
案例1:模拟用户登录信息
1.支持新用户注册,新用户和密码注册到字典中
2.支持老用户登陆,用户名和密码正确提示登陆成功
3.主程序通过循环询问进行何种操作,根据用户的选择,执行注册或登陆操作
import getpass
userdb = {}
def register():
username = input('username:')
if username in userdb:
print('%s is already exists.' % username)
else:
password = input('passworld:')
userdb[username] = password
def login():
username = input('username: ')
password = getpass.getpass('passworld: ')
if userdb.get(username) != password:
print('login failed!')
else:
print('login successful')
def show_menu():
cmds = {'0': register, '1': login}
prompt = """(0)register
(1)login
(2)exit
Please input your choices(0/1/2): """
while True:
choices = input(prompt)
if choices not in '012':
print('Invalid inout.Try again.')
if choices == '2':
break
cmds[choices]()
if __name__ == '__main__':
show_menu()
案例2:编写unix2dos的程序
1.windows文本文件的行结束标志是\r\n
2.类unix文本文件的行结束标志是\n
3.编写程序,将unix文本文件格式转换为windows的文本文件格式
import sys
def unix2dos(fname):
des_fname = fname + '.txt' # 目标文件名=源文件名加上.txt后缀
with open(fname) as src_fobj:
with open(des_fname, 'w') as des_fobj:
for line in src_fobj:
line = line.rstrip() + '\r\n' # 取出一行字符,取出字符右边的空白字符,再加上\r\n
des_fobj.write(line)
if __name__ == '__main__':
unix2dos(sys.argv[1]) # 通过位置参数穿进去文件名
案例3:编写类进度条程序
1.在屏幕上打印20个#号
2.符号@从20个#号穿过
3.当@符号到达尾部,再从头开始
# 先写一个倒计时的小程序
import time
import sys
for i in range(10, -1, -1):
print('\r %s' % i, end='')
sys.stdout.flush()
time.sleep(1)
print('\n %s' % '新年快乐!!!')
案例代码:
import time
length = 19
count = 0
while True:
print('\r%s@%s' % ('#' * count, '#' * (length - count)), end='')
time.sleep(0.5)
if count == length:
count = 0
count += 1
集合(无值得字典,集合里的东西不能重复)
创建集合
--- 数学上,把set称作由不同的元素组成的集合,集合(set)的成员通常被称为集合元素
--- 集合对象是一组无序排列的可哈希的值
--- 集合有两种类型
1.可变集合set
2.不可变集合frozenset
print(set('hello')) # {'h', 'o', 'e', 'l'} 可变集合,不重复
print(set(['hello', 'world'])) # {'hello', 'world'}
print(frozenset('hello')) # frozenset({'h', 'o', 'e', 'l'}) 不可变集合
集合类型操作符
--- 集合支持in和not in进行成员关系判断
--- 能够通过len()取长度
--- 能够使用for循环遍历
--- 不能取切片,没有键
s1 = {'h', 'o', 'e', 'l'}
print(len(s1)) # 输出 4
for ch in s1:
print(ch) # 输出olhe,没有一定的顺序
| : 联合,取并集
& :交集
- :差补
s2 = set('abc')
s3 = set('bcd')
print(s2 | s3) # 取并集 {'a', 'd', 'b', 'c'}
print(s2 & s3) # 取交集 {'c', 'b'}
print(s2 - s3) # 取差补 {'a'}
print(s3 - s2) # 取差补 {'d'}
集合内建方法
set.add() : 添加成员
set.update() : 批量添加成员
