

kafka学习笔记
一、什么是kafka
kafka早期是由领英公司开发,后来'捐'给了Apache基金会。
kafka是Apache基金会的顶级项目,是一款消息队列产品,用于临时缓存输出的产品。
同类型产品有很多,比如RabbitMQ,RocketMQ,ActiveMQ等。
官网地址:
https://kafka.apache.org/
二、kafka单点部署
1.下载kafka
[root@elk91 ~]# wget https://dlcdn.apache.org/kafka/3.9.0/kafka_2.13-3.9.0.tgz
2.解压软件包
[root@elk91 ~]# tar xf kafka_2.13-3.9.0.tgz -C /usr/local/
3.修改kafka配置文件
[root@elk91 ~]# vim /usr/local/kafka_2.13-3.9.0/config/server.properties
...
# kafka的唯一标识
broker.id=91
# 修改数据目录
log.dirs=/var/lib/kafka
# 指定kafka的元数据存储在zookeeper集群的路径(znodes)
zookeeper.connect=10.0.0.91:2181,10.0.0.92:2181,10.0.0.93:2181/dezyan-kafka-3.9.0
4.配置环境变量
[root@elk91 ~]# cat /etc/profile.d/kafka.sh
#!/bin/bash
export KAFKA_HOME=/usr/local/kafka_2.13-3.9.0
export PATH=$PATH:$KAFKA_HOME/bin
[root@elk91 ~]#
[root@elk91 ~]# source /etc/profile.d/kafka.sh
5.将kafka放在后台运行
[root@elk91 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@elk91 ~]#
[root@elk91 ~]# ss -ntl | grep 9092
LISTEN 0 50 *:9092 *:*
6.在Zookeeper集群查看数据是否写入
- 访问zkWEBUI查看即可
- 将zkWeb放入后台运行
/usr/local/jdk1.8.0_291/bin/java -jar zkWeb-v1.2.1.jar &>/dev/null &
root@elk91:~# ss -ntl | egrep "2181|8099|9092"
LISTEN 0 100 *:8099 #webUI
LISTEN 0 50 *:9092 #kafka
LISTEN 0 50 *:2181 #zookeeper

三、kafka常见术语
- broker
表示每个kafka节点。
- producer(生产者)
往broker写入数据的一方。
- consumer(消费者)
从broker读取数据的一方。
- topic(主题)
指的是Producer和consumer从某个特定的topic读写数据。
换句话说,就是从kafka节点读写数据的逻辑单元。
- partitions(分区):
一个topic可以有多个partition,数据分布式存储在某个特定的parititon。
但是partition依旧是逻辑单元,但并是实际存储数据的载体。
- replica(副本):
每个分区最少有一个replica,是数据的实际载体。
当某个paritition的replica数量大于1时,就可以实现数据的高可用。
此时,副本区分Leader和follower
四、kafka集群部署
1.拷贝程序到其他节点
[root@elk91 ~]# scp -r /usr/local/kafka_2.13-3.9.0/ 10.0.0.92:/usr/local/
[root@elk91 ~]# scp -r /usr/local/kafka_2.13-3.9.0/ 10.0.0.93:/usr/local/
[root@elk91 ~]# scp /etc/profile.d/kafka.sh 10.0.0.92:/etc/profile.d/
[root@elk91 ~]# scp /etc/profile.d/kafka.sh 10.0.0.93:/etc/profile.d/
2.其他节点修改配置文件
[root@elk92 ~]# sed -i '/^broker.id/s#91#92#' /usr/local/kafka_2.13-3.9.0/config/server.properties
[root@elk92 ~]# grep ^broker.id /usr/local/kafka_2.13-3.9.0/config/server.properties
broker.id=92
[root@elk93 ~]# sed -i '/^broker.id/s#91#93#' /usr/local/kafka_2.13-3.9.0/config/server.properties
[root@elk93 ~]# grep ^broker.id /usr/local/kafka_2.13-3.9.0/config/server.properties
broker.id=93
3.其他节点启动kafka
[root@elk92 ~]# source /etc/profile.d/kafka.sh && kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@elk92 ~]#
[root@elk92 ~]# ss -ntl | grep 9092
LISTEN 0 50 *:9092 *:*
[root@elk93 ~]# source /etc/profile.d/kafka.sh && kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@elk93 ~]#
[root@elk93 ~]# ss -ntl | grep 9092
LISTEN 0 50 *:9092 *:*
4.zookeeper验证查看
- 访问查看http://10.0.0.91:8099/#

五、集群部署报错解决
1.未知的主机异常
- 问题出现:查看topic列表超时
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --list
Error while executing topic command : Timed out waiting for a node assignment. Call: listTopics
[2025-03-17 10:54:01,106] ERROR org.apache.kafka.common.errors.TimeoutException: Timed out waiting for a node assignment. Call: listTopics
(org.apache.kafka.tools.TopicCommand)
- 查看日志报错
[root@elk91 ~]# tail -100f /usr/local/kafka_2.13-3.9.0/logs/server.log
...
