
论文复现实践
网络攻防实践期末作业论文复现
一、实验内容及原理
1.1 DNNs介绍
深层神经网络(DNNs),现在常被称为黑匣子,因为经过训练的模型是一系列的权重和函数,这与它所体现的分类功能的任何直观特征不匹配。训练每个模型以获取给定类型的输入(例如面部图像、手写数字的图像、网络流量的轨迹、文本块)、执行一些推断计算并生成一个预定义的输出标签,例如,表示在图像中捕捉到的人脸的人的姓名的标签。
深度神经网络(DNNs)是拥有多层感知器的架构,用来解决复杂的学习问题。然而,DNNs在训练和概括中面临挑战。传统的DNNs互联的大量数据可能会过拟合,需要不同的训练方法来提高泛化。神经网络权重的前训练(pretrain)和神经网络新品种旨在克服这些问题。尤其是卷神经网络,被设计用于处理图像,通过最小化可训练的重量并提供强大的泛化能力。这些网络在多个领域复杂的学习任务中表现出良好的势头。
深神经网络(DNN)由辛顿等人定义为“一个前馈人工神经网络,其包含不止一个隐藏单位的隐藏层”。DNN有许多处理层,可用于学习多层的抽象数据的表示。生产非线性模块获得的不同层,用于将表示层从单层表示转换为更抽象的层表示。通过使用这些层、用于分类的数据的特征增强,而无关的特征被抑制。深卷积网和递归网络也属于DNN,使用它们的算法在处理文本,图片,视频,语音和音频等方面带来了突破。
深层神经网络(DNNs)在广泛的关键应用中发挥着不可或缺的作用,从面部和虹膜识别等分类系统,到家庭助理的语音接口,到创造艺术形象和引导自动驾驶汽车。在安全空间中,DNNs用于从恶意软件分类到二进制逆向工程和网络入侵检测。
尽管取得了这些令人惊讶的进展,但人们普遍认为,缺乏可解释性是阻止更广泛地接受和部署DNNs的主要绊脚石。从本质上看,DNN是数字黑匣子,不适合人类的理解。许多人认为,对神经网络解释能力和透明度的需求是当今计算的最大挑战之一,这就是深度神经网络。
1.2原理
(1)从感知机到神经网络
感知机的模型是一个有若干输入和一个输出的模型,如下图:
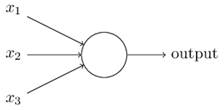
输出和输入之间学习到一个线性关系,得到中间输出结果:

接着是一个神经元激活函数,得到输出结果1或者-1:
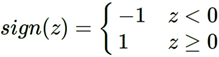
这个模型只能用于二元分类,且无法学习比较复杂的非线性模型,因此在工业界无法使用。而神经网络则在感知机的模型上做了扩展,总结下主要有三点:
1)加入了多层隐藏层,增强模型的表达能力。
2)输出层神经元可以不止一个,可以有多个输出,这样模型可以灵活的应用于分类,回归,降维和聚类等。下图输出层有4个神经元。

