2025,每天10分钟,跟我学K8S(四十八)- Prometheus(五)发送钉钉报警
前面我们学习了K8S中Prometheus 的各种监控配置,但是有了这些告警,怎么让监控人员及时发现并处理,总不能让监控人员一直盯着prometheus的页面吧,如何将告警内容发布出来,这就是接下来要学习的。
前面的课程中我们知道我们可以通过 AlertManager 的配置文件去配置各种报警接收器,那应该怎样去修改配置呢?
查看 AlertManager Dashboard 的 status页面下的config,发现这里的值和kube-prometheus/manifests/alertmanager-secret.yaml 下面的内容一样,我们这边采用钉钉报警,钉钉在2020年7月进行升级了。需要配置sign才可以发送消息
一、部署核心组件
1. 创建钉钉机器人
自动2020年钉钉机器人改版后,现在的机器人只选择「加签」或「自定义关键词」安全验证方式。
1.1、在钉钉群中创建自定义机器人,选择「加签」或「自定义关键词」安全验证方式。
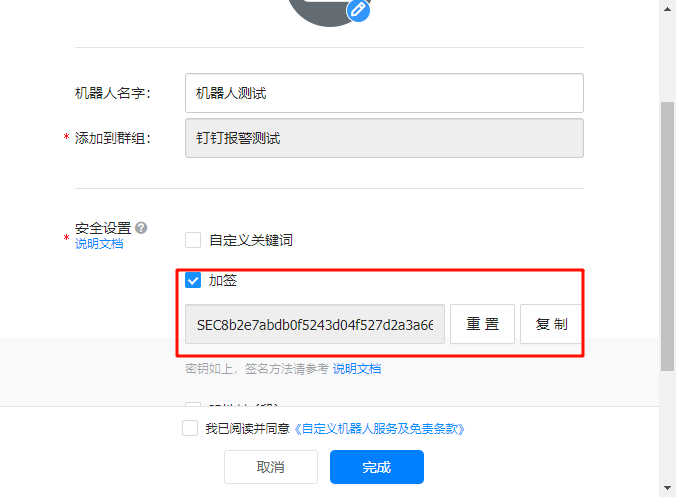
选择加签模式,并且记录好这里的加签内容
SEC8b2e7abdb0f5243d04f527d2a3a66d7e53e1a66462936ef84c1aeb3978e96df5
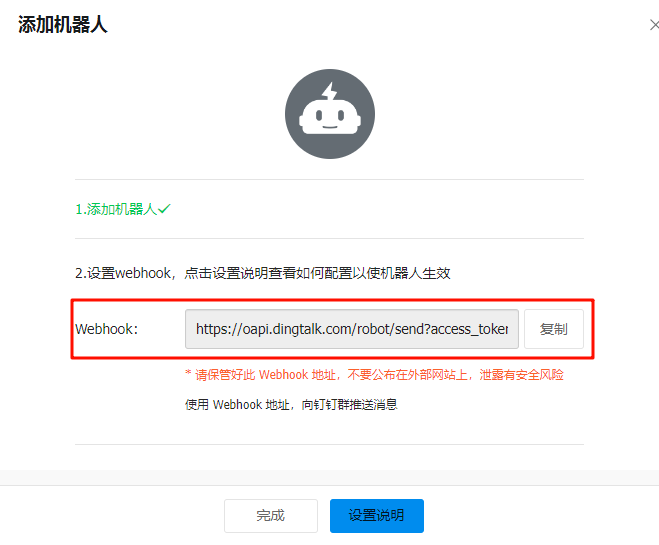
1.2、记录生成的 Webhook URL(如 https://oapi.dingtalk.com/robot/send?access_token=xxx)和加签密钥(如有)。
2. 部署钉钉 Webhook 插件
使用 Kubernetes YAML 部署 prometheus-webhook-dingtalk(推荐官方镜像 timonwong/prometheus-webhook-dingtalk:v2.1.0):
# cat dingtalk-webhook-deploy.yaml
apiVersion: v1
kind: Service
metadata:
name: dingtalk
namespace: monitoring
labels:
app: dingtalk
spec:
selector:
app: dingtalk
ports:
- name: dingtalk
port: 8060
protocol: TCP
targetPort: 8060
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: dingtalk
namespace: monitoring
spec:
replicas: 2
selector:
matchLabels:
app: dingtalk
template:
metadata:
name: dingtalk
labels:
app: dingtalk
spec:
containers:
- name: dingtalk
image: docker.1ms.run/timonwong/prometheus-webhook-dingtalk:v2.1.0
imagePullPolicy: IfNotPresent
args:
- --web.listen-address=:8060
- --config.file=/etc/prometheus-webhook-dingtalk/config.yml
ports:
- containerPort: 8060
volumeMounts:
- name: config
mountPath: /etc/prometheus-webhook-dingtalk
volumes:
- name: config
configMap:
name: prometheus-webhook-dingtalk-config
3. 配置钉钉插件
创建 dingtalk-configmap.yaml 和 自定义告警模板
记得替换这里的access_token和secret
# cat dingtalk-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-webhook-dingtalk-config
namespace: monitoring
