2025,每天10分钟,跟我学K8S(四十六)- Prometheus(三)添加自定义监控项
上一章,我们学习了Prometheus添加系统监控项,那如何添加自定义监控项呢?例如etcd或者其他自己运行的pod?
这一章节就来讲解这个问题。
Prometheus监控ETCD
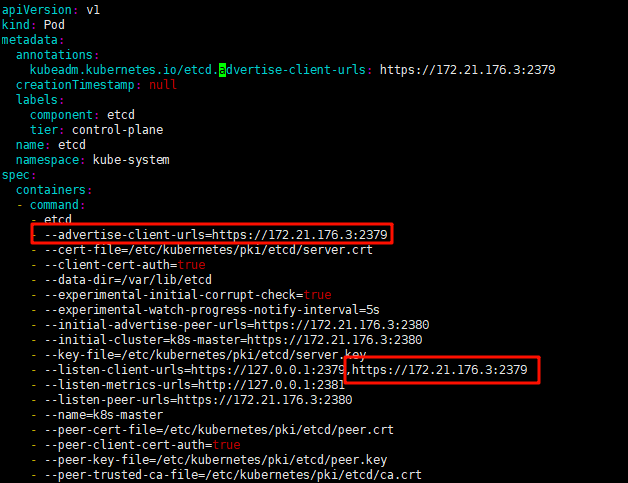
1.编辑监听端口
这里由于是kubeadm创建的,所以默认监听了本地内网IP,这里不做修改
2.创建Service 和 Endpoints
# vim manifests/etcd-Service.yaml
# Service 定义
apiVersion: v1
kind: Service
metadata:
name: etcd
namespace: kube-system
labels:
k8s-app: etcd
spec:
clusterIP: None # Headless Service
ports:
- name: https-metrics
port: 2379
protocol: TCP # 协议类型需与 Endpoints 一致
---
# Endpoints 定义
apiVersion: v1
kind: Endpoints
metadata:
name: etcd
namespace: kube-system
subsets: # 直接定义 subsets,无需嵌套在 spec 下
- addresses:
- ip: 172.21.176.3 # 替换为实际 ETCD 节点 IP 有几台就写几个
ports:
- name: https-metrics # 端口名称需与 Service 一致
port: 2379
protocol: TCP # 必须明确协议类型
3.创建ServiceMonitor
etcd默认是有证书的,所以需要提前将etcd的证书创建成secret,并且挂载到prometheus的pod中去。
3.1 证书挂载
创建包含 ETCD 证书的 Secret,供 Prometheus 使用
kubectl -n monitoring create secret generic etcd-certs \
--from-file=/etc/kubernetes/pki/etcd/ca.crt \
--from-file=/etc/kubernetes/pki/etcd/server.crt \
--from-file=/etc/kubernetes/pki/etcd/server.key更新 Prometheus 新增配置以挂载证书:
# 修改 manifests/prometheus-prometheus.yaml
spec:
secrets:
- etcd-certs
# 应用
root@k8s-master:~/prometheus/kube-prometheus-0.14.0# kubectl apply -f /opt/prometheus/kube-prometheus/manifests/prometheus-prometheus.yaml
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
prometheus.monitoring.coreos.com/k8s configured