[2025-03-17 10:53:58,604] WARN [Controller id=91, targetBrokerId=93] Error connecting to node elk93:9092 (id: 93 rack: null) (org.apache.kafka.clients.NetworkClient)
java.net.UnknownHostException: elk93
#UnknownHostException 提示未知的主机名
- 问题分析及解决方案
问题:
未知的主机异常,在连接kakfa集群时,其做了反向解析。
解决方案1:
在本地hosts解析,添加各个节点的解析
解决方案2:
编辑配置文件,指定节点监听IP地址,并重启kafka
[root@elk91 ~]# vim /usr/local/kafka_2.13-3.9.0/config/server.properties
...
# 表示监听的IP地址,若不指定,则默认主机为当前主机名,除非你hosts文件做了解析
#92节点改为对应IP,93节点也是
listeners=PLAINTEXT://10.0.0.91:9092
...
[root@elk91 ~]# kafka-server-stop.sh
[root@elk91 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
六、kafka常用脚本管理之topic管理
1.查看现有的topics列表
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --list
注意:如果当前没有任何的topic,此命令会夯住
2.创建指定分区副本的topic
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --create --partitions 3 --replication-factor 2 --topic dezyan-linux96
- 命令参数详解
# kafka-topics.sh
这是 Kafka 提供的一个命令行工具,用于管理 Kafka 主题(如创建、删除、修改和查看主题信息)。
--bootstrap-server
指定 Kafka Broker 的地址,用于连接 Kafka 集群。
--create
指定要执行的操作是创建一个新的 Kafka 主题。
--partitions 3
指定新创建的主题的分区数(partitions)。分区数决定了数据的并行度和可扩展性。
--replication-factor 2
指定新创建的主题的副本数(replication factor)。副本数决定了数据的冗余程度,以提高可用性和容错性。
--topic dezyan-linux96
指定要创建的主题名称。
- 查询验证
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --list
dezyan-linux96
3.查看分区的详细信息
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --topic dezyan-linux96 --describe
Topic: dezyan-linux96 TopicId: BjioKLaiQ1-DqAcOwgCcZw PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: dezyan-linux96 Partition: 0 Leader: 93 Replicas: 93,91 Isr: 93,91 Elr: N/A LastKnownElr: N/A
Topic: dezyan-linux96 Partition: 1 Leader: 91 Replicas: 91,92 Isr: 91,92 Elr: N/A LastKnownElr: N/A
Topic: dezyan-linux96 Partition: 2 Leader: 92 Replicas: 92,93 Isr: 92,93 Elr: N/A LastKnownElr: N/A
- 命令参数详解
--describe 查看分区详细信息
4.修改分区数【只能调大,不能调小】
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --topic dezyan-linux96 --alter --partitions 5
5.删除topic
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --topic dezyan-linux96 --delete
- 命令参数详解
--delete 删除指定分区
七、kafka常用脚本管理之producer和consumer
1.创建生产者程序【首次写入数据时,若topic不存在,则默认会自动创建】
[root@elk91 ~]# kafka-console-producer.sh --bootstrap-server 10.0.0.93:9092 --topic linux96
>www.dezyan.com
[2025-03-17 11:09:14,163] WARN [Producer clientId=console-producer] The metadata response from the cluster reported a recoverable issue with correlation id 7 : {linux96=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
#该提示信息是提示你没有此topic,已经为你自动创建
2.查看现有的topics列表
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --list
linux96
3.创建消费者程序【创建消费者后,再次在生产者终端写入数据'test1,are you ok'】
[root@elk92 ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.91:9092 --topic linux96 # 默认从最新的offset获取数据。
[root@elk93 ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.92:9092 --topic linux96 --from-beginning # 从最老的offset获取数据
