Python爬虫简单实战
爬虫流程
1. 随便打开一个网站以及开发者工具(打开Network界面)
2. 随便输入内容触发
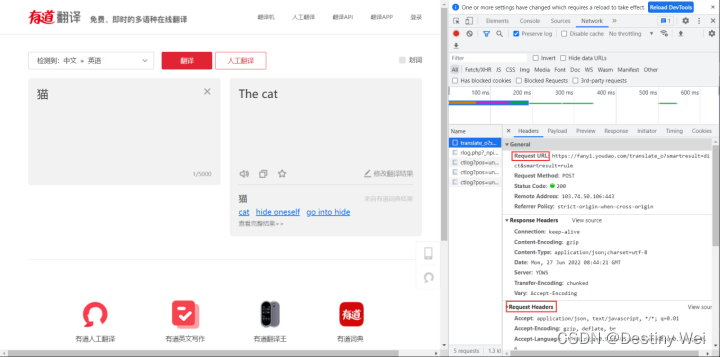
至此,我们可以获知请求发送的URL以及相关的请求头,将它们复制到Pycharm中
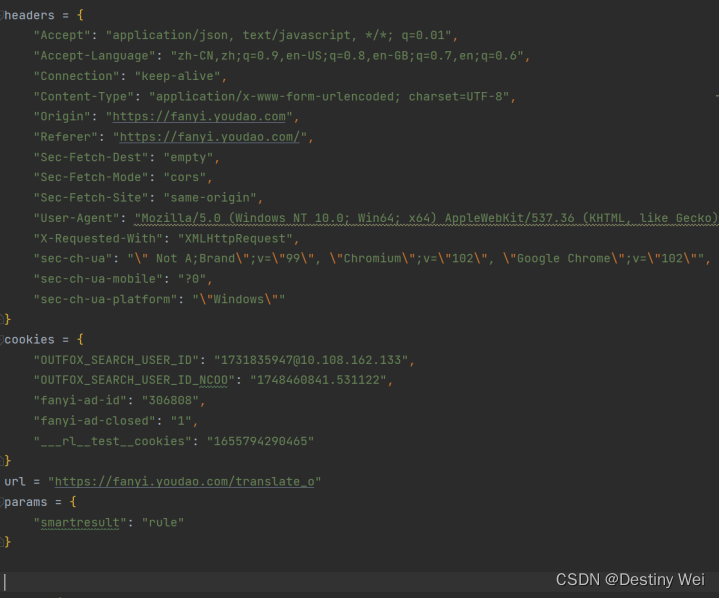
注意:cookies包含在Request Headers中,我们需要单独把它复制出来。
同时变量名可随意取,此处是为便于表达变量的含义。
3. 获取Form Data信息
接着,我们点击到达Payload界面,获取Form Data信息
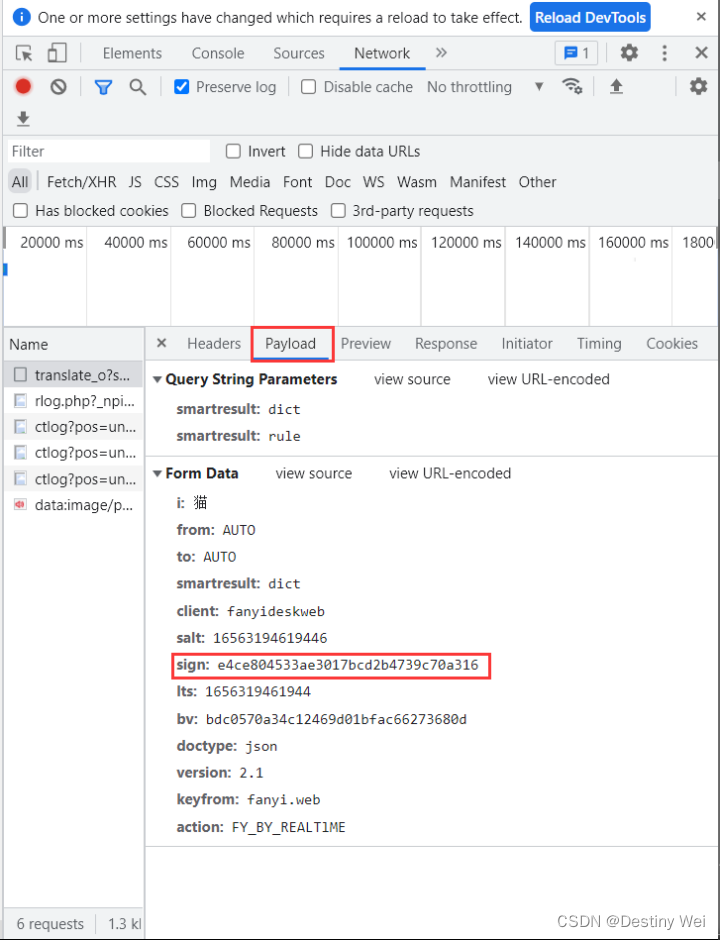
此时,我们可以根据变量名得知 sign 表示签名,这是爬虫破解最关键的一步!