更新完毕后,我们就可以在Prometheus Pod中查看到对象的目录,这一步需要的时间比较长,需要等待一会才会复制进去
root@k8s-master:~/prometheus/kube-prometheus-0.14.0# kubectl exec -it -n monitoring prometheus-k8s-0 -- /bin/sh
/prometheus $
/prometheus $ ls /etc/prometheus/secrets/etcd-certs/
ca.crt server.crt server.key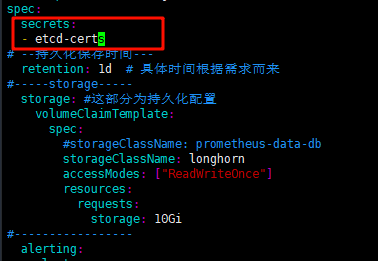
3.2 ServiceMonitor 配置
定义 HTTPS 抓取规则,引用证书路径
# vim manifests/etcd-ServiceMonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd
namespace: monitoring
spec:
endpoints:
- interval: 30s
port: https-metrics
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-certs/ca.crt
certFile: /etc/prometheus/secrets/etcd-certs/server.crt
keyFile: /etc/prometheus/secrets/etcd-certs/server.key
selector:
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames: [kube-system]4.应用yaml文件
kubectl apply -f manifests/etcd-Service.yaml
service/etcd created
kubectl apply -f manifests/etcd-ServiceMonitor.yaml
servicemonitor.monitoring.coreos.com/etcd created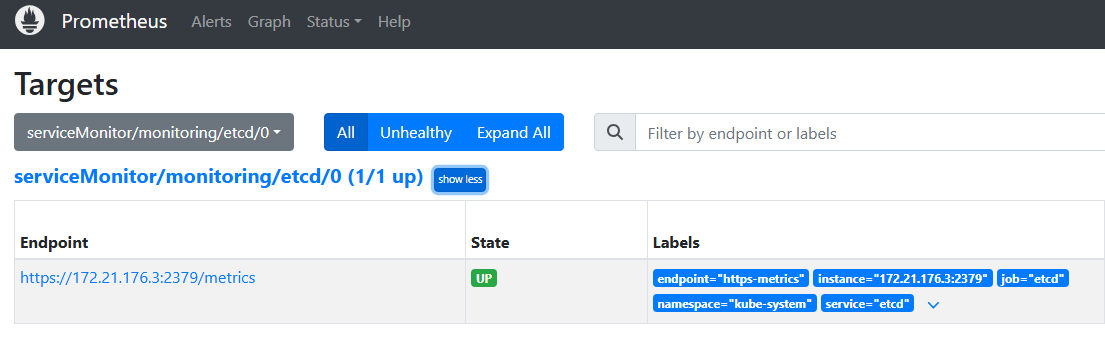
5.配置报警规则
上面etcd的监控项已经出现了,但是只监控,不设置预警显然是不合理的。
创建 manifests/etcd-serviceMonitorRule.yaml 预警规则
这里参考:https://github.com/samber/awesome-prometheus-alerts, 这里有各种应用的监控报警规则。
# vim manifests/etcd-serviceMonitorRule.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: prometheus-k8s-etcd-rules
namespace: monitoring
spec:
groups:
- name: etcd
rules:
- alert: EtcdInsufficientMembers
