初识MySQL
一、前言
作为程序猿,虽然已经使用了很多年MySQL,但是其基本的原理还是一知半解,所以看了一些比较好的文章,记下来,做个系列笔记。
本篇为基础篇内容,基础篇主要涉及:select语句如何执行,update语句如何更新,简单了解MySQL的事务,初步认知MySQL的锁的概念。
*注:本篇文章MySQL引擎默认为InnoDB*
二、从一条select语句说起

-------- 图片来自丁奇老师的MySQL实战45讲-MySQL架构设计图
上图为MySQL的机构设计图,MySQL服务大致可分为三部分:客户端,服务层(Server层),引擎层。
客户端:提供连接MySQL服务的功能。
服务层:包含连接器,查询缓存(8.0版本将彻底删除),分析器,优化器,执行器,以及MySQL的内置函数和跨存储引擎的存储过程,触发器,视图等。
引擎层:提供数据的存储和获取。MySQL中,引擎是插件式的,支持多个引擎。
1、执行流程
*由于之后的版本就要移除查询缓存,所以我们不再讨论查询缓存*
当我们执行select * from `T` where `id` = 1;这条SQL语句时,其执行过程为:
1、客户端携带账户密码通过连接器连接MySQL的Server层,并在权限表中查到用户权限,存储在变量中,供之后权限验证使用。
2、分析器分析SQL语法、字段、表的合法性并生成SQL执行计划。【执行器阶段会检查权限】
3、优化器优化SQL执行计划,如选择合适的索引。
4、执行器执行SQL执行计划,检查权限,打开表,处理数据。【调用引擎层提供的查询接口】
2、使用索引
MySQL中的索引相当于书本中的目录,帮助我们快速查询到对应的数据。在优化器阶段,MySQL会选择合适的索引去执行查询。
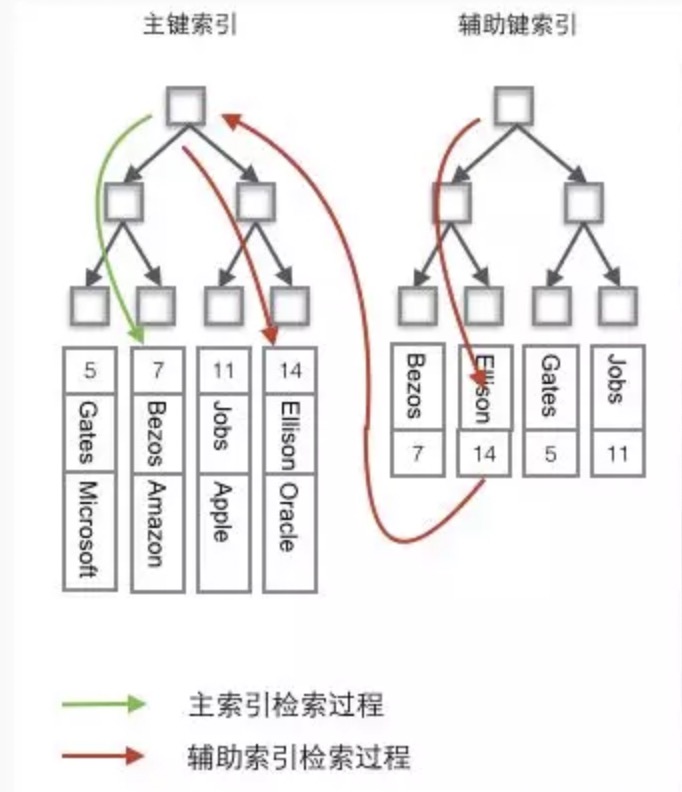
-------- 图片来自网络-MySQL的InnoDB引擎B+树索引结构。
索引按照结构分为主键索引和辅助键索引(也叫聚簇索引和非聚簇索引)。在主键索引中的叶子节点上,存储着该行的数据信息;在辅助键索引的叶子节点上,存储着该行数据的主键信息。
所以当我们执行select * from `T` where `id` = 1;时,因为id为主键,优化器会选择主键索引去执行从查询任务,通过主键索引,直接可以获取到数据行信息。
假如我们执行的是select * from `T` where `k` = 10;k字段为普通索引,那么就需要通过辅助键索引找到主键索引,然后通过主键索引再获取到数据行信息,这个过程称为回表。由于辅助键索引查询需要回表,所以普通索引检索速率比主键索引效率慢。
假如我们执行的是select `id` from `T` where `k` = 10;k字段为普通索引,那么此时查询的辅助键索引叶子节点上已经有的主键id的值,所以直接可以获取到,不需要回表。在查询中,索引k涵盖了我们的查询结果,称为覆盖索引。合理的使用覆盖索引能有效的优化查询效率。
三、update数据
当执行update `T` set age='10' where `id` = 1;更新时,涉及到的内容主要有:binlog(Server层),redolog(引擎层),change buffer,事务隔离机制,行锁(引擎层)等。
1、单个更新
简单的分析下在InnoDB引擎中,RR隔离级别(可重复读)下update的执行逻辑:
MySQL中的更新机制使用的Write-Ahead Logging(预写式日志),即先写日志再更新。