4. 搜索 sign 关键字
然后我们点击开发者工具右上角三个点中的Search功能(或按 Ctrl + Shift + F) 搜索 sign 关键字
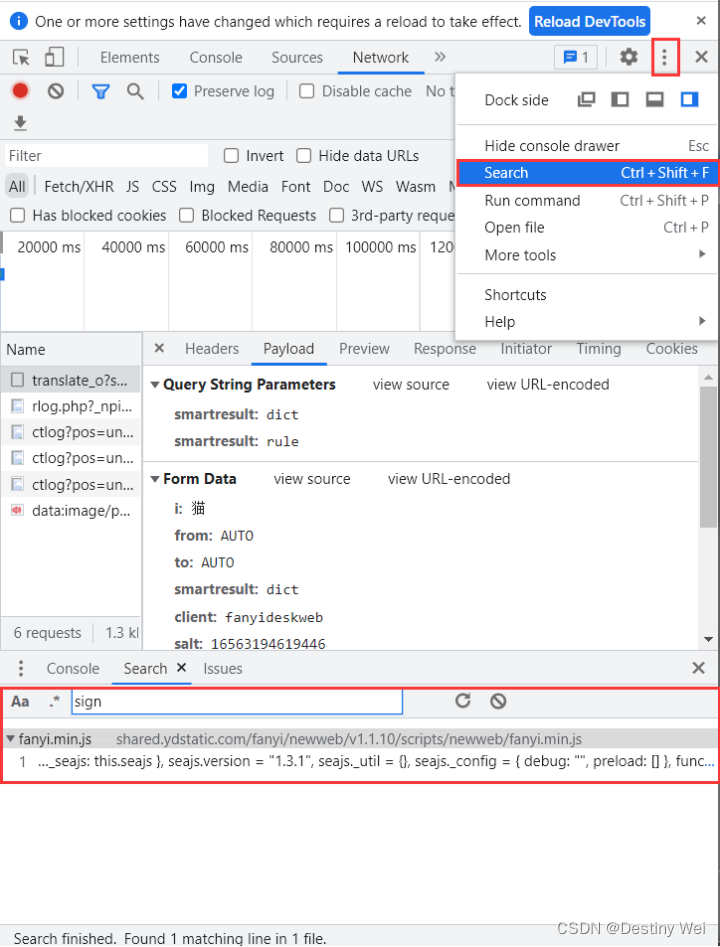
进入符合条件的文件,点击“ {} ” 进行格式
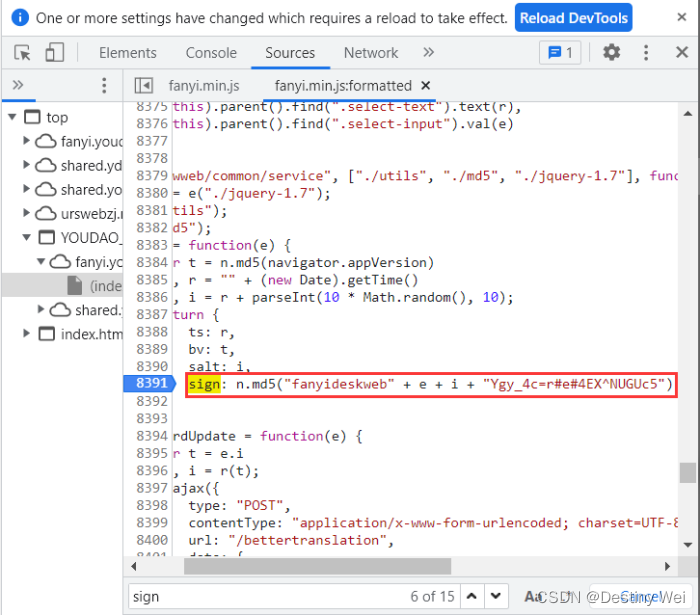
5. 搜索加密算法
接着我们按 Ctrl + F 继续搜索 sign 关键字寻找其具体的加密算法
![]()
6. 查看具体含义
到这我们在此行打上断点(即点击其对应行数使其变为蓝色),然后重新点击翻译按键内容触发断点,然后将鼠标放在 “e” 和 “i” 上查看其具体含义

从这我们可以知道 “e” 代表我们想要翻译的具体内容,而 “i” 从我们的经验可以判断出其应该是时间戳,至此我们可以知道 sign 加密的所有具体内容

7. 复制文本
然后我们将这段文本复制下来
![]()
注意:文本的内容顺序不可改变,否则得到的 sign 值将会完全不一样
8. 破解 sign
进入最关键的一步,破解得到相对应的 sign
word 我们可以得知就是我们的输入内容

