
spark orc文件存储探索
一,ORC 定义
ORC File,它的全名是Optimized Row Columnar(ORC)文件,其实就是对RCFile做了一些优化。据官方文档介绍,这种文件格式可以提供一种高效的方法来存储Hive数据。它的设计目标是来克服Hive其他格式的缺陷。运用ORC文件可以提高Hive的读,写以及处理数据的性能。
和RCFile格式相比,ORC文件格式有以下优点:
- ORC中的特定的序列化与反序列化操作可以使ORC file writer根据数据类型进行写出。
- 提供了多种RCFile中没有的indexes,这些indexes可以使ORC的reader很快的读到需要的数据,并且跳过无用数据,这使得ORC文件中的数据可以很快的得到访问。
- 由于ORC file writer可以根据数据类型进行写出,所以ORC可以支持复杂的数据结构(比如Map等)。
- 除了上面三个理论上就具有的优势之外,ORC的具体实现上还有一些其他的优势,比如ORC的stripe默认大小更大,为ORC writer提供了一个memory manager来管理内存使用情况。
- 每个任务只输出单个文件,这样可以减少NameNode的负载。
二、一些概念
列式存储:可以理解为将一张表中的数据 按照每一列单独拆开存储
相对于关系数据库中通常使用的行式存储,在使用列式存储时每一列的所有元素都是顺序存储的。由此特点可以给查询带来如下的优化:
- 查询的时候不需要扫描全部的数据,而只需要读取每次查询涉及的列,这样可以将I/O消耗降低N倍,另外可以保存每一列的统计信息(min、max、sum等),实现部分的谓词下推。
- 由于每一列的成员都是同构的,可以针对不同的数据类型使用更高效的数据压缩算法,进一步减小I/O。
- 由于每一列的成员的同构性,可以使用更加适合CPU pipeline的编码方式,减小CPU的缓存失效。
三、orc的文件格式。
orc文件有如下结构快:block,stripe,row_group,stream,index data,Row data,fileFooter,postscript
1、orc在hdfs上存储,为适应hdfs区块存储思想会将orc文件划分成block块(类比于hdfs的切片),orc的block块大小一般和hdfs的block块大小一致通过配置( hive.exec.orc.default.block.size 默认256M)指定
2、一组行形成一个stripe(stripe是对数据集按照行拆分存储的,stripe的内部是对数据按照列式存储),每个block块中包含多个stipe,stipe大小通过参数( hive.exec.orc.default.stripe.size 默认64M)指定。应尽量避免strip跨hdfs:block存储,否则在解析stipe时会存在IO跨节点的数据请求,从而增加了系统资源开销。所以,一般orc:block块大小是orc:stripe大小的整数倍。如果不是这样的话,会出现block块不能够被整数个stipe完整填满,需要关闭跨hdfs:block的数据存储,需要指定(hive.exec.orc.default.block.padding=false)关闭块存储。另外需要指定最小磁盘利用空间( hive.exec.orc.block.padding.tolerance 默认0.05,例如orc:block=256M,256*0.05=12.5M),hdfs:block块剩余磁盘空间低于此值将放弃使用这个block。
3、row group:索引的最小单位,一个stripe中包含多个row group,默认为10000个值组成。
4、stream:一个stream表示文件中一段有效的数据,包括索引和数据两类。索引stream保存每一个row group的位置和统计信息,数据stream包括多种类型的数据,具体需要哪几种是由该列类型和编码方式决定。
