2025,每天10分钟,跟我学K8S(四十四)- Prometheus(二)安装Kube-Prometheus
在上一章内容,我们了解了Prometheus 的基础知识点,这一章开始,开始正式学习Prometheus 的安装搭建。
考虑到并不是所有环境都有安装helm,所以安装的版本就选择kube-prometheus。
Kube-Prometheus 是基于 Operator 的标准化监控堆栈,适合快速部署。
Kube-Prometheus版本的选择
从github上得知,目前kube-prometheus最新版为0.14,并且只支持到K8S1.31
| kube-prometheus stack | Kubernetes 1.23 | Kubernetes 1.24 | Kubernetes 1.25 | Kubernetes 1.26 | Kubernetes 1.27 | Kubernetes 1.28 | Kubernetes 1.29 | Kubernetes 1.30 | Kubernetes 1.31 |
|---|---|---|---|---|---|---|---|---|---|
| release-0.11 | ✔ | ✔ | ✗ | x | x | x | x | x | x |
| release-0.12 | ✗ | ✔ | ✔ | x | x | x | x | x | x |
| release-0.13 | ✗ | ✗ | x | ✔ | ✔ | ✔ | x | x | x |
| release-0.14 | ✗ | ✗ | x | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| main | ✗ | ✗ | x | x | ✔ | ✔ | ✔ | ✔ | ✔ |
Kube-Prometheus安装教程
1.下载软件
root@k8s-master:~# mkdir -vp prometheus
root@k8s-master:~# cd prometheus
root@k8s-master:~/prometheus# wget https://github.com/prometheus-operator/kube-prometheus/archive/refs/tags/v0.14.0.zip
root@k8s-master:~/prometheus# unzip v0.14.0.zip
root@k8s-master:~/prometheus# cd kube-prometheus-0.14.0/
root@k8s-master:~/prometheus/kube-prometheus-0.14.0# tree
.
├── build.sh
├── CHANGELOG.md
├── code-of-conduct.md
├── CONTRIBUTING.md
.....
2.镜像替换
manifests/blackboxExporter-deployment.yaml: image: quay.io/prometheus/blackbox-exporter:v0.25.0
manifests/blackboxExporter-deployment.yaml: image: ghcr.io/jimmidyson/configmap-reload:v0.13.1
manifests/blackboxExporter-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1
manifests/nodeExporter-daemonset.yaml: image: quay.io/prometheus/node-exporter:v1.8.2
manifests/nodeExporter-daemonset.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1
manifests/alertmanager-alertmanager.yaml: image: quay.io/prometheus/alertmanager:v0.27.0
manifests/prometheusOperator-deployment.yaml: image: quay.io/prometheus-operator/prometheus-operator:v0.76.2
manifests/prometheusOperator-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1
manifests/kubeStateMetrics-deployment.yaml: image: registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.13.0
manifests/kubeStateMetrics-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1
manifests/kubeStateMetrics-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.18.1
manifests/prometheus-prometheus.yaml: image: quay.io/prometheus/prometheus:v2.54.1
manifests/grafana-deployment.yaml: image: grafana/grafana:11.2.0
manifests/prometheusAdapter-deployment.yaml: image: registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.12.0
====修改为====
manifests/blackboxExporter-deployment.yaml: image: quay.m.daocloud.io/prometheus/blackbox-exporter:v0.25.0