salt 则是时间戳,此时我们通过打印 “int(time.time())” (注:python中 time.time() 函数为浮点数) 与Request Headers中的 salt 和 lts(其形式也与时间戳相似) 进行比较
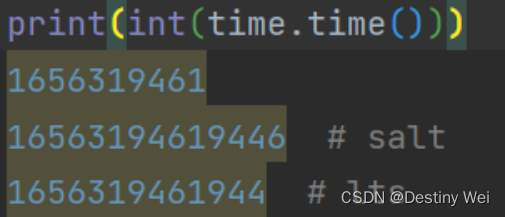
从这我们可以看出,salt 多出了四位,lts 多出了三位,在这我们直接乘以相差的位数即可

注意:实际算法并不完全是博主这样,实际算法我们可以回到刚才的 Source中去查看
实际算法如下:

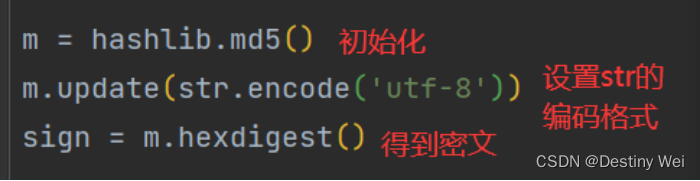
9. 编写 MD5 算法
然后我们开始编写 MD5 加密算法,百度既有现成的算法代码,大家可自行查阅
10. 发送 request 请求
接着,我们通过Pycharm发送 request 请求
注意:Pycharm中需要自行下载request模块,下载教程放在文章末尾
这里需要注意的是,浏览器中返回的都是 json 格式,所以我们需要返回开发者工具中找到我们所需要的翻译返回值