4.创建消费者后,会自动生成一个新的topic,名为'__consumer_offsets',里面存储的是offset信息。
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --list
__consumer_offsets
linux96
八、kafka常用脚本管理之consumer group
1.常用概念
-
consumer group
- 消费者组,每个消费者都隶属于某个消费者组。
- 换句话说,一个消费者组可以有一个或多个消费者。
-
offset
- 用于标识每个parition数据的位置点,每个paritition的数据都是顺序的,我们将每个paritition最后一个偏移量,称为LEO(Log End Offset)。
-
rebalance
- 重平衡,指的是同一个消费者组的消费者重新分配partition的过程
- 当一个消费者组的消费者数量发生变化或者partition数量发生变化时,都会触发rebalance。
2.消费者组案例
①创建topic
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --create --partitions 3 --replication-factor 2 --topic dezyan-linux96
#查看
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --describe --topic dezyan-linux96
②创建生产者写入测试数据
[root@elk91 ~]# kafka-console-producer.sh --bootstrap-server 10.0.0.93:9092 --topic dezyan-linux96
>abc
③创建消费者并指定消费者组
[root@elk92 ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.91:9092 --topic dezyan-linux96 --consumer-property group.id=xixi --from-beginning
abc
3.消费者组的基本管理
①查看消费者组列表
[root@elk91 ~]# kafka-consumer-groups.sh --bootstrap-server 10.0.0.92:9092 --list
②查看指定消费者组的详细信息
[root@elk91 ~]# kafka-consumer-groups.sh --bootstrap-server 10.0.0.92:9092 --group xixi --describe ;echo
③再次启动新的消费者并指的同一个消费者组
[root@elk93 ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.92:9092 --topic dezyan-linux96 --consumer-property group.id=xixi --from-beginning
④再次查看指定消费者组的详细信息
[root@elk91 ~]# kafka-consumer-groups.sh --bootstrap-server 10.0.0.92:9092 --group xixi --describe ;echo
⑤启动多个生产者和消费者加入同一个消费者组测试
4.总结
一个消费者组可以有多个消费者,消费者的数量可以多于topic的分区数,但是多余的消费者并不会消费分区的数据。说白了有空闲的消费者是不干活的。
也就是说,假设topic有三个分区,有4个消费者,只有其中3个消费者会进行消费,剩余的一个会进入空闲等待状态。
当该消费者组的消费者有退出时,此时空闲的消费者才能"上位"消费分区的数据。
九、kafka的JVM调优
1.调优思路
-
建议kafka的JVM的堆内存设置为6GB即可。
-
参考配置: 【JDK8,JDK11,JDK17,JDK21】
KAFKA_OPTS="-Xmx6g -Xms6g -XX:MetaspaceSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50
-XX:MaxMetaspaceFreeRatio=85"
2.学习环境配置
- 配置256MB即可
[root@elk91 ~]# vim /usr/local/kafka_2.13-3.9.0/bin/kafka-server-start.sh
...
export KAFKA_HEAP_OPTS="-Xmx256m -Xms256m"
...
[root@elk91 ~]#
[root@elk91 ~]# scp /usr/local/kafka_2.13-3.9.0/bin/kafka-server-start.sh 10.0.0.92:/usr/local/kafka_2.13-3.9.0/bin/
[root@elk91 ~]# scp /usr/local/kafka_2.13-3.9.0/bin/kafka-server-start.sh 10.0.0.93:/usr/local/kafka_2.13-3.9.0/bin/
3.重启kafka集群
停止kafka
[root@elk91 ~]# kafka-server-stop.sh
[root@elk92 ~]# kafka-server-stop.sh
[root@elk93 ~]# kafka-server-stop.sh
启动kafka
[root@elk91 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@elk92 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@elk93 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
4.验证是否成功
[root@elk91 ~]# ps -ef | grep kafka | grep Xms
root 51593 1 4 14:43 pts/0 00:00:05 /usr/share/elasticsearch/jdk/bin/java -Xmx256m -Xms256m ...
十、kafka集群的压测及官方文档阅读技巧
1.kafka压测的作用?