1、走Server层的连接器,分析器,优化器,执行器。
2、执行器阶段根据条件查询数据页是否在内存中,不在内存中则取出来放在内存中,并加MDL读锁,然后将内存中该行数据更新。
3、引擎层将该行数据加行锁,写redolog,并将其置于prepare状态
4、Server层写binlog。
5、引擎层提交事务,更新redolog,将其置于commit状态,然后释放MDL读锁和行锁。
以上就是更新的全部流程,此时数据还未落盘,MySQL会在适当时间通过后台线程将内存数据刷新到磁盘上。
binlog是Server层提供的日志记录,所有引擎通用,且追加写。
redolog是InnoDB引擎提供的日志记录,引擎独有,结合binlog可以提供crash-safe(崩溃安全)机制,但是是循环写,后写的会覆盖前写的redolog。
MySQL更新机制中使用两阶段写日志提交,是为了保证更新效率,将随机写磁盘转换成顺序写磁盘。
而针对change buffer也是MySQL为了更新效率而添加的,但是change buffer只针对数据页不在内存中,且索引非唯一索引使用。
change buffer原理为:update `T` set age='10' where `k` = 10;k字段为普通索引,当MySQL检测到该数据页不在内存中,则将其更新记录放到change buffer中(change buffer的更新记录会写redolog),MySQL会在适当时间将其更新到磁盘上。【若数据页已经在内存中,则不会使用到change buffer,直接更新内存】
列举一个change buffer插入数据的示意图加深理解:
语句:insert into `T`(`id`,`k`) values(1,10),(2,20);

-------- 图片来自丁奇老师的MySQL实战45讲-change buffer
执行步骤为:
1、数据页1在内存中,直接更新内存。
2、数据页2不在内存中,将更新记录写在change buffer中。
3、将1,2操作记录到redolog中。
所以说,WAL机制(redolog)节省了随机写磁盘的IO消耗,而change buffer则节省了随机读磁盘的IO消耗。
2、并发情况
在并发情况下,就需要MySQL的事务隔离级别以及行锁的机制来避免数据更新竞争问题了。
我们知道事务隔离的四大原则是:原子性,一致性,隔离性,持久性。在隔离性原则下,当多个事务同时执行某些数据时,不可避免的会产生脏读,幻读,不可重复读等问题。为了尽量解决这些问题,MySQL引入了事务隔离级别,当前MySQL的默认隔离级别为可重复读(RR)。
四大隔离级别:
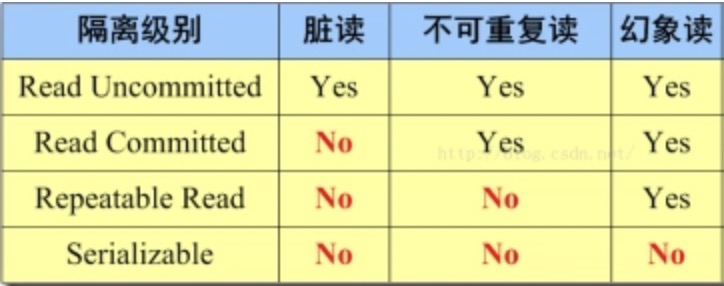
-------- 图片来源网络-事务隔离级别
在RR事务中,数据的隔离性是由一致性视图实现的,在事务启动时,MySQL会根据唯一事务ID和行数据ID(row trx_id)创建一个整库的快照供该事务操作。每个事务都是操作自己的一致性视图,事务之间操作不会互相影响,且逻辑前后数据的一致性能得到保障。例外的是在更新一行数据时是当前读,读当前最新的数据并更新,并不是读一致性视图中的数据,且会为该行数据加行锁,在该事务未commit时,如果其他事务也要更新该行数据,则会进入锁等待,必须等待前一事务commit后才能获得行锁并更新。
四、扩展知识
上面我们基本了解了MySQL的基本框架以及select和update的过程,接下来我们主要针对单个的知识进行一个详细的总结。