3)对激活函数做扩展。感知机的激活函数是sign(z),虽然简单但是处理能力有限,因此神经网络中一般使用:Sigmoid,tanx, ReLU,softplus,softmax等加入非线性因素,提高模型的表达能力。
(2)DNN的基本结构
DNN可以理解为有很多隐藏层的神经网络。这个很多其实也没有什么度量标准, 多层神经网络和深度神经网络DNN其实也是指的一个东西,当然,DNN有时也叫做多层感知机(Multi-Layer perceptron,MLP)。
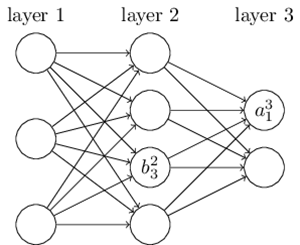
从DNN按不同层的位置划分,DNN内部的神经网络层可以分为三类,输入层,隐藏层和输出层,如下图示例,一般来说第一层是输出层,最后一层是输出层,而中间的层数都是隐藏层。
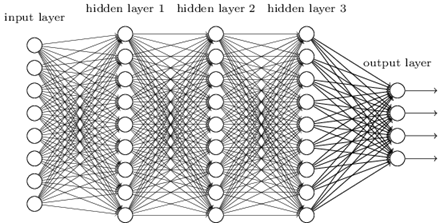
层与层之间是全连接的,也就是说,第i层的任意一个神经元一定与第i+1层的任意一个神经元相连。虽然DNN看起来很复杂,但是从小的局部模型来说,还是和感知机一样,即一个线性关系z=∑wixi+bz=∑wixi+b加上一个激活函数σ(z)σ(z)。
由于DNN层数多,则我们的线性关系系数ww和偏倚bb的数量也就是很多了。具体的参数在DNN是如何定义的呢?
虽然DNN看起来很复杂,但是从小的局部模型来说,还是和感知机一样,即一个线性关系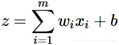
加上一个激活函数σ(z)。
由于DNN层数多,参数较多,线性关系系数w和偏倚b的定义需要一定的规则。线性关系系数w的定义:第二层的第4个神经元到第三层的第2个神经元的线性系数定义为。上标3代表线性系数w所在的层数,而下标对应的是输出的第三层索引2和输入的第二层索引4。你也许会问,为什么不是w342呢?这主要是为了便于模型用于矩阵表示运算,如果是w342而每次进行矩阵运算是wTx+b,需要进行转置。将输出的索引放在前面的话,则线性运算不用转置,即直接为wx+b。注意,输入层没有w参数、偏倚参数b。
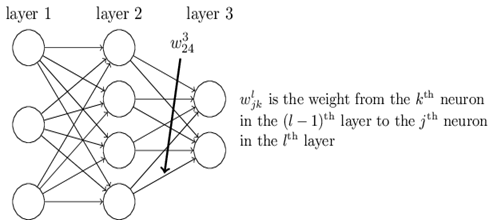
再来看看偏倚bb的定义。还是以这个三层的DNN为例,第二层的第三个神经元对应的偏倚定义为b23b32。其中,上标2代表所在的层数,下标3代表偏倚所在的神经元的索引。同样的道理,第三个的第一个神经元的偏倚应该表示为b31b13。同样的,输入层是没有偏倚参数bb的。
(3)DNN前向传播算法数学原理
假设我们选择的激活函数是σ(z)σ(z),隐藏层和输出层的输出值为aa,则对于下图的三层DNN,利用和感知机一样的思路,我们可以利用上一层的输出计算下一层的输出,也就是所谓的DNN前向传播算法。