manifests/blackboxExporter-deployment.yaml: image: ghcr.m.daocloud.io/jimmidyson/configmap-reload:v0.13.1
manifests/blackboxExporter-deployment.yaml: image: quay.m.daocloud.io/brancz/kube-rbac-proxy:v0.18.1
manifests/nodeExporter-daemonset.yaml: image: quay.m.daocloud.io/prometheus/node-exporter:v1.8.2
manifests/nodeExporter-daemonset.yaml: image: quay.m.daocloud.io/brancz/kube-rbac-proxy:v0.18.1
manifests/alertmanager-alertmanager.yaml: image: quay.m.daocloud.io/prometheus/alertmanager:v0.27.0
manifests/prometheusOperator-deployment.yaml: image: quay.m.daocloud.io/prometheus-operator/prometheus-operator:v0.76.2
manifests/prometheusOperator-deployment.yaml: image: quay.m.daocloud.io/brancz/kube-rbac-proxy:v0.18.1
manifests/kubeStateMetrics-deployment.yaml: image: k8s.m.daocloud.io/kube-state-metrics/kube-state-metrics:v2.13.0
manifests/kubeStateMetrics-deployment.yaml: image: quay.m.daocloud.io/brancz/kube-rbac-proxy:v0.18.1
manifests/kubeStateMetrics-deployment.yaml: image: quay.m.daocloud.io/brancz/kube-rbac-proxy:v0.18.1
manifests/prometheus-prometheus.yaml: image: quay.m.daocloud.io/prometheus/prometheus:v2.54.1
manifests/grafana-deployment.yaml: image: m.daocloud.io/docker.io/grafana/grafana:11.2.0
manifests/prometheusAdapter-deployment.yaml: image: k8s.m.daocloud.io/prometheus-adapter/prometheus-adapter:v0.12.03 Prometheus持久化准备
由于默认情况下prometheus的数据是存储在pod里面,当pod重启后,数据就丢失了,这不利于我们分析长期数据,所以需要将数据存储到之前搭建的longhorn中。
3.1 编辑manifests/prometheus-prometheus.yaml
新增如下内容:
vim manifests/prometheus-prometheus.yaml
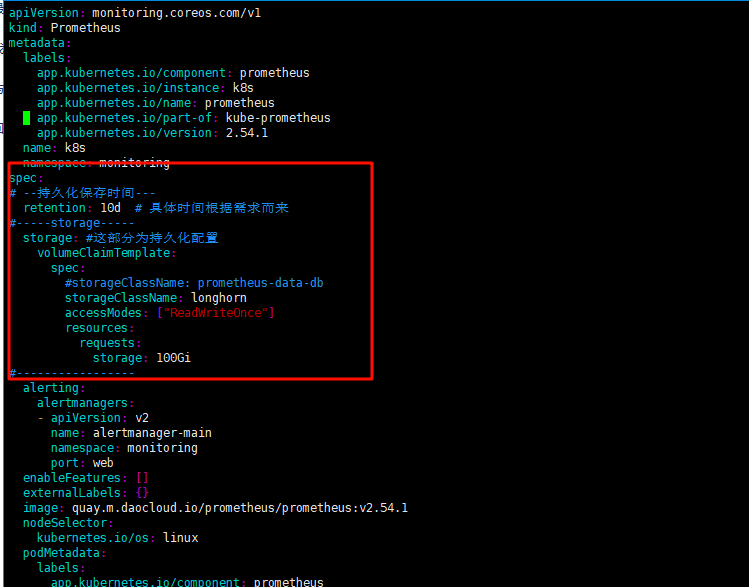
# --持久化保存时间---
retention: 3d # 具体时间根据需求而来,默认1天
#-----storage-----
storage: #这部分为持久化配置
volumeClaimTemplate:
spec:
#storageClassName: prometheus-data-db
storageClassName: longhorn
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi # 存储硬盘大小按照需求来,存储时间场,就调整大点
#-----------------
红色方框内为新增内容
3.2 grafana持久化准备
如果Grafana不做数据持久化、那么服务重启以后,Grafana里面配置的Dashboard、账号密码等信息将会丢失;所以Grafana做数据持久化也是很有必要的。原始的数据是以 emptyDir 形式存放在pod里面,生命周期与pod相同;出现问题时,容器重启,在Grafana里面设置的数据就全部消失了。
a.创建manifests/grafana-pvc.yaml
manifests/grafana-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc
namespace: monitoring
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
storageClassName: longhorn
b.修改deployment.yaml文件
vim manifests/grafana-deployment.yaml
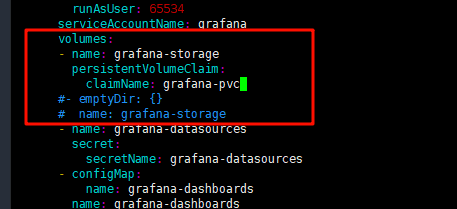
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc
#- emptyDir: {}
# name: grafana-storage修改如下
3.3 暴露prometheus和grafana的端口
grafana 和 prometheus 默认都创建了一个类型为 ClusterIP 的 Service,我们需要暴露端口,以便外部访问,有多种方式选择:
- ingress方式
- NodePort .