ORC文件包含一组组的行数据,称为stripe,除此之外,ORC文件的文件页脚还包含一些额外的辅助信息。在ORC文件文件的最后,有一个被称为postscript的区,它主要是用来存储压缩参数及压缩页脚的大小。
在默认情况下,一个stripe的大小为250MB。大尺寸的条带使得从HDFS读数据更高效。
在文件页脚里面包含了该ORC文件文件中条的信息,每个条纹中有多少行,以及每列的数据类型。当然,它里面还包含了列级别的一些聚合的结果,比如:count,min,max和sum。下图显示出可ORC文件文件结构:
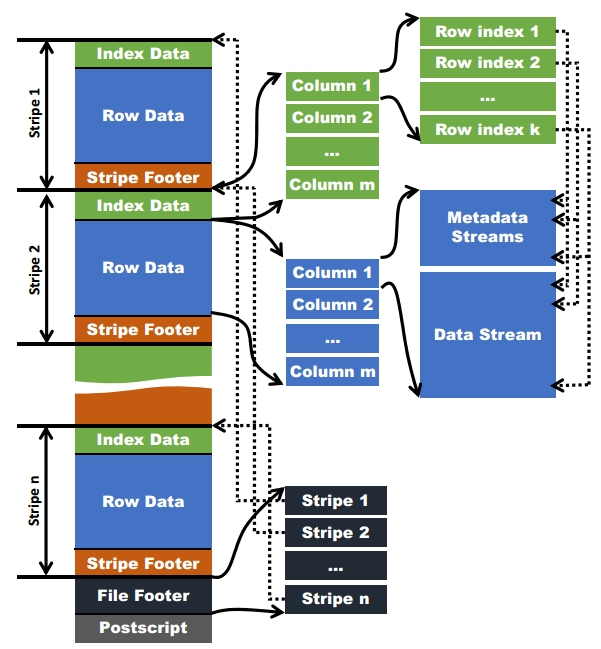
四、索引
ORC文件中是稀疏索引
ORC中有两种索引类型:1.数据统计索引;2.位置指针索引
数据分析索引
用这个索引跳过读取不必要的数据
ORC writer生成ORC文件时,会创建这个索引文件,统计信息:数据条数,max, min, sum值;对text和binary类型会记录长度;
复杂数据类型:Array, Map, Struct, Union,子字段类型也会记录这些统计信息
Data Statistics三个级别
- 文件级别
在ORC文件的末尾会记录文件级别的统计信息,记录整个文件中columns的统计信息,主要用于查询的优化,也可以为一些简单的聚合查询比如max, min, sum输出结果 - strip级别
会保存每个字段stripe级别的统计信息,ORC reader使用这些信息,确定需要读哪些stripe - index group级别
逻辑上将一个column的index以一个给定的值,分割为多个组,比如10000为一组,进行统计;
hive查询引擎会将where条件中的约束传递给ORC reader,这些reader根据组级别的统计信息,过滤掉不必要的数据;整个值可以配置
位置指针索引
ORC reader需要两个位置,才能操作
metadata streams和data streams中每个group开始位置
每个stripe有多个group,ORC reader需要知道每个group的metadata streams和data streams开始位置,右边虚线就是这种例子- stripes的开始位置
一个ORC可能包含多个stripes,一个HDFS block也能包含多个stripes,为了快速定位到stripe的位置,信息保存在File Footer中
ORC 中两种索引实现:Row Group Index 、 Bloom Filter Index
两种索引实现比较:
具体参考:http://lxw1234.com/archives/2016/04/632.htm#comments
五、内存管理
当ORC writer写数据时,会将整个stripe保存在内存中。由于stripe的默认值一般比较大,当有多个ORC writer同时写数据时,可能会导致内存不足。(stripe应该比block小,block是stripe的整数倍最好)为了现在这种并发写时的内存消耗,ORC文件中引入了一个内存管理器。在一个Map或者Reduce任务中内存管理器会设置一个阈值,这个阈值会限制writer使用的总内存大小。当有新的writer需要写出数据时,会向内存管理器注册其大小(一般也就是stripe的大小),当内存管理器接收到的总注册大小超过阈值时,内存管理器会将stripe的实际大小按该writer注册的内存大小与总注册内存大小的比例进行缩小。当有writer关闭时,内存管理器会将其注册的内存从总注册内存中注销。
六、参数
| 参数值 | 默认值 | 声明 |
| hive.exec.orc.default.stripe.size | 256*1024*1024 | stripe的默认大小 |
其余参数可以参考:https://blog.csdn.net/u010990043/article/details/82842974

 浙公网安备 33010602011771号
浙公网安备 33010602011771号