expr: count(etcd_server_id) % 2 == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Etcd insufficient Members (instance {{ $labels.instance }})"
description: "Etcd cluster should have an odd number of members\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: EtcdNoLeader
expr: etcd_server_has_leader == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Etcd no Leader (instance {{ $labels.instance }})"
description: "Etcd cluster have no leader\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: EtcdHighNumberOfLeaderChanges
expr: increase(etcd_server_leader_changes_seen_total[1h]) > 3
for: 5m
labels:
severity: warning
annotations:
summary: "Etcd high number of leader changes (instance {{ $labels.instance }})"
description: "Etcd leader changed more than 3 times during last hour\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: EtcdHighNumberOfFailedGrpcRequests
expr: sum(rate(grpc_server_handled_total{grpc_code!="OK",grpc_method !="Watch"}[5m])) BY (grpc_service, grpc_method) / sum(rate(grpc_server_handled_total[5m])) BY (grpc_service, grpc_method) > 0.01
for: 5m
labels:
severity: warning
annotations:
summary: "Etcd high number of failed GRPC requests (instance {{ $labels.instance }})"
description: "More than 1% GRPC request failure detected in Etcd for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: EtcdHighNumberOfFailedGrpcRequests
expr: sum(rate(grpc_server_handled_total{grpc_code!="OK",grpc_method !="Watch"}[5m])) BY (grpc_service, grpc_method) / sum(rate(grpc_server_handled_total[5m])) BY (grpc_service, grpc_method) > 0.05