此处我们通过NodePort方式实现
3.3.1 修改prometheus 的service文件
vim manifests/prometheus-service.yaml
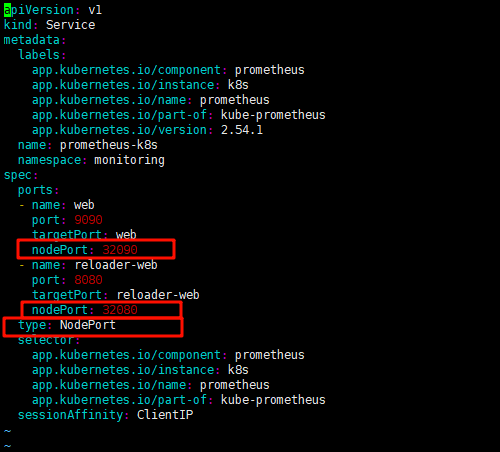
type: NodePort
ports:
- name: web
port: 9090
targetPort: web
nodePort: 32090
- name: reloader-web
port: 8080
targetPort: reloader-web
nodePort: 32080修改如下:
3.3.2 修改grafana的service文件
vim manifests/grafana-service.yaml
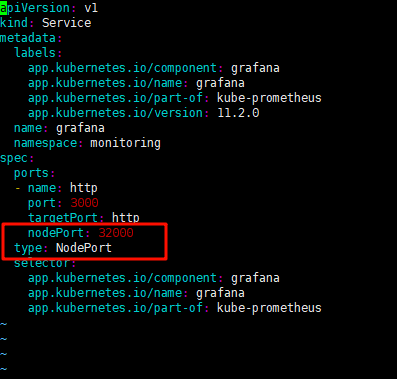
type: NodePort
ports:
- name: http
port: 3000
targetPort: http
nodePort: 32000
type: NodePort修改如下:
4. 安装部署
这里我们直接依次执行下面的命令即可完成安装:
# kubectl create -f manifests/setup
# kubectl create -f manifests5. 检查
部署完成后,会创建一个名为monitoring的 namespace,所以资源对象对将部署在改命名空间下面,此外 Operator 会自动创建6个 CRD 资源对象
# kubectl get ns monitoring # kubectl get crd我们可以在 monitoring 命名空间下面查看所有的 Pod和SVC资源,其中 alertmanager 和 prometheus 是用 StatefulSet 控制器管理的,其中还有一个比较核心的 prometheus-operator 的 Pod,用来控制其他资源对象和监听对象变化的。
kubectl get pod -n monitoring -o wide
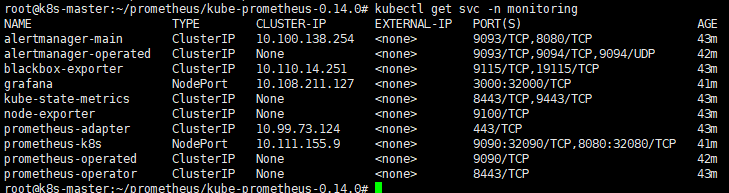