data:
config.yml: |-
templates:
- /etc/prometheus-webhook-dingtalk/default.tmpl
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=3037cf6879c4749684e2a99b916a749fcfeb6fde835151bd84758636f5fbb04b #修改为钉钉机器人的webhook
secret: SEC8b2e7abdb0f5243d04f527d2a3a66d7e53e1a66462936ef84c1aeb3978e96df5 #修改钉钉机器人的加签
mention:
all: true
message:
text: '{{ template "default.tmpl" . }}'
default.tmpl: |
{{ define "default.tmpl" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
============ = **<font color='#FF0000'>告警</font>** = ============= #红色字体
**告警名称:** {{ $alert.Labels.alertname }}
**告警级别:** {{ $alert.Labels.severity }} 级
**告警状态:** {{ .Status }}
**告警实例:** {{ $alert.Labels.instance }} {{ $alert.Labels.device }}
**告警概要:** {{ .Annotations.summary }}
**告警详情:** {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}
**故障时间:** {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
============ = end = =============
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
============ = <font color='#00FF00'>恢复</font> = ============= #绿色字体
**告警实例:** {{ .Labels.instance }}
**告警名称:** {{ .Labels.alertname }}
**告警级别:** {{ $alert.Labels.severity }} 级
**告警状态:** {{ .Status }}
**告警概要:** {{ $alert.Annotations.summary }}
**告警详情:** {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}
**故障时间:** {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
**恢复时间:** {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
============ = **end** = =============
{{- end }}
{{- end }}
{{- end }}
二、配置 Alertmanager
1. 修改 Alertmanager 配置
# cat alertmanager.yaml
global:
resolve_timeout: 15s
inhibit_rules: ##静默规则:当同一个job内,出现多个告警时,只将高级别告警发送出来
- source_match: ##发送的告警标签
severity: 'critical'
target_match: ##被抑制的告警标签
severity: 'warning'
equal: ['alertname','namespace'] ##匹配的标签,即当同一个job出现多个告警的时候,会优先发出级别为critical的告警
route: ##顶级路由,可以通过制定不同的路由,将不同的告警信息发送给不同的人,这里顶级路由需要匹配所有的告警