for: 5m
labels:
severity: critical
annotations:
summary: "Etcd high number of failed GRPC requests (instance {{ $labels.instance }})"
description: "More than 5% GRPC request failure detected in Etcd for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: EtcdGrpcRequestsSlow
expr: histogram_quantile(0.99, sum(rate(grpc_server_handling_seconds_bucket{grpc_type="unary"}[5m])) by (grpc_service, grpc_method, le)) > 0.15
for: 5m
labels:
severity: warning
annotations:
summary: "Etcd GRPC requests slow (instance {{ $labels.instance }})"
description: "GRPC requests slowing down, 99th percentil is over 0.15s for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: EtcdHighNumberOfFailedHttpRequests
expr: sum(rate(etcd_http_failed_total[5m])) BY (method) / sum(rate(etcd_http_received_total[5m])) BY (method) > 0.01
for: 5m
labels:
severity: warning
annotations:
summary: "Etcd high number of failed HTTP requests (instance {{ $labels.instance }})"
description: "More than 1% HTTP failure detected in Etcd for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: EtcdHighNumberOfFailedHttpRequests
expr: sum(rate(etcd_http_failed_total[5m])) BY (method) / sum(rate(etcd_http_received_total[5m])) BY (method) > 0.05
for: 5m
labels:
severity: critical
annotations:
summary: "Etcd high number of failed HTTP requests (instance {{ $labels.instance }})"