kubectl get svc -n monitoring -o wide查看pod:
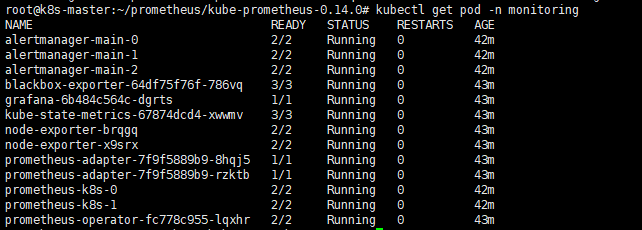
查看svc:
虽然pod和svc已经全部启动成功,但现在还无法访问grafan、prometheus以及alertmanger,因为prometheus operator内部默认配置了NetworkPolicy,需要删除其对应的资源,才可以通过外网访问:
kubectl delete -f manifests/prometheus-networkPolicy.yaml
kubectl delete -f manifests/grafana-networkPolicy.yaml
kubectl delete -f manifests/alertmanager-networkPolicy.yaml页面检查
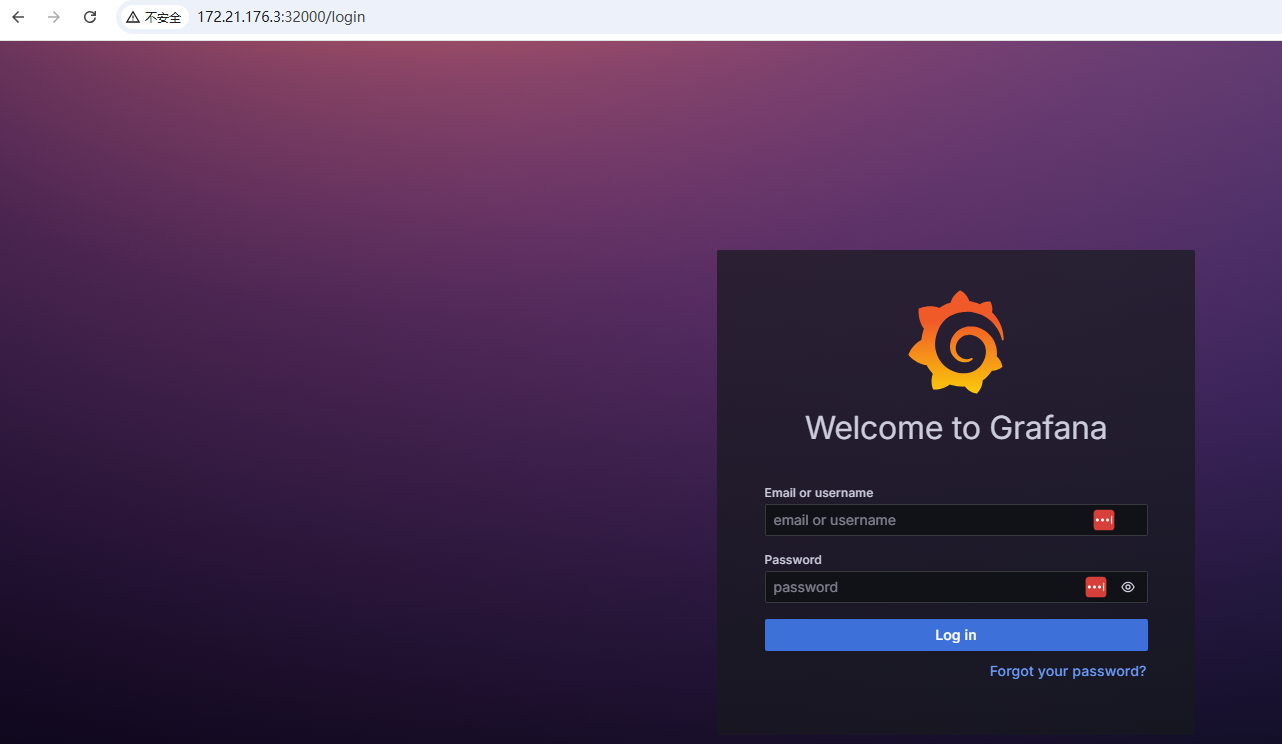
grafana界面:
默认密码 admin/admin,输入密码后会提示让用户重新设置一个管理员密码。重复输入2次即可。
但是需要注意的是,由于此时是通过nodeport的形式对外,所以任何人都可以访问这个地址,请设置相关的安全策略保证数据的安全,也包括其他的web页面。
Prometheus界面:
6.其他补充
默认grafana的时区不是北京时间,所以也需要调整后重新apply
修正grafana组件自带dashboard的默认时区
grep -i timezone manifests/grafana-dashboardDefinitions.yaml
sed -i 's/UTC/UTC+8/g' manifests/grafana-dashboardDefinitions.yaml
sed -i 's/utc/utc+8/g' manifests/grafana-dashboardDefinitions.yaml
kubectl apply -f manifests/grafana-dashboardDefinitions.yaml

 浙公网安备 33010602011771号
浙公网安备 33010602011771号