set.remove() : 移除成员
aset = set('abc')
aset.add('new')
print(aset) # {'b', 'a', 'c', 'new'}
aset.update(['aaa', 'bbb'])
print(aset) # {'c', 'new', 'aaa', 'b', 'a', 'bbb'}
aset.remove('aaa')
print(aset) # {'bbb', 'a', 'new', 'b', 'c'}
--- s.issubset(t) : 如果s是t的子集,则返回True,否则返回False
--- s.issuperset(t) : 如果s是t的超集, 则返回True,否则返回False
--- s.union(t) : 返回的是一个新的集合,该集合是s和t的并集,类似上面的 |
--- s.intersection(t) : 返回一个新集合,该集合是s和t的交集,类似上面的 &
--- s.difference(t) : 返回一个新集合,该集合是s的成员,但不是t的成员,类似上面的 -
cset = set('abcde')
dset = set('bcd')
print(cset.issubset(dset)) # cset是dset的子集吗?返回False
print(cset.issuperset(dset)) # cset是dset的超集吗?返回True
利用集合,查找两个文件中不一样的行,并写入新文件
with open('a文件') as fobj: #
aset = set(fobj)
with open('b文件') as fobj:
bset = set(fobj)
with open('存储结果的文件', 'w') as fobj:
fobj.writelines(aset - bset)
时间方法(time模块、datetime模块)
时间戳:从1970年1月1日0点开始到当前的秒数
UTC时间:世界协调时间,格林威治时间,世界标准时间。中国在UTC+8
DST:夏令时
9元祖(struct_time): 由9个元素组成
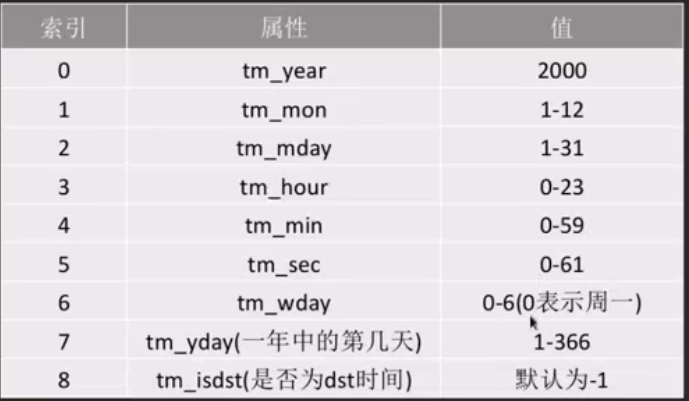
time 模块的方法
import time
print(time.localtime()) # 返回当前时间的九元组
print(time.time()) # 返回和1970年1月1日8:00的 相差的秒数,常用的
print(time.gmtime()) # 返回当前时间的九元组,以0时区格林威治的时间为准
t = time.localtime()
print(time.mktime(t)) # 把九元组时间转换成时间戳
time.sleep(1) # 睡眠1s
time.asctime() # 如果有参数,是九元组的形式
time.ctime() # 返回当前时间,参数是时间戳,常用
print(time.strftime('%Y-%m-%d')) # 2020-04-08 返回当前年月日,常用
time.strptime('2020-04-09', "%Y-%m-%d") # 返回九元组时间格式
print(time.strftime("%H:%M:%S")) # 16:37:41 返回当前时分秒
时间的表示对应的符号:
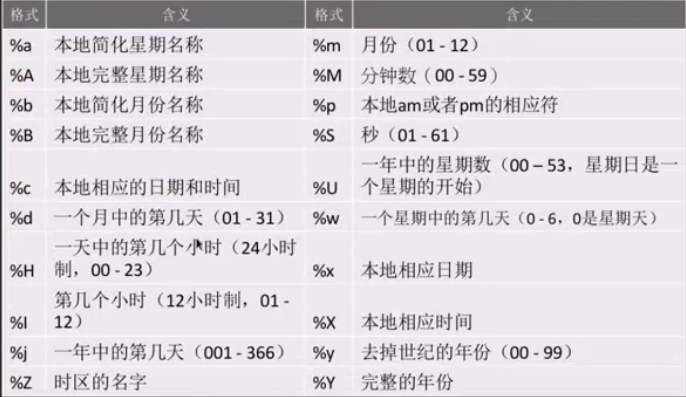
datetime模块(部分)
from datetime import datetime
from datetime import timedelta
print(datetime.today()) # 返回当前本地时间
print(datetime.now()) # 返回当前本地时间
print(datetime.strptime('2018-09-22', '%Y-%m-%d')) # 2018-09-22 00:00:00 返回datetime对象
dt = datetime.today()
days = timedelta(days=90, hours=3) # 90天3小时候是什么时候,常用
dt2 = dt + days
print(dt2) # 2020-07-07 19:50:41.892607
# 分别查看年月日时分秒等
print(dt2.year)
print(dt2.month)
print(dt2.day)
print(dt2.hour)
print(dt2.minute)
print(dt2.second)
异常处理
当python程序发现错误时,为了不使程序崩溃,使用异常处理
将有可能发生异常的语句放进try里面执行,except捕获异常
| 异常 | 描述 |
| NameError | 未申明、初始化对象 |
| IdexError | 序列中没有此索引 |
| SyntaxError | 语法错误 |
| KeyboardInterrupt | 用户中断执行 |
| EOFError | 没有内建输入 |
| IOError | 输入、输出操作失败 |
try:
n = int(input("number: "))
result = 100/n
print(result)
except ValueError: # 值错误
print("invalid number")
