

不确定估计学习小结
最近,观看了危夷晨大佬关于《不确定性学习在视觉识别中的应用》的报告,认为不确定性学习在用武之地,所以特意对相关论文进行了总结。
什么是不确定性估计
以人脸识别为例,输入一张人脸图像,得到一个特征向量embedding,将此特征向量与底库中的特征向量计算相似度,从而根据此相似度来判断两张人脸图像是否属于同一个ID。假设相似度很高(95%),则认为这两张人脸图像属于同一个人。这种将一张输入图像x映射到高维空间中的一个点embedding的方式,可以被称为确定性预测(deterministic prediction)。
但以同样的人脸系统、相同的底库来看,假设我们输入一张很模糊的人脸或者一张猫的图片,此时系统可能会给出同样是95%的相似度。然而,在这种情形下,这种相似度得分并不能反映出两张图片是属于同一ID的,即这个相似度结果不可信。因此,我们不仅需要一个相似度得分,还需要一个能判断此相似度是否可信的得分。具体而言,假设在此种情形下,即使两种图片的相似度得分是95%,但只有10%的得分认为该相似度得分可行,那么做出判断就需要更加谨慎。

再举一个例子,假设我们使用了cifar100来训练了一个分类模型,现在用户随意找了张不属于此100类的图片(例如猫),输入到该分类模型中,那么这个“猫”必然会分类到cifar100中的其中一个类别,例如认为是飞机。从模型来看,这个分类置信度得分可能很高,坚定认为这个“猫”就是“飞机”;从人的认识来看,此次分类结果是失败的。面对这种情况,我们希望模型不仅能给出分类的置信度得分,还希望模型能给出一个判断此次置信度得分是否可信的判断。这种情况,有点类似out-of-distribution(离群点检测)或者异常检测等。
从上面几个案例来看,无论是相似度得分还是置信度得分,都不一定可信,即模型对于给出的判断具有一定程度的“不确定性”。那么,我们就希望知道模型对于此次判断有多少把握,对于“不确定性”得分高的判断(即把握度低),我们可以进行额外的处理操作。
两种不确定性
一般而言,不确定性可以分类两种[2]:
1.数据的不确定性:也被称为偶然(Aleatoric)不确定性,它描述的是数据中内在的噪声,即无法避免的误差,这个现象不能通过增加采样数据来削弱。例如有时候拍照的手稍微颤抖画面便会模糊,这种数据是不能通过增加拍照次数来消除的。因此解决这个问题的方法一般是提升数据采集时候的稳定性,或者提升衡量指标的精度以囊括各类客观影响因素。
2.模型的不确定性:也被称为认知(Epistemic)不确定性。它指出,模型自身对输入数据的估计可能因为训练不佳、训练数据不够等原因而不准确,与某一单独的数据无关。因此,认知不确定性测量的,是训练过程本身所估计的模型参数的不确定性。这种不确定性是可以通过有针对性的调整(增加训练数据等方式)来缓解甚至解决的。
模型不确定性