description: "More than 5% HTTP failure detected in Etcd for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: EtcdHttpRequestsSlow
expr: histogram_quantile(0.99, rate(etcd_http_successful_duration_seconds_bucket[5m])) > 0.15
for: 5m
labels:
severity: warning
annotations:
summary: "Etcd HTTP requests slow (instance {{ $labels.instance }})"
description: "HTTP requests slowing down, 99th percentil is over 0.15s for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: EtcdMemberCommunicationSlow
expr: histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.15
for: 5m
labels:
severity: warning
annotations:
summary: "Etcd member communication slow (instance {{ $labels.instance }})"
description: "Etcd member communication slowing down, 99th percentil is over 0.15s for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: EtcdHighNumberOfFailedProposals
expr: increase(etcd_server_proposals_failed_total[1h]) > 5
for: 5m
labels:
severity: warning
annotations:
summary: "Etcd high number of failed proposals (instance {{ $labels.instance }})"
description: "Etcd server got more than 5 failed proposals past hour\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: EtcdHighFsyncDurations
expr: histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket[5m])) > 0.5
for: 5m
labels:
severity: warning
annotations:
summary: "Etcd high fsync durations (instance {{ $labels.instance }})"
description: "Etcd WAL fsync duration increasing, 99th percentil is over 0.5s for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: EtcdHighCommitDurations
expr: histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket[5m])) > 0.25
for: 5m
labels:
severity: warning
annotations:
summary: "Etcd high commit durations (instance {{ $labels.instance }})"
description: "Etcd commit duration increasing, 99th percentil is over 0.25s for 5 minutes\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
#apply 应用
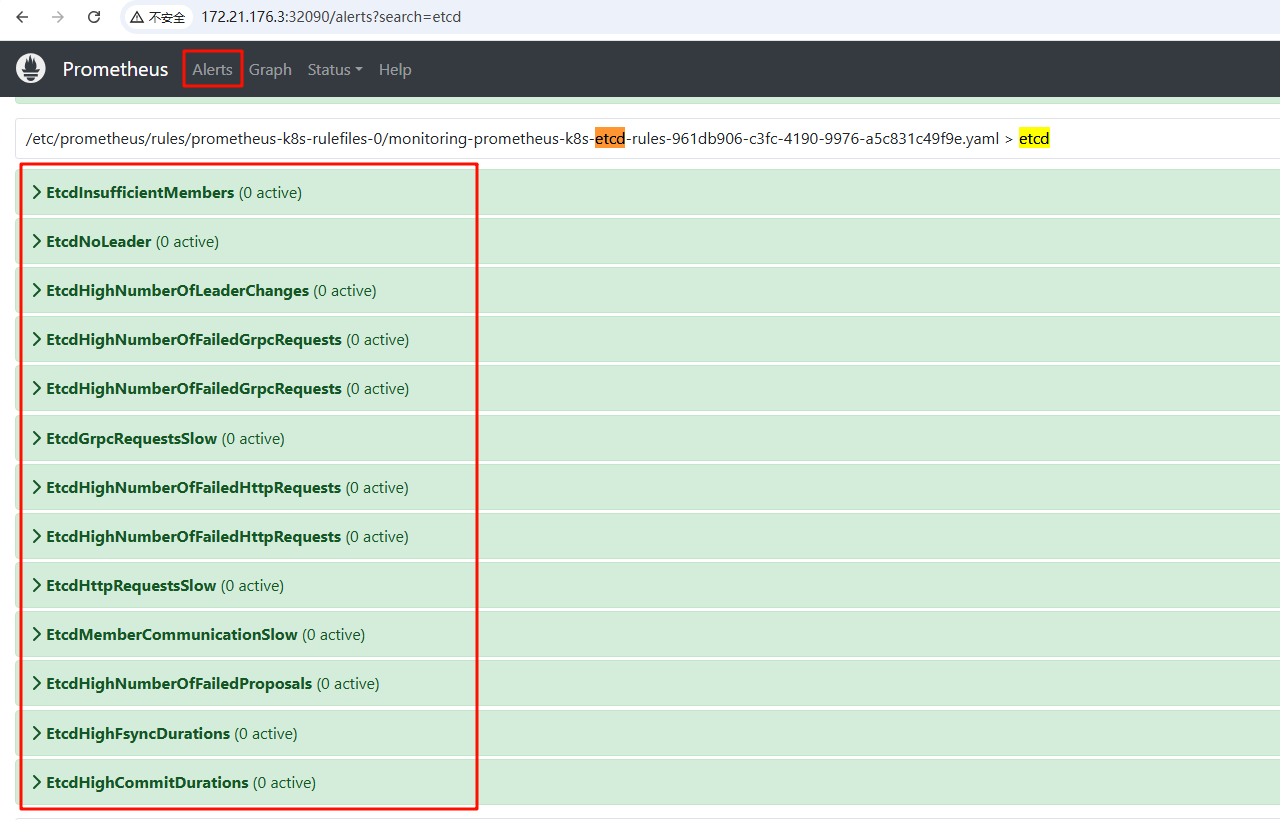
kubectl apply -f manifests/etcd-serviceMonitorRule.yaml
prometheusrule.monitoring.coreos.com/prometheus-k8s-etcd-rules created web页面点击alerts 查看刚才配置的报警规则是否生效
6.通过grafana查看图表
Grafana 是一款开源的数据可视化与监控平台,支持 30+ 数据源(如 Prometheus、InfluxDB、MySQL、Elasticsearch 等),可动态展示实时数据并生成交互式仪表盘。最重要的是,导入数据源后,网上有很多大神做好的模板可以开箱即用。下面的etcd就直接采用网上的模板直接拿来用。
6.1选择 构建一个新的表盘
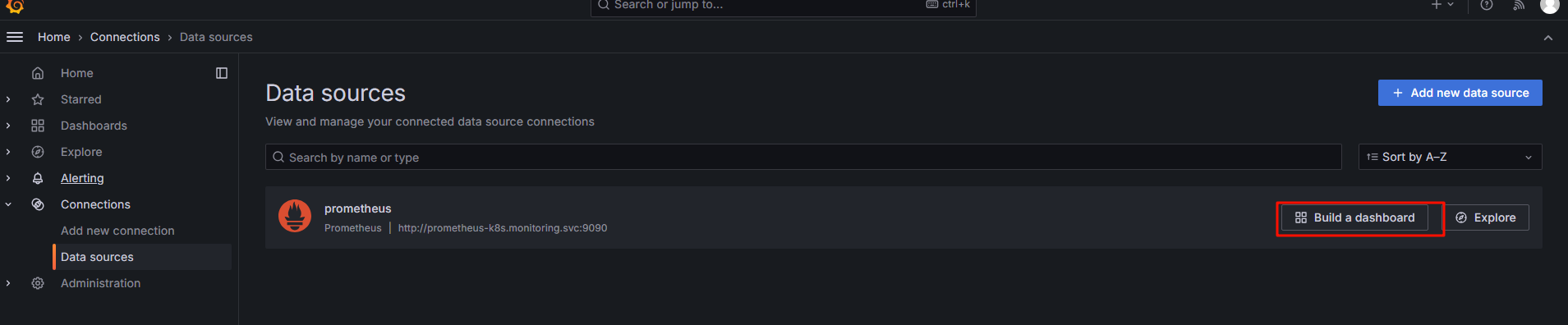
6.2导入表盘
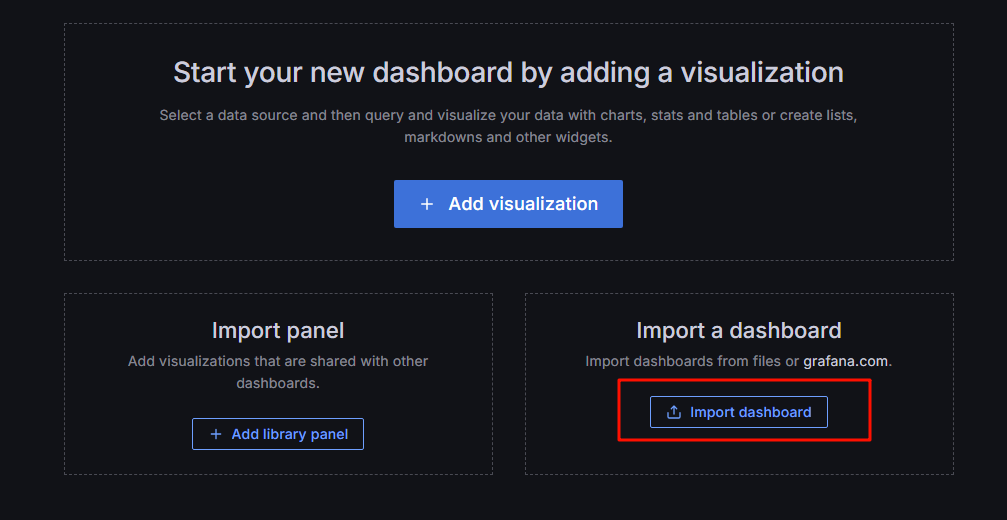
6.3 个人监控etcd喜欢用3070这个别人做好的表盘,点击右侧导入
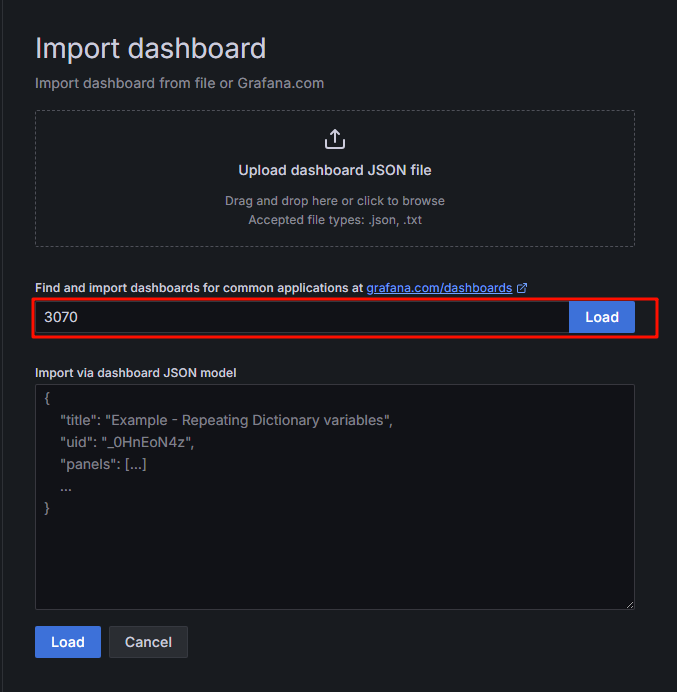
6.4取名后导入
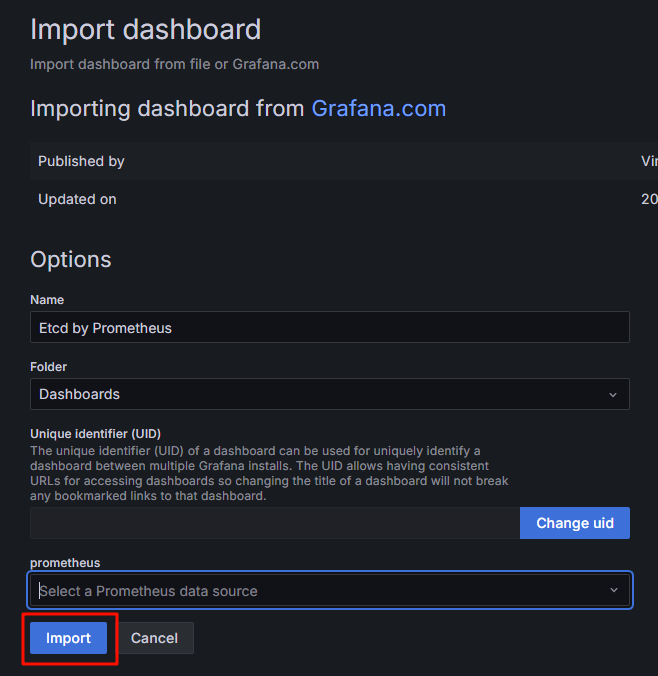
6.5查看数据
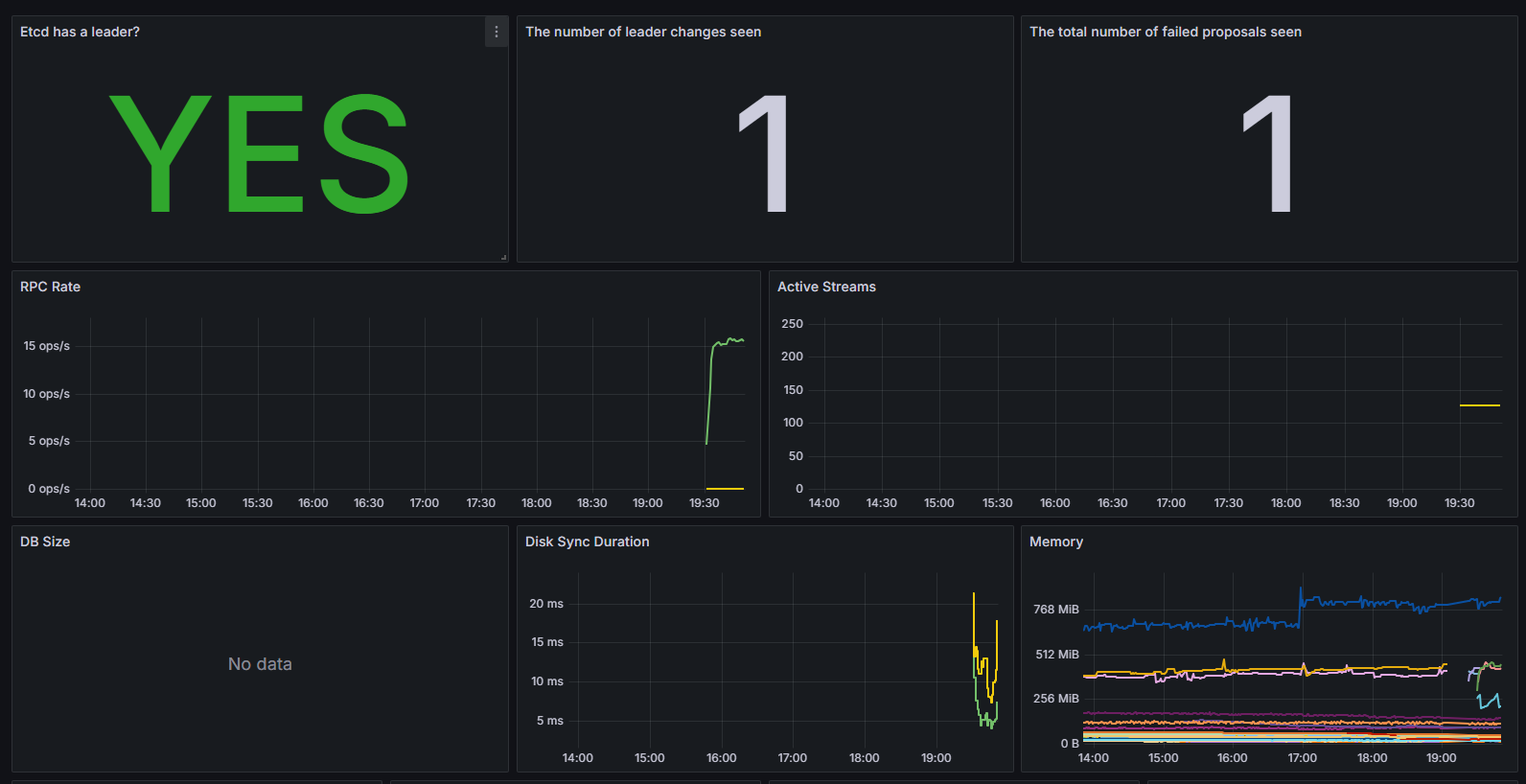
至此,一个完整的ETCD的监控预警就完成了。我们来梳理一下流程
1.创建对应的 service和endpoint
2.创建对应的 ServiceMonitor 对象来进行监控
3.创建对应的rule规则来进行设置阈值,这个可以去上面给的github地址里面搜索,常见的基本都有
4.设置grafana的图表,这个可以参考网上的模板
看起来真麻烦,如果我有几百个pod,不是要创建几百个ServiceMonitor 对象来进行监控?有没有简单的方法?甚至能不能让他做到通过一些规则自动来监控?下一章节我们一起来学习prometheus的自动发现规则。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号