group_by: ['alertname','namespace'] ##分组,需要匹配所有的告警,所以这里可以用监控namespace分组
group_wait: 30s ## 分组等待的时间
group_interval: 5m ## 上下两组发送告警的间隔时间
repeat_interval: 1h ## 重复发送告警时间。默认1h
receiver: webhook ## 默认的发送人 这里选择webhook,即钉钉
routes: ## 子路由
- match:
alertname: warning ## 将warning的告警发送给webhook工作组
receiver: webhook
receivers: #定义谁来通知报警
- name: 'webhook' ##钉钉样式
webhook_configs:
#- url: 'http://webhook-dingtalk:8060/dingtalk/webhook1/send'
- url: 'http://dingtalk.monitoring.svc.cluster.local:8060/dingtalk/webhook1/send'
send_resolved: true
2. 应用配置
- 更新 Alertmanager 配置后重启服务:
# 删除旧secret
kubectl delete secret alertmanager-main -n monitoring
# 创建新secret
kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml -n monitoring三、配置 Prometheus 告警规则
1. 定义告警规则
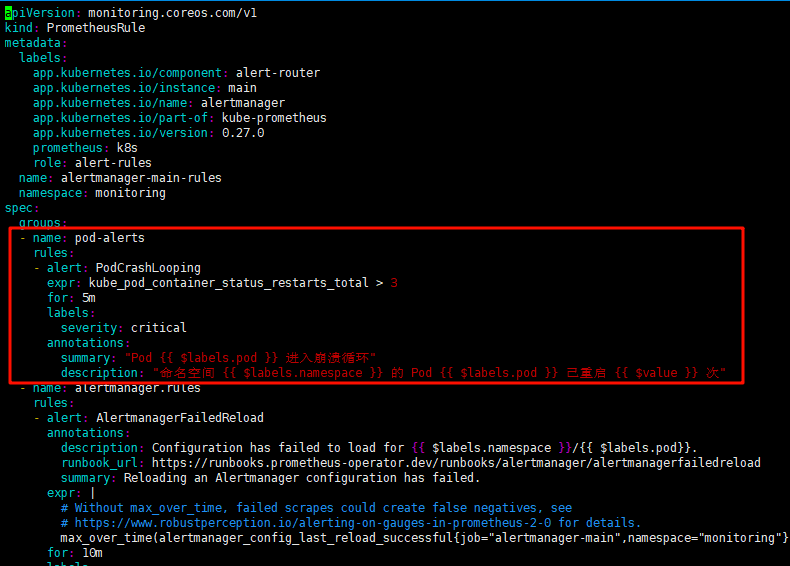
在manifests/alertmanager-prometheusRule.yaml 中新增一下自定义规则
规则内容为当pod重启3次后报警
# vim alertmanager-prometheusRule.yaml
- name: pod-alerts
rules:
- alert: PodCrashLooping
expr: kube_pod_container_status_restarts_total > 3
for: 5m
labels:
severity: critical
annotations:
summary: "Pod {{ $labels.pod }} 进入崩溃循环"
description: "命名空间 {{ $labels.namespace }} 的 Pod {{ $labels.pod }} 已重启 {{ $value }} 次"![]()
2. 触发测试加载规则
curl -X POST http://<SVC下prometheus-k8s的IP>:9090/-/reload # 热加载配置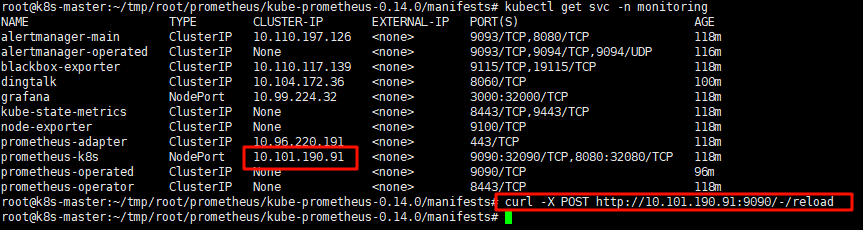
四、验证
默认告警
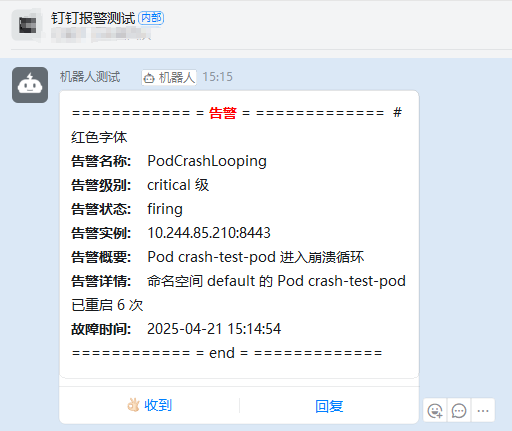
自定义告警
由于我们自定义的警告是一个pod重启3次即告警,那创建一个不停重启的pod就可以了.
记得修改镜像地址,不然去默认地址拉取的话会一直卡在初始化拉取镜像
# vim crash_pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: crash-test-pod
spec:
containers:
- name: crash-container
image: m.daocloud.io/docker.io/library/busybox:latest
command: ["sh", "-c", "exit 1"] # 容器启动后立即退出
restartPolicy: OnFailure # 退出后自动重启
# kubectl apply -f crash_pod.yaml通过Prometheus的web页面去查询重启次数大于3次的

再去钉钉查看报警
五、他人写好的告警规则
很多其他的自定义规则报警,可以参考之前提到的github中的内容

 浙公网安备 33010602011771号
浙公网安备 33010602011771号