except ZeroDivisionError: # 0不被允许做除数
print("0 not allowed")
except EOFError: # ctrl+d
print("bye-bye")
except KeyboardInterrupt: # ctrl+c
print("bye-bye")
print('Done')
或者
# 合并
try:
n = int(input("number: "))
result = 100/n
print(result)
except (ValueError, ZeroDivisionError):
print("invalid number")
except (EOFError, KeyboardInterrupt):
print("\nbye-bye")
print('Done')
或者:
try:
n = int(input("number: "))
result = 100 / n
except (ValueError, ZeroDivisionError):
print("invalid number")
except (EOFError, KeyboardInterrupt):
print("\nbye-bye")
else: # 异常不发生时才执行else子句
print(result)
finally: # 不管发不发生异常都执行的语句
print('Done')
# 常用形式有try-except和try-finally
raise语句(触发异常)
想要引发异常,最简单的形式就是输入关键字raise,后面跟要引发的异常的名称
执行raise语句时,python会创建指定的异常类的一个对象
raise语句还可以指定对异常对象进行初始化的参数
>>> raise ValueError('我错了')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 我错了
案例5:自定义异常
1.编写第一个函数,函数接受姓名和年龄,如果年龄不在1到120之间,产生ValueError异常
2.编写第二个函数,函数接受姓名和年龄,如果年龄不在1-120之间,产生断言异常
def set_age(name, age):
if not 1 < age < 120:
raise ValueError('年龄超过范围') # 自定义触发异常
print('%s is %s years old' % (name, age))
def set_age2(name, age):
assert 0 < age < 120, '年龄超过范围' # 断言异常
print('%s is %s years old' % (name, age))
if __name__ == '__main__':
set_age('tom', 12)
set_age2('harry', 200)
os模块(系统相关模块)
对文件系统化的访问大多通过python的os模块实现
该模块是python访问操作系统功能的主要接口
有些方法,如copy等,没有提供,可以使用shutil模块作为补充
import os
print(os.getcwd()) # 显示当前路径
print(os.listdir()) # 显示当前目录下的东西
print(os.listdir('E:\python\day01')) # 显示当前路径目录下的东西
os.mkdir('E:\python\ceshi') # 创建ceshi文件夹
os.chdir('E:\python\ceshi') # cd 路径下去
os.mknod('test.txt') # 在当前创建文件
os.symlink('/etc/hosts', 'zhuji') # ln -s /etc/hosts zhuji
os.path.isfile('test.txt') # 判断test.txt是不是文件
os.path.isdir('/etc') # 判断etc是不是目录
os.path.islink('zhuji') # 判断zhuji是不是软连接
os.path.exists('/tmp') # 判断tmp目录是否存在
os.path.split('/tmp/abc/aaa.txt') # 切割路径
os.path.join('/home/tom/', 'xyz.txt') # 拼接路径
os.path.abspath('test.txt') # 返回当前文件的绝对路径
pickle模块存储
以前的文件写入,只能写入字符串,如果希望把任意数据对象写入文件,取出来的时候数据类型不变,就用到pickle
import pickle
shop_list = ['apple', 'eggs', 'peach']
with open('E:\python\day01\shop.data', 'wb') as fobj:
pickle.dump(shop_list, fobj) # 将列表里的数据写入文件,直接打开看是乱码
with open('E:\python\day01\shop.data', 'rb') as dobj:
mylist = pickle.load(fobj) # 以rb的方式打开文件,用pickle方式读取
print(mylist)

