精通scrapy爬虫02
Scrapy框架流程图
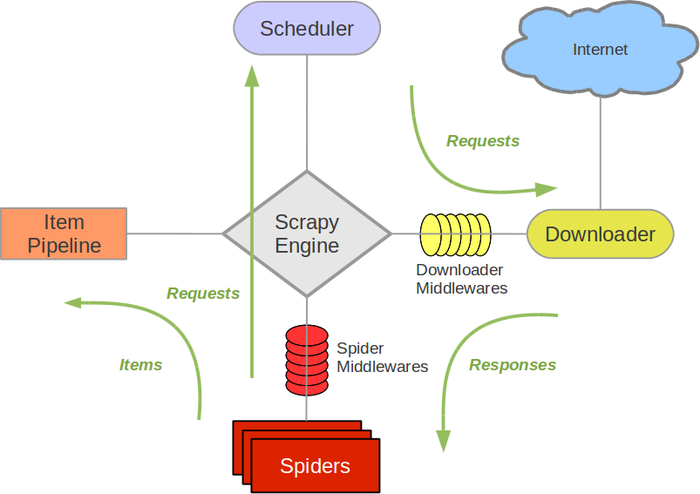
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
对于用户来说,Spider是最核心的组件,Scrapy爬虫开发是围绕实现Spider展开的。
Scrapy的运作流程
代码写好,程序开始运行...
引擎:Hi!Spider, 你要处理哪一个网站?
Spider:老大要我处理xxxx.com。
引擎:你把第一个需要处理的URL给我吧。
Spider:给你,第一个URL是xxxxxxx.com。
引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request请求给我。
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
管道``调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
Request
在实际应用中,我们几乎只调用Request的构造器创建对象,但也可以根据需求访问Request对象的属性,常用的有以下几个:
● url
● method
● headers
● body
● meta
Response
虽然HtmlResponse对象有很多属性,但最常用的是以下的3个:
● xpath(query)
● css(query)
● urljoin(url)
前两个方法用于提取数据,后一个方法用于构造绝对url。
Spider开发流程
实现一个Spider子类的过程很像是完成一系列填空题,Scrapy框架提出以下问题让用户在Spider子类中作答:
● 爬虫从哪个或哪些页面开始爬取?
● 对于一个已下载的页面,提取其中的哪些数据?
● 爬取完当前页面后,接下来爬取哪个或哪些页面?
上面问题的答案包含了一个爬虫最重要的逻辑,回答了这些问题,一个爬虫也就开发出来了。
对上一章的源码分析
import scrapy
class BookSpider(scrapy.Spider):
#每个爬虫的唯一标识
name = "books"
#定义爬虫的起始点
start_urls = ['http://books.toscrape.com/']
def parse(self, response):
# 提取数据
# 每一本书的信息在<article class="product_pod">中,我们使用
# css()方法找到所有这样的article 元素,并依次迭代
for book in response.css('article.product_pod'):
# 书名信息在article > h3 > a 元素的title属性里
name = book.xpath('./h3/a/@title').extract_first()
price = book.css('p.price_color::text').extract_first()
yield {
'name':name,
'price':price,
}
# 提取链接
# 下一页的url 在ul.pager > li.next > a 里面
next_url = response.css('ul.pager li.next a::attr(href)').extract_first()
if next_url:
#如果找到下一页的URL,得到绝对路径,构造新的Request 对象
next_url = response.urljoin(next_url)
yield scrapy.Request(next_url, callback=self.parse)
start_urls通常被实现成一个列表,其中放入所有起始爬取点的url(例子中只有一个起始点)。看到这里,大家可能会想,请求页面下载不是一定要提交Request对象么?而我们仅定义了url列表,是谁暗中构造并提交了相应的Request对象呢?通过阅读Spider基类的源码可以找到答案,相关代码如下:
class Spider(object_ref):
...
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
def parse(self, response):
raise NotImplementedError
...
以下是通过实现start_requests方法定义起始爬取点的示例代码(改写BooksSpider):
class BooksSpider(scrapy.Spider):
# start_urls = ['http://books.toscrape.com/']
# 实现start_requests 方法, 替代start_urls类属性
def start_requests(self):
yield scrapy.Request('http://books.toscrape.com/',
callback=self.parse_book,
headers={'User-Agent': 'Mozilla/5.0'},
dont_filter=True)
# 改用parse_book 作为回调函数
def parse_book(self, response):
...
再执行一次看看效果,保存为json格式的
scrapy crawl books -o books.json
小结
本章先讲解了Scrapy的框架结构以及工作原理,然后又介绍了Scrapy中与页面下载相关的两个核心对象Request和Response,有了这些知识的铺垫,最后我们讲解了实现一个Spider的开发流程。关于编写Spider时涉及的一些技术细节在后面章节继续讨论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号