1、数据库连接
数据库建立连接是很耗费时间的,所以我们的业务应尽量使用长连接,并定时使用mysql_reset_connection来重置连接,清除连接内存
2、索引
根据索引树的效率分析,我们在建表时应该尽量建立自增主键ID,自增主键能有效避免二叉树分裂,增加数据时只用往后追加即可,查询数据时,根据主键ID查询直接到叶子节点,避免回表,效率最高。现实业务中,因为无法避免使用辅助索引,为了提升效率,我们可以合理建立组合索引实现索引覆盖,避免回表查询影响效率。
3、锁
MDL锁是MySQL默认加的,在事务提交时释放,其分为读锁和写锁,增删改查时加读锁,更改表结构时加写锁,读写互斥,写写互斥。
需要注意的是在修改表结构时,千万注意:
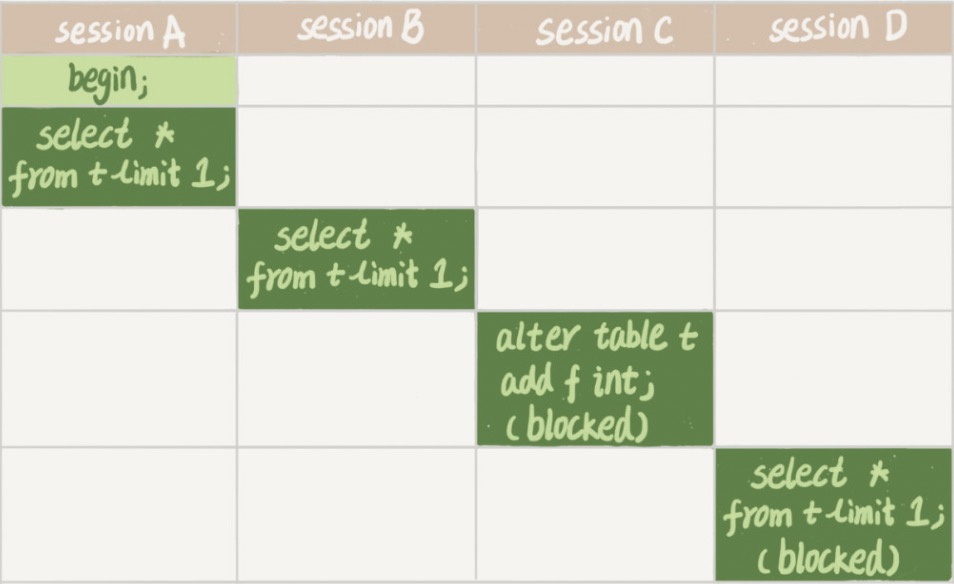
-------- 图片来自丁奇老师的MySQL实战45讲-MDL
A,B加MDL读锁,不互斥,可执行,且A事务未提交,未释放MDL读锁。
C为修改表结构,需要MDL写锁,读写互斥,陷入锁等待。
之后的D由于检测到C要获取写锁且在等待,读写互斥也陷入等待,之后的所有增删改查都将陷入等待,导致该表无法读写,此时再等待超时重建连接,那么很快整个库的线程就会爆满。
行锁是InnoDB引擎支持的,行锁使用时才加上,事务提交时释放,行锁是互斥的,只能等待释放才能操作该行数据。
在事务中使用行锁时需要注意将共用率比较高的操作放在后面,减少锁等待时间。
而且当两个事务互相依赖对方的行锁释放时,就可能会出现死锁。
如下图A,B互相等待释放行锁,就导致死锁。

-------- 图片来自丁奇老师的MySQL实战45讲-死锁
虽然MySQL中有死锁检测(innodb_deadlock_detect=on)但是在并发量比较高的业务中,直接连库操作是无论如何也避免不了出现问题的。所以使用数据库中间件来控制到库的并发度是必不可少的。
行锁时根据索引来实现的,当字段k无索引,执行了update `T` set `age`=10 where `k`=1;将会锁整张表以防止其他事务插入k为1的数据,
当执行update `T` set `age`=10 where `k`=1 limit 1;时,则只会锁一行。
4、事务隔离
无事务隔离可能会出现的:
脏读:A事务读到B事务未提交的更新内容。
幻读:A事务查询数据不存在,然后更新该数据时报错(查询后更新前数据被其他事务更新了)。
不可重复读:A事务前后查询结果不一样(第一次查询后第二次查询前数据被更新了)。
事务隔离级别有:
可重复读(RR):查询只承认在事务启动前就已经提交的事务。(事务开启时会创建一致性视图)
读提交(RC):查询只承认在语句执行前就已经提交的事务。(每执行一次SQL就创建一次一致性视图)
读未提交:一般不使用
串行化:一般不使用
需要注意的是begin/start transaction并不是一个事务的起点,执行到第一个语句时,事务才正式启动。要想立即启动事务,则可以使用start transaction with consistent snapshot。
五、最后
以上知识都是来源于互联网,理解错误不可避免,如有错误,请不吝指教。
参考连接:
丁奇-《MySQL实战45讲》
事务隔离级别:https://mp.weixin.qq.com/s/x_7E2R2i27Ci5O7kLQF0UA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号