1. 评估性能瓶颈
通过压力测试,可以模拟高并发、大数据量的场景,帮助识别 Kafka 集群在生产者和消费者方面的性能瓶颈,例如 CPU、内存或网络 I/O 的瓶颈。
2. 优化资源配置
压测可以帮助确定 Kafka 集群在不同负载下的性能表现,从而合理配置资源(如 Broker 数量、磁盘 I/O、网络带宽等),以满足业务需求。
3. 验证集群扩展性
通过模拟高负载场景,可以验证 Kafka 集群的水平扩展能力,确保在业务增长时能够通过增加 Broker 节点来提升性能。
4. 评估消息处理能力
压测可以评估 Kafka 集群在不同消息大小和吞吐量下的处理能力,确保其能够满足生产环境中的消息处理需求。
5. 测试容错能力
通过模拟故障场景(如 Broker 节点故障),可以验证 Kafka 集群的容错机制是否有效,确保数据的可靠性和系统的高可用性。
6. 优化配置参数
压测可以帮助优化 Kafka 的配置参数,例如消息大小、副本数量、确认模式(acks)等,以提升集群的整体性能。
7. 提前发现潜在问题
在正式上线前,通过压测可以提前发现潜在的性能问题,避免在生产环境中出现性能瓶颈或故障。
2.可参考的链接
https://www.cnblogs.com/yinzhengjie/p/9953212.html
https://kafka.apache.org/documentation/#tiered_storage_config_ex
#新版本测试需要参考官网:
比如:
kafka-producer-perf-test.sh --topic tieredTopic --num-records 1200 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=localhost:9092
十一、kafka的图形化管理工具EFAK
1.启动MySQL数据库,创建必要信息
[root@elk93 ~]# cat /etc/my.cnf
[mysqld]
basedir=/usr/local/mysql844
datadir=/var/lib/mysql
socket=/tmp/mysql80.sock
port=3306
mysql_native_password=on #启用此配置
[client]
socket=/tmp/mysql80.sock
[root@elk93 ~]# /etc/init.d/mysql.server start
[root@elk93 ~]# mysql
#创建所需的数据库
mysql> CREATE DATABASE dezyan_kafka;
#创建所需的执行用户
mysql> CREATE USER IF NOT EXISTS linux96 IDENTIFIED WITH mysql_native_password BY 'dezyan';
#授权
mysql> GRANT ALL ON dezyan_kafka.* TO 'linux96';
2.下载EFAK并解压
[root@elk92 ~]# wget https://github.com/smartloli/kafka-eagle-bin/blob/master/efak-web-3.0.2-bin.tar.gz
[root@elk92 ~]# tar xf efak-web-3.0.2-bin.tar.gz -C /usr/local/
3.修改配置文件
[root@elk92 ~]# egrep -v "^#|^$" /usr/local/efak-web-3.0.2/conf/system-config.properties
efak.zk.cluster.alias=dezyan-linux96
dezyan-linux96.zk.list=10.0.0.91:2181,10.0.0.92:2181,10.0.0.93:2181/dezyan-kafka-3.9.0
dezyan-linux96.zk.acl.enable=false
dezyan-linux96.efak.broker.size=20
kafka.zk.limit.size=16
efak.webui.port=8048
efak.distributed.enable=false
dezyan-linux96.efak.jmx.acl=false
dezyan-linux96.efak.offset.storage=kafka
dezyan-linux96.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
efak.metrics.charts=true
efak.metrics.retain=15
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
efak.topic.token=dezyan
dezyan-linux96.efak.sasl.enable=false
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://10.0.0.93:3306/dezyan_kafka?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=linux96
efak.password=dezyan
4.修改启动的脚本
- 目的是修改堆内存参数,减少内存占用
[root@elk92 ~]# vim /usr/local/efak-web-3.0.2/bin/ke.sh
...
export KE_JAVA_OPTS="-server -Xmx256m -Xms256m -XX:MaxGCPauseMillis=20 -XX:+UseG1GC -XX:MetaspaceSize=128m -XX:InitiatingH eapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80"
5.添加环境变量
[root@elk92 ~]# cat /etc/profile.d/kafka.sh
#!/bin/bash
export KE_HOME=/usr/local/efak-web-3.0.2
export KAFKA_HOME=/usr/local/kafka_2.13-3.9.0
export PATH=$PATH:$KAFKA_HOME/bin:$KE_HOME/bin
[root@elk92 ~]#
[root@elk92 ~]# source /etc/profile.d/kafka.sh
6.启动efak程序
[root@elk92 ~]# /usr/local/efak-web-3.0.2/bin/ke.sh start
...
Welcome to
______ ______ ___ __ __
/ ____/ / ____/ / | / //_/
/ __/ / /_ / /| | / ,<
/ /___ / __/ / ___ | / /| |
/_____/ /_/ /_/ |_|/_/ |_|
( Eagle For Apache Kafka® )
Version v3.0.2 -- Copyright 2016-2022
*******************************************************************
* EFAK Service has started success.