对于深度学习模型而言,其权重是固定的,所以,对某个样本而言,输出类别也是固定的。那我们该如何引入不确定性呢?主要的方式是贝叶斯神经网络BNN和模型融合。
贝叶斯神经网络BNN
在BNN网络中,认为每一个权重$W_i$和偏置$b$不再是某个具体的数值,而是一个概率分布。在训练与推理阶段,需要对每个权重$W_i$和偏置$b$进行采样,得到一组参数,然后像非贝叶斯神经网络那样进行使用即可。
通过这种方法可以建模各个参数本身存在的不确定性。但是由于在实际应用中参数量十分巨大,要严格根据贝叶斯公式计算后验概率几乎不现实,因此为了将网络应用于大型数据集,就需要高效的近似计算方法。
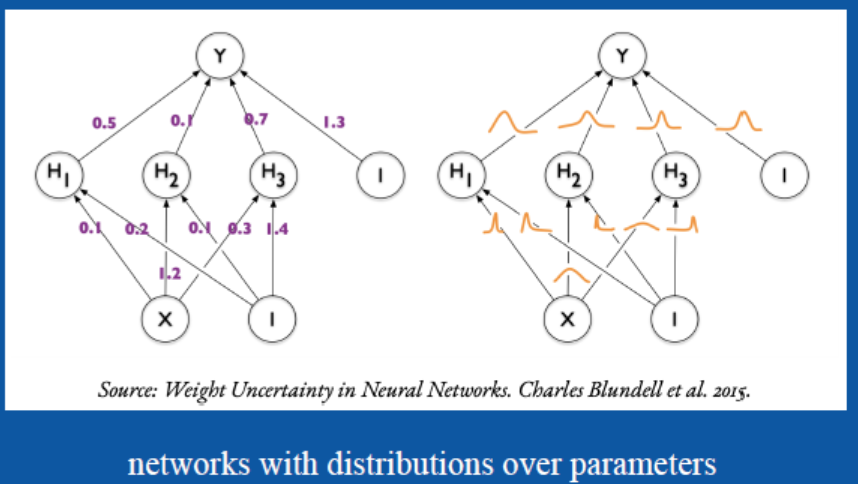
给定一个训练集$D={(x_1,y_1),(x_2,y_2),...,(x_m,y_m)}$,那么贝叶斯公式可以写成如下形式:
$$p(w|x,y)=\frac{p(y|x,w)p(w)}{\int p(y|x,w)p(w)dw} \tag{1}$$
其中,我们想要得到的是$w$的后验概率$p(w|x,y)$,先验概率$p(w)$是我们可以根据经验也好瞎猜也好是知道的,例如初始时将$p(w)$设成标准正态分布,似然$p(y|x,w)$是一个关于$w$的函数。当$w$等于某个值时,式$(1)$的分子很容易就能算出来,但我们想要得到后验概率$p(w|x,y)$,按理还要将分母算出来。但事实是,分母这个积分要对$w$的取值空间上进行,我们知道神经网络的单个权重的取值空间可以是实数集$R$,而这些权重一起构成的空间将相当复杂,基本没法积分。所以问题就出现在分母上[1]。
因此,通常有三种解决方法:
- 马尔科夫链蒙特卡洛采样法(MCMC-sampling)。用MCMC方式来近似分布的积分;
- 变分推断。直接用一个简单点的分布$q$去近似后验概率的分布$p$,即不管分母怎么积分,直接最小化分布$q$和$p$之间的差异,如可以使用KL散度计算;
- 蒙特卡洛dropout。这个是近年来运用比较多的方式。可以直观理解标准神经网络经过dropout之后,在每一层随机取消一些神经元,把连接变稀疏的网络。可以证明,在假设每一个神经元都服从一个离散的伯努利分布的情况下,经dropout方法处理的神经网络的优化过程实际上等价于在一个贝叶斯网络中进行变分推断。在推理时,也需要打开dropout,并且推理时需要多次对同一输入进行前向传播,然后可以计算平均和统计方差。
模型融合
其大致思路是对一个数据集D进行多次随机采样,得到N个不同的数据集。使用这N个不同的数据集来N个模型,由于数据集不同,所以这N个模型也不一样。最终对这N个不同模型的推理结果进行综合,其均值可以作为预测结果,方差可以作为不确定性。
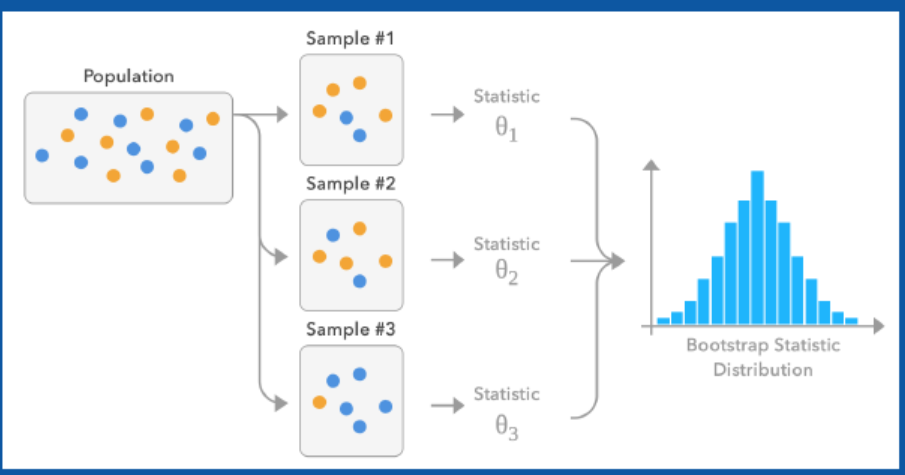
上述两种方法在工程