新征程2.18 数据结构 番外篇 kmp的奇妙冒险
前言(与内容无关,可跳过):
昨天在写博客时,写了太多的废话,极其影响观看效果,于是我痛改前非,毅然写下了kmp的千古名篇(bushi),成为后世学习kmp的典范。
省流:以后不再写长博客了。
今天的绝大多数时间都在讲kmp,而且也是今天比较难理解的部分;所以话不多说,我们直接进入正题。题目传送门
KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next[]数组实现,函数本身包含了模式串的局部匹配信息。
kmp利用匹配失败时失败之前的已知部分时匹配的这个有效信息,保持主串的 i 指针不回溯,通过修改模式串(子串)的 j 指针,使模式串尽量地移动到有效的匹配位置。使得时间复杂度变为 O(n+m)。
#include<bits/stdc++.h>
using namespace std;
int len1,len2,ans,k;
const int N=1000010;
int pos[N],nt[N];
char s1[N],s2[N];
int main()
{
scanf("%s",s1+1);len1=strlen(s1+1);
scanf("%s",s2+1);len2=strlen(s2+1);
k=0;
for(int i=2;i<=len2;++i)
{
while(k&&s2[k+1]!=s2[i])k=nt[k];
if(s2[k+1]==s2[i])++k;
nt[i]=k;
}
k=0;
for(int i=1;i<=len1;++i)
{
while (k&&s2[k+1]!=s1[i])k=nt[k];
if(s2[k+1]==s1[i])++k;
if(k==len2)pos[++ans]=i-len2+1;
}
for(int i=1;i<=ans;++i)printf("%d\n",pos[i]);
for(int i=1;i<=len2;++i)printf("%d ",nt[i]);
return 0;
}
思想好理解,但next数组的推导却有点难度;
先引入一个新的概念——前缀表,前缀表可以暂时理解为:字符串最长公共前缀后缀长度。
然后明确一下前缀、后缀和前缀表的概念:
前缀:必须包含第一个字母但不包含最后一个字母的连续子串
后缀:必须包含最后一个字母但不包含第一个字母的连续子串
前缀表:最长相等前后缀(即这个字符串的前缀和后缀相等,还是最长的那个)
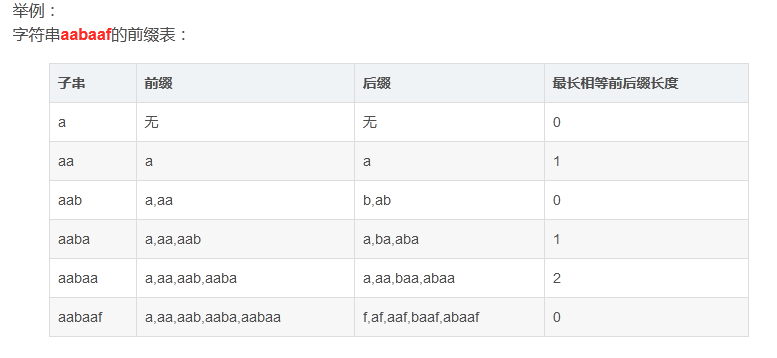
遗憾的是,由于篇幅受限(我也不会)。这里并不展开讲next数组的回退等高端操作,有兴趣的朋友可以去这里深度研究。
本文部分内容摘自csdn,对原作者表示深深感激
本文来自博客园,作者:deviancez,转载请注明原文链接:https://www.cnblogs.com/deviance/articles/18112956

 浙公网安备 33010602011771号
浙公网安备 33010602011771号