* Welcome, Now you can visit 'http://10.0.0.92:8048'
* Account:admin ,Password:123456
...
[root@elk92 ~]# ss -ntl | grep 8048
LISTEN 0 500 *:8048 *:*
7.访问测试
http://10.0.0.92:8048
十二、kafka的ISR存在丢失数据的风险
1.专业术语
ISR:
和leader副本数据相同的所有副本集合。
OSR:
和leader副本数据不相同的副本集合。
AR:
all replica,表示所有的副本集合,包括leader和follower。
AR = ISR + OSR 。
LEO:
表示某个paritition的最后一个offset。。
HW: High water
表示ISR列表中最小的LEO。
对于消费者而言,只能消费HW之前的offset
2.会丢失数据的原因
首先,对于消费者而言,只能消费HW之前的数据。
要注意的是:在kafka的配置中,有一个replica.lag.time.max.ms参数,默认是30s。其作用是定义 Follower 副本在被认为与 Leader 不同步之前,可以落后的最大时间间隔(以毫秒为单位)。若follower副本长时间没有向leader节点拉取数据,或其日志LEO长期落后于leader,则该副本会被认为是不同步的,并可能被移出 ISR
其次,若leader突然宕机,follower未完全同步leader信息,这样,其中一个follower就会接替leader职责成为新的leader,而原leader中未同步的数据,就会被彻底丢弃,消费者也就读取不到新leader中未同步的信息,从而造成数据丢失。
十三、ELFK架构之Filebeat写入kafka集群
1.编写启动Filebeat实例
[root@elk91 filebeat]# cat 18-tcp-to-kafka.yaml
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
# 数据输出到kafka
output.kafka:
# 指定kafka集群的地址
hosts:
- 10.0.0.91:9092
- 10.0.0.92:9092
- 10.0.0.93:9092
# 指定topic
topic: dezyan-linux96-kafka
[root@elk91 filebeat]#
[root@elk91 filebeat]#
[root@elk91 filebeat]# filebeat -e -c `pwd`/18-tcp-to-kafka.yaml
2.发送测试数据
[root@elk92 ~]# echo www.dezyan.com | nc 10.0.0.91 9000
3.验证数据是否写入kafka集群
[root@elk93 ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.91:9092 --topic dezyan-linux96-kafka --from-beginning
{"@timestamp":"2025-03-17T09:09:26.372Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.17.28"},"ecs":{"version":"1.12.0"},"message":"www.dezyan.com","log":{"source":{"address":"10.0.0.92:35652"}},"input":{"type":"tcp"},"host":{"name":"elk91"},"agent":{"type":"filebeat","version":"7.17.28","hostname":"elk91","ephemeral_id":"5a1ed508-b8cc-41b1-a6a4-375d08dd0a17","id":"0102bacf-8cb1-44d7-8bab-b14429ee1b4b","name":"elk91"}}
十四、ELFK架构之Logstash消费kafka集群
1.kibana基于开发工具创建账号
#要注意的是,POST请求中"names":后应该为你Logstash所写入的索引名,支持通配符,若是此处设置失误,会导致在Kibana无法查看索引
POST /_security/api_key
{
"name": "yinzhengjie",
"role_descriptors": {
"filebeat_monitoring": {
"cluster": ["all"],
"index": [
{
"names": ["dezyan-logstash-kafka*"],
"privileges": ["all"]
}
]
}
}
}
响应数据类似如下:
{
"id" : "kR4opJUByfkuRe-VCpKn",
"name" : "yinzhengjie",
"api_key" : "iQkLEBazSh6CUCIjuLpLmA",