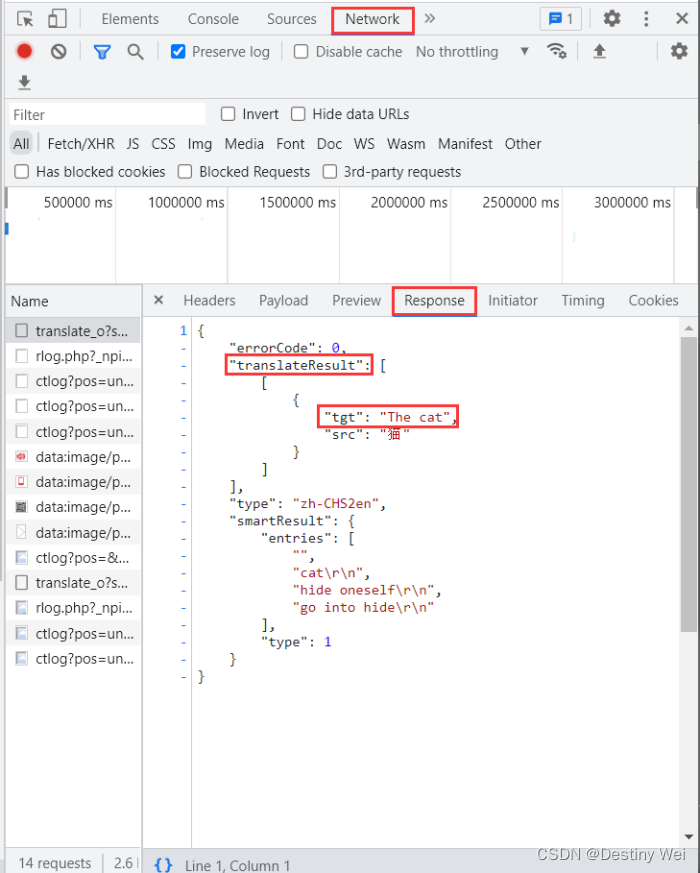
由此,我们的打印语句可以写为:
![]()
12. 执行效果
最后我们来看下执行效果:

完整代码
实用的方法
获取格式化后的 Json 格式
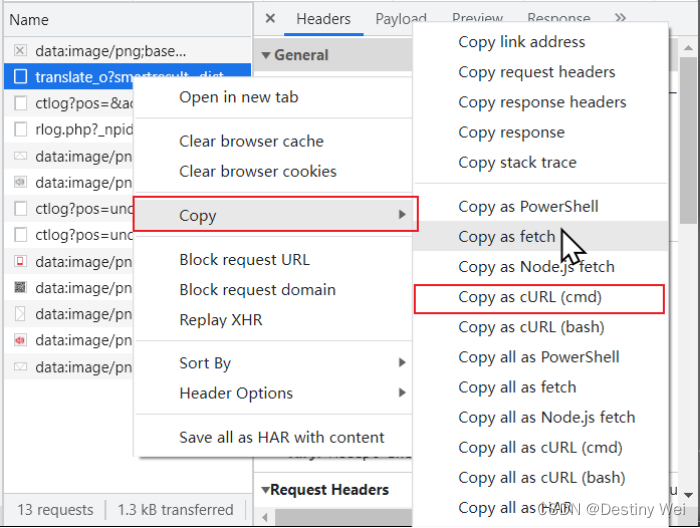
![]()
打开 “爬虫工具库” 网站 (
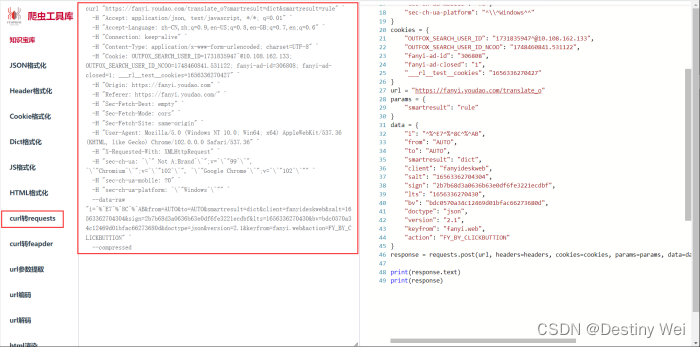
可能的报错
requests.exceptions.SSLError: HTTPSConnectionPool(host='
解决方案:
安装一下几个requests依赖包就可以解决此问题
pip install cryptography
pip install pyOpenSSL
pip install certifi
requests模块下载
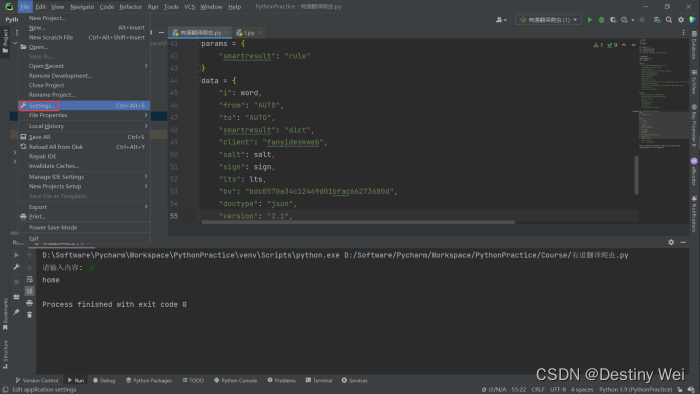
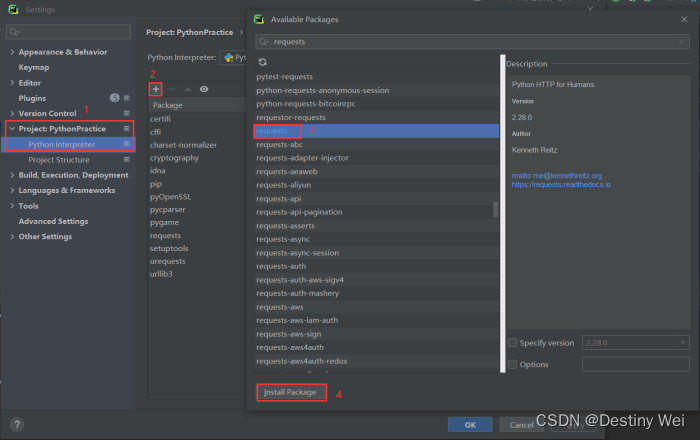
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号