(4)DNN前向传播算法
DNN的前向传播算法也就是利用我们的若干个权重系数矩阵WW,偏倚向量bb来和输入值向量xx进行一系列线性运算和激活运算,从输入层开始,一层层的向后计算,一直到运算到输出层,得到输出结果为值。输入: 总层数L,所有隐藏层和输出层对应的矩阵WW,偏倚向量bb,输入值向量xx,输出:输出层的输出aLaL。
1)初始化a1=xa1=x;
2) for l=2l=2 to LL, 计算:al=σ(zl)=Wlal−1+blal=σ(zl)=Wlal−1+bl;
最后的结果即为输出aLaL。
1.3后门攻击
- 1.3.1什么是后门攻击
对抗样本通过攻击算法在样本数据上进行改变实现攻击模型的目的,而Trojan Neural Network(TNN)通过改变模型参数同样可以使模型错误分类的攻击效果。从数据和模型两种角度都能在神经网络模型中植入后门。后门攻击只有当模型得到特定输入时才会被触发,然后导致神经网络产生错误输出,因此非常隐蔽不容易被发现。在大型数据集上进行机器学习模型的训练,通常需要多方基于梯度共同进行训练;在模型训练以及使用的整个过程中需要多次对梯度进行更新,因此在更新模型参数的过程中多方都可能会对机器学习模型进行攻击。
当前研究表明TNN攻击能够利用对训练数据投毒的方式进行攻击,也可以不通过训练数据进行攻击。如果选择不通过训练数据进行攻击,TNN攻击一般会选择一个触发样本,基于触发样本生成一组样本对模型进行训练。训练TNN的目标函数通常是最小化模型在正常样本中的误差,并且最大化模型在木马触发样本中的误差。与对抗样本攻击一样,TNN攻击也可以根据木马触发样本分为有目标攻击和无目标攻击。如果想要对TNN攻击进行防护,一种方式是重新建模,也就是对模型进行重新训练,另一种则是建立检测模型对TNN攻击进行检测。 - 1.3.2检测方法
关于神经网络中后门攻击的检测在最新的研究中,2019年S&P上面已经提出了一些检测方法。例如,在下图中说明了该神经网络后门攻击检测方法的抽象概念。它表示了一个简化的一维分类问题,其中包含3个标签(label A for circles, B for triangles, and C for squares)。图中形象的显示了数据样本在输入空间中的位置,以及模型的决策边界。被攻击的模型有个恶意触发会导致分类结果为A。由于后门的存在触发在属于B和C的区域中产生另一个维度。任何包含触发的输入在触发维度中都有更高的值(被攻击模型中的灰色圈),因此会被分类为A,而不会导致分类为B或C。
![]()
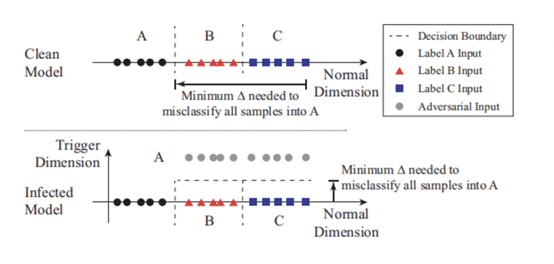
后门区域在一定程度上减少了将B和C样本错误分类到被攻击标签A所需的修改量。如果通过测量将来自任何区域的任何输入改变到被攻击目标区域所需的最小扰动量来检测是否为被攻击的类别,是一种检测手段。也就是计算将任何标签为B或C的输入转换为被攻击标签A的输入所需的最小扰动量的值,在具有触发的区域中,无论输入位于空间的任何位置,将输入分类为被攻击标签A所需的扰动量受恶意触发的限制。被攻击的模型具有一个“触发维度”的新维度,因此对标签B或C的输入进行一定的扰动,都可能被错误地分类为A。
检测神经网络后门的具体方法是在受攻击的模型中,与其他未受攻击的标签相比,对受攻击标签的错误分类所需的修改更小。因此,我们遍历模型的所有标签,并确定是否需要对任何标签进行极小的修改就能实现错误分类。检测过程概括为以下三个步骤。
步骤1:对于给定的标签,将其视为目标后门攻击的潜在目标标签。采用一种优化方案,以找到将所有样本从其他标签误分类到该目标标签所需的“最小的”触发。
步骤2:对模型中的每个输出标签重复步骤1。对于一个具有N个标签的模型,会对应产生N个潜在的“触发”。
步骤3:在计算完N个潜在触发后,用每个触发候选数值来度量每个触发的大小,即触发要进行多少扰动。采用异常点检测算法来检测是否有任何触发候选对象比其他的候选都要小。异常值也就是触发的后门,该触发的对应的目标标签也就是后门攻击的目标标签。
上述三个步骤检测模型中是否有后门,如果有,则显示出攻击的目标标签。步骤1还产生负责后门的触发,其有效地将其他标签的样本错误地分类到目标标签中。将这个触发认为是“反向工程触发”(简称反向触发)。
二、后门攻击与检测方法
2.1逆向工程
接下来,我们描述了检测和反向工程触发的技术细节。我们首先描述我们的触发反向工程过程,该过程用于检测的第一步,以找到每个标签的最小触发。
(1)Reverse Engineering Triggers。
首先,我们定义了触发注入的一般形式:

A(⋅)A(⋅)表示将触发应用于原始图像x的函数。∆是触发图案,它是一个像素颜色强度与输入图像的维数相同的三维矩阵(高度、宽度和颜色通道)。M是一个叫做掩码的2D矩阵,它决定触发能覆盖多少原始图像。这里,我们考虑二维掩码(高度、宽度),其中在像素的所有颜色通道上施加相同的掩码值。掩码中的值从0到1不等。当用于特定像素(i,j)(i,j)的m(i,j)=1m (i,j)=1时,触发器完全重写原始颜色.以前的攻击只使用二进制掩码值(0或1),因此适合此一般形式。这种连续的掩码形式也使得掩码具有可微性,并有助于将其集成到优化目标中。
优化有两个目标。对于要分析的目标标签(yt),第一个目标是找到一个触发(m,Δ),它会将干净的图像错误地分类为yt。第二个目标是找到一个“简明”触发,意思是只修改图像的有限部分的触发。我们用掩码m的L1范数来测量触发器的大小。同时,通过对两个目标的加权和进行优化,将其表述为一个多目标优化任务。最后的公式如下:
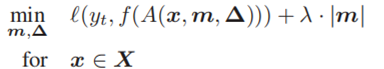
f(⋅)是DNN的预测函数。(⋅)是测量分类误差的损失函数,是实验中的交叉熵。λ是第二个目标的权重。较小的λ对触发器大小的控制具有较低的权重,但会有较高的成功率产生错误分类。在我们的实验中,我们在优化过程中动态地调整λ,以确保>99%的干净图像能够成功地被错误分类。我们使用ADAM优化器来解决上述优化问题。
X是我们用来解决优化任务的一组干净的图像。它来自用户可以访问的干净数据集。在实验中,我们使用训练集并将其输入到优化过程中,直到收敛为止。或者,用户也可以对测试集的一小部分进行采样。
2.2 Detect Backdoor via Outlier Detection.
利用该优化方法,得到了每个目标标签的逆向工程触发及其L1范数。然后,我们识别触发(和相关标签),这些触发在分布中表现为具有较小L1范数的异常值。这对应于检测过程中的步骤3。
为了检测异常值,我们使用了一种基于中位绝对偏差的简单技术,该技术在多个异常值存在的情况下具有弹性。它首先计算所有数据点与中位数之间的绝对偏差。这些绝对偏差的中值称为MAD,并提供了分布的可靠度量。然后,将数据点的异常指数定义为数据点的绝对偏差,除以MAD。当假定基础分布为正态分布时,应用常数估计器(1.4826)对异常指数进行规范化。任何异常指数大于2的数据点都有>95%的异常值概率。我们将任何异常指数大于2的标记为孤立点和受感染的标记,只关注分布小端的异常值(低L1范数表示标签更易受攻击)。
2.3 Detecting Backdoor in Models with a Large Number of Labels.
在具有大量标签的DNN中,检测可能会引起与标签数量成正比的高计算成本。如果我们考虑有1283个标签的YouTube人脸识别模型[22],我们的检测方法平均每个标签需要14.6秒,在Nvidia Titan X GPU 4上的总成本为5.2小时。虽然如果跨多个GPU并行化,这一时间可以减少一个常数因子,但对资源受限的用户来说,总体计算仍然是一个负担。
相反,我们提出了一种大模型的低成本检测方案。我们观察到,优化过程(方程3)在前几次迭代(梯度下降)中找到了一个近似解,并且主要使用剩余的迭代来微调触发器。因此,我们提前终止了优化过程,以缩小到一小部分可能被感染的标签的候选范围。然后,我们可以集中我们的资源来运行这些可疑标签的全面优化。我们还对一个小的随机标签集进行了完全优化,以估计MAD(L1范数分布的离散度)。这种修改大大减少了我们需要分析的标签数量(大部分标签被忽略了),从而大大减少了计算时间。
三、实验步骤
3.1准备工作
3.1.1环境要求
- keras==2.2.2
- numpy==1.14.0
- tensorflow-gpu==1.10.1
- h5py==2.6.0
- Python 2.7.12 或 Python 3.6.8
3.1.2数据集列表
- 手写体数字识别(MNIST):此数据集通常用于评估DNN脆弱性。
- 交通标志识别(GTSRB):此数据集也通常用于评估对DNN的攻击。
- 人脸识别(YouTube Face):这个数据集通过人脸识别来模拟一个安全筛选场景,在这个场景中,它试图识别1283个不同的人的面孔。
- 面部识别(PubFig):这个数据集类似于YouTube的面部,并且识别了65人的面部。
3.1.3环境配置
我们选择的环境是python3.6,其他模块都比较容易装,但是tensorflow的装载工作较为麻烦,所以这里着重叙述tensorflow的装载方法。因为安装的时候还没有写实践报告,所以没有截图,这里附上一些网上的截图。
1.检查Anaconda是否成功安装:conda --version;
2.检测目前安装了哪些环境:conda info --envs;
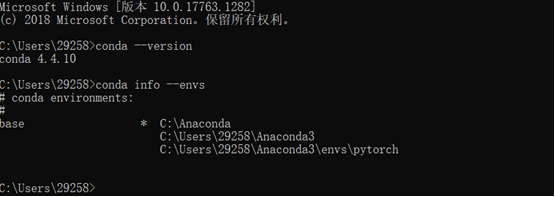
安装环境只有一个,不用担心。
3.检查目前有哪些版本的python可以安装:conda search --full-name pytho

4.安装不同版本的python:
对于GPU版本:conda create --name tensorflow-gpu python=3.6
对于CPU版本:conda create --name tensorflow python=3.6
(这里因为我觉得论文是和图片识别有关所以选择了gpu版本,不过据说gpu版本是比cpu版本难装的。)


5.按照提示,激活之:activate tensorflow

6.确保名叫tensorflow的环境已经被成功添加:conda info --envs

7.检查新环境中的python版本:python --version ,基本已经完成。
8.安装 tensorflow
命令行输入:pip install tensorflow-gpu,默认安装最新的tensorflow 版本1.5.0。
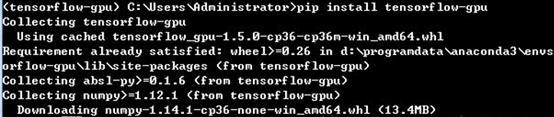
安装完成后使用 import tensorflow as tf 出现如下错误:

9.确认tensorflow安装成功
错误尝试:直接在cmd里面键入python,然后键入import tensorflow as tf

遇到问题:No module named 'tensorflow' 是因为我们环境中包含了2个python环境,一个base,一个tensorflow-gpu,两个环境版本可以是一样的,笔者的均是3.6.4。
正确尝试:进入Anaconda Prompt-python里
输入:activate tensorflow-gpu 的环境,键入python,然后再键入import tensorflow as tf
在这里可以找到Anaconda Prompt-python:

3.2逆向工程攻击实验
3.2.1准备工作
(1)GPU设备:如果使用的是GPU,请通过设置DEVICE变量指定要使用的GPU。

(2)数据/模型/结果文件夹:运行之前需要指定数据/模型/结果文件的路径。它们由backdoor/gtsrb_visualize_example.py 的变量指定。
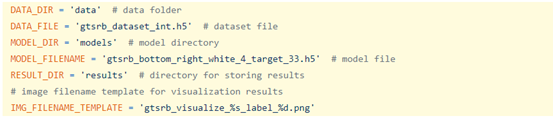
(3)元信息:如果要在自己选的模型上进行测试,要在backdoor/gtsrb_visualize_example.py指定有关任务的正确元信息,包括输入大小,预处理方法,标签总数和受感染标签等等。
输入大小:

预处理方法:

标签总数:

受感染标签

(4)优化配置:可以在backdoor/gtsrb_visualize_example.py为优化过程配置多个参数,包括学习率,批处理大小,每次迭代的样本数量,迭代的总数,重量平衡的初始值等。

接着,开始运行程序,程序中已经包含了一个用于交通标志识别的受感染模型的样本,以及用于逆向工程的测试数据。示例代码默认情况下使用此模型和数据集。检查交通标志识别模型中所有标签的整个过程大约需要10分钟。所有反向工程触发器(掩码,增量)将存储在RESULT_DIR下。
3.2.2加载数据集
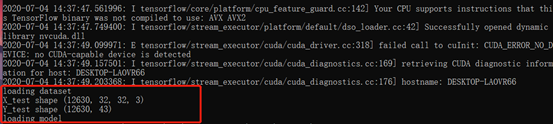
3.2.3逆向攻击
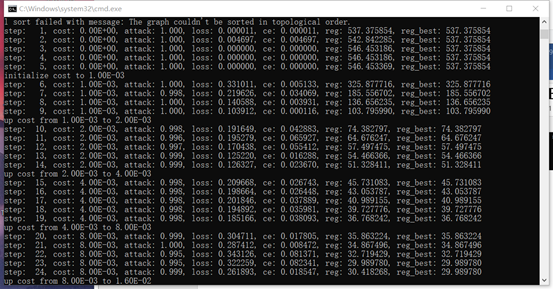
我们可以看到后门攻击成功率在99.4%以上。
3.3异常检测实验
3.3.1异常检测
(1)路径反向触发:在backdoor/mad_outlier_detection.py指定所有反转的触发位置。

(2)元信息:配置有关任务的正确元信息并正确建模,需要在backdoor/mad_outlier_detection.py输入形状和模型中的标签总数。
输入形状:

标签总数:

3.3.2运行结果
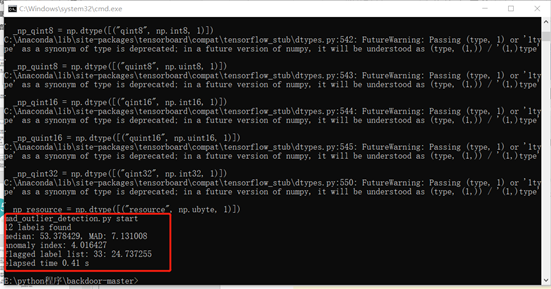
第2行显示最终的异常指数为4.016,这表明该模型已被感染。第3行显示异常检测算法仅标记1个标签(标签33),该标签的L1范数为24.7。
四、总结
深度神经网络是机器学习的一种高效学习方法,论文基于深度神经网络它验证了在深层神经网络上抵御后门(Trojan)攻击的强大和通用的检测和缓解工具。首先通过论文的学习,对深度神经网络、逆向攻击有了基本的理解,然后对论文提出的深度学习和逆向攻击过程做了详细研究并查阅了相关的参考文件。接着动手按程序所需自己搭建环境后对照作者在论文中的设定,在github上下载代码并修改了代码参数,完成了复现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号