"encoded" : "a1I0b3BKVUJ5Zmt1UmUtVkNwS246aVFrTEVCYXpTaDZDVUNJanVMcExtQQ=="
}
root@elk92:~# echo a3g1ZHBKVUJ5Zmt1UmUtVkZwSTA6aEhYaUxEMWhUV3VRcUxCWVh2Q3Rjdw==|base64 -d ;echo
kx5dpJUByfkuRe-VFpI0:hHXiLD1hTWuQqLBYXvCtcw
2.解码数据
[root@elk93 ~]# /etc/logstash/conf.d# echo a1I0b3BKVUJ5Zmt1UmUtVkNwS246aVFrTEVCYXpTaDZDVUNJanVMcExtQQ== | base64 -d ;echo
kR4opJUByfkuRe-VCpKn:iQkLEBazSh6CUCIjuLpLmA
3.Logstash消费数据
[root@elk93 ~]# vim /etc/logstash/conf.d/14-kafka-to-es_api-key.conf
input {
kafka {
# 指定kafka集群的地址
bootstrap_servers => "10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092"
# 指定从kafka哪个topic拉取数据
topics => ["dezyan-linux96-kafka"]
# 指定消费者组
group_id => "linux96-008"
# 指定拉取数据offset的位置点,常用值:earliest(从头拉取数据),latest(从最新的位置拉取数据)
auto_offset_reset => "earliest"
}
}
filter {
json {
source => "message"
}
mutate {
remove_field => [ "agent","@version","ecs","input","log" ]
}
}
output {
# stdout {
# codec => rubydebug
# }
elasticsearch {
hosts => ["10.0.0.91:9200","10.0.0.92:9200","10.0.0.93:9200"]
index => "dezyan-logstash-kafka"
api_key => "kR4opJUByfkuRe-VCpKn:iQkLEBazSh6CUCIjuLpLmA"
ssl => true
ssl_certificate_verification => false
}
}
4.启动Logstash
[root@elk93 ~]# logstash -rf /etc/logstash/conf.d/14-kafka-to-es_api-key.conf
5.Kibana中查看数据
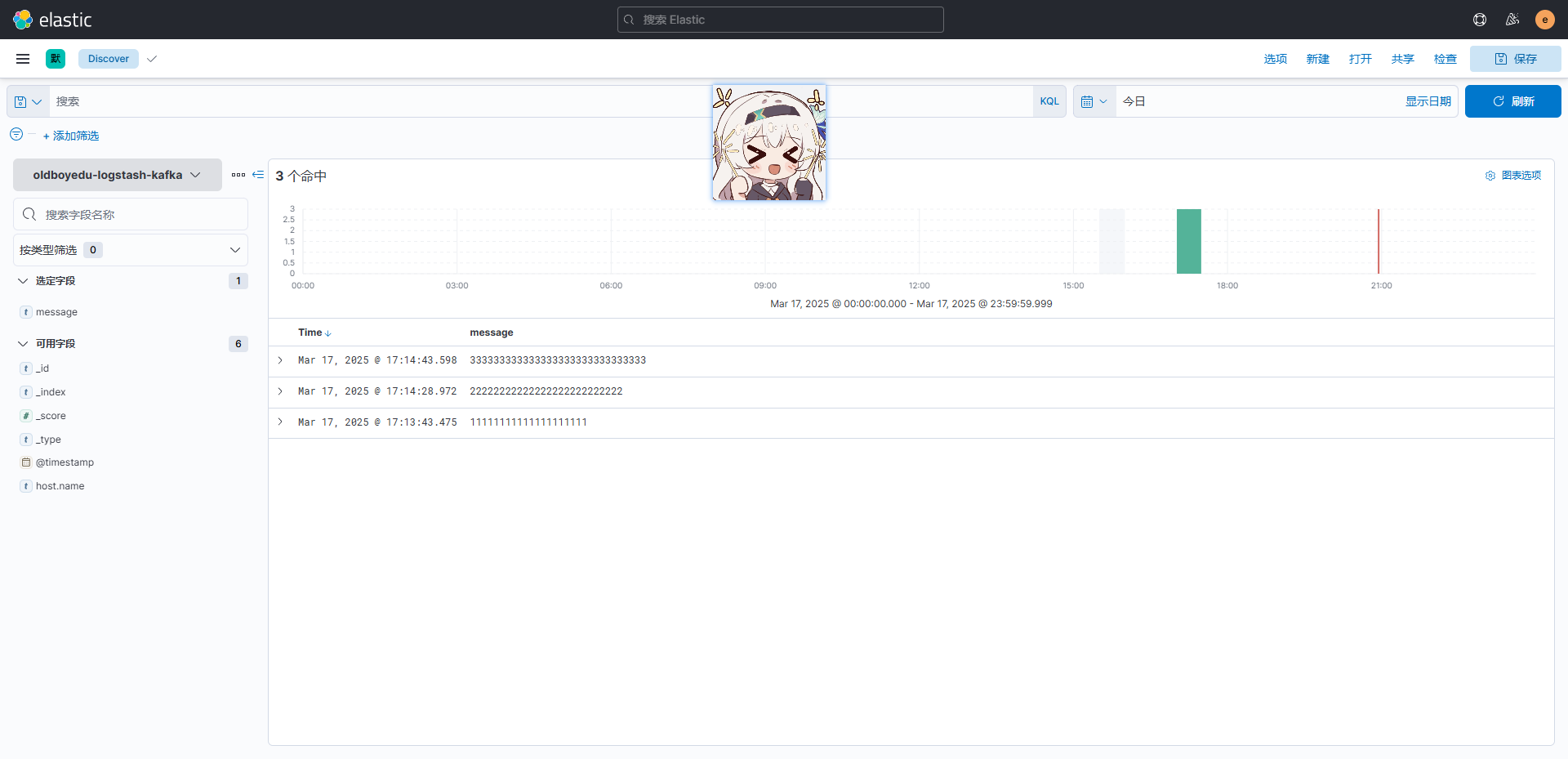
十五、总结
1.kafka集群部署的注意点
1.修改kafka的唯一标识:broker.id
2.修改数据目录:log.dirs
3.指定kafka的元数据存储在zookeeper集群的路径(znodes)
zookeeper.connect=10.0.0.91:2181,10.0.0.92:2181,10.0.0.93:2181/dezyan-kafka-3.9.0
4.设置listeners默认监听端口
2.kafka的JVM调优
建议设置6GB,学习环境设置256MB即可
3.kafka常用的术语
略
4.kafka常用脚本
①脚本通用参数
--bootstrap-server #指定kafka的brocker地址
--topic #主题名
②kafka-topics.sh(kafka的主题操作)
#查看现有的topic列表
--list
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --list
#创建新的topic并指定分区数和副本数
--create 创建新的topic
--partitions n 指定分区数
--replication-factor n 指定副本数
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --create --partitions 3 --replication-factor 2 --topic dezyan-linux96
#查看分区的详细信息
--describe 查看详细信息
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --topic dezyan-linux96 --describe
#修改分区数,只能改大
--alter 执行修改
--partitions 分区数
kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --topic dezyan-linux96 --alter --partitions 5
#删除topic
--delete 删除topic
[root@elk91 ~]# kafka-topics.sh --bootstrap-server 10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092 --topic dezyan-linux96 --delete
③kafka-console-producer.sh(生产者程序)
#创建生产者程序,topic若不存在,则会默认创建
[root@elk91 ~]# kafka-console-producer.sh --bootstrap-server 10.0.0.93:9092 --topic linux96
④kafka-console-consumer.sh(消费者程序)
#创建消费者程序
# 默认从最新的offset获取数据
[root@elk92 ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.91:9092 --topic linux96
#从最老的offset获取数据
--from-beginning
[root@elk93 ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.92:9092 --topic linux96 --from-beginning
#创建消费者程序,并将其加入制定组
--consumer-property group.id=xixi
[root@elk92 ~]# kafka-console-consumer.sh --bootstrap-server 10.0.0.91:9092 --topic dezyan-linux96 --consumer-property group.id=xixi --from-beginning
⑤kafka-consumer-groups.sh(消费者组)
#查看现有的消费者组
[root@elk91 ~]# kafka-consumer-groups.sh --bootstrap-server 10.0.0.92:9092 --list
#查看指定的消费者组信息
[root@elk91 ~]# kafka-consumer-groups.sh --bootstrap-server 10.0.0.92:9092 --group xixi --describe ;echo
十六、使用ELFK架构对接kafka集群并实现nginx和tomcat的数据分析并制作Dashboard
1.kibana基于开发工具创建账号
POST /_security/api_key
{
"name": "dingzhiyan",
"role_descriptors": {
"filebeat_monitoring": {
"cluster": ["all"],
"index": [
{
"names": ["dezyan-logstash-nginx-kafka*"],
"privileges": ["all"]
}
]
}
}
}
{
"id" : "kx5dpJUByfkuRe-VFpI0",
"name" : "dingzhiyan",
"api_key" : "hHXiLD1hTWuQqLBYXvCtcw",
"encoded" : "a3g1ZHBKVUJ5Zmt1UmUtVkZwSTA6aEhYaUxEMWhUV3VRcUxCWVh2Q3Rjdw=="
}
root@elk92:~# echo a3g1ZHBKVUJ5Zmt1UmUtVkZwSTA6aEhYaUxEMWhUV3VRcUxCWVh2Q3Rjdw==|base64 -d ;echo
kx5dpJUByfkuRe-VFpI0:hHXiLD1hTWuQqLBYXvCtcw
POST /_security/api_key
{
"name": "dingzhiyan",
"role_descriptors": {
"filebeat_monitoring": {
"cluster": ["all"],
"index": [
{
"names": ["dezyan-logstash-tomcat-kafka*"],
"privileges": ["all"]
}
]
}
}
}
{
"id" : "lB5opJUByfkuRe-VG5KE",
"name" : "dingzhiyan",
"api_key" : "MxnHDIpwSpOu9uDqXgTQWQ",
"encoded" : "bEI1b3BKVUJ5Zmt1UmUtVkc1S0U6TXhuSERJcHdTcE91OXVEcVhnVFFXUQ=="
}
root@elk92:~# echo bEI1b3BKVUJ5Zmt1UmUtVkc1S0U6TXhuSERJcHdTcE91OXVEcVhnVFFXUQ==|base64 -d ;echo
lB5opJUByfkuRe-VG5KE:MxnHDIpwSpOu9uDqXgTQWQ
2.编写Filebeat文件
root@elk92:~# vim /etc/filebeat/config/19-nignx-to-kafka.yml
filebeat.config.modules:
path: ${path.config}/modules.d/nginx.yml
reload.enabled: true
# 数据输出到kafka
output.kafka:
# 指定kafka集群的地址
hosts:
- 10.0.0.91:9092
- 10.0.0.92:9092
- 10.0.0.93:9092
# 指定topic
topic: dezyan-linux96-nginx-kafka
root@elk92:~# vim /etc/filebeat/config/20-tomecat-to-kafka.yml
filebeat.config.modules:
path: ${path.config}/modules.d/tomcat.yml
reload.enabled: true
# 数据输出到kafka
output.kafka:
# 指定kafka集群的地址
hosts:
- 10.0.0.91:9092
- 10.0.0.92:9092
- 10.0.0.93:9092
# 指定topic
topic: dezyan-linux96-tomcat-kafka
3.编写Logstash文件
[root@elk93 ~]# vim /etc/logstash/conf.d/15-nginx-kafka-to-es_api-key.conf
input {
kafka {
bootstrap_servers => "10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092"
topics => ["dezyan-linux96-nginx-kafka"]
group_id => "nginx-001"
auto_offset_reset => "earliest"
}
}
filter {
grok {
match => { "message" => "%{HTTPD_COMMONLOG}" }
}
useragent {
source => "message"
target => "linux95_user_agent"
}
geoip {
source => "clientip"
database => "/usr/share/logstash/data/plugins/filters/geoip/CC/GeoLite2-City.mmdb"
}
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
target => "dezyan-timestamp"
}
mutate {
remove_field => [ "@version","host","path" ]
}
}
output {
# stdout {
# codec => rubydebug
# }
elasticsearch {
hosts => ["10.0.0.91:9200","10.0.0.92:9200","10.0.0.93:9200"]
index => "dezyan-logstash-nginx-kafka"
api_key => "kx5dpJUByfkuRe-VFpI0:hHXiLD1hTWuQqLBYXvCtcw"
ssl => true
ssl_certificate_verification => false
}
}
[root@elk93 ~]# vim /etc/logstash/conf.d/16-t-kafka-to-es_api-key.conf
input {
kafka {
# 指定kafka集群的地址
bootstrap_servers => "10.0.0.91:9092,10.0.0.92:9092,10.0.0.93:9092"
# 指定从kafka哪个topic拉取数据
topics => ["dezyan-linux96-tomcat-kafka"]
# 指定消费者组
group_id => "tomcat-001"
# 指定拉取数据offset的位置点,常用值:earliest(从头拉取数据),latest(从最新的位置拉取数据)
auto_offset_reset => "earliest"
}
}
output {
# stdout {
# codec => rubydebug
# }
elasticsearch {
hosts => ["10.0.0.91:9200","10.0.0.92:9200","10.0.0.93:9200"]
index => "dezyan-logstash-tomcat-kafka"
api_key => "lB5opJUByfkuRe-VG5KE:MxnHDIpwSpOu9uDqXgTQWQ"
ssl => true
ssl_certificate_verification => false
}
}
4.
本文来自博客园,作者:丁志岩,转载请注明原文链接:https://www.cnblogs.com/dezyan/p/18811475

 浙公网安备 33010602011771号
浙公网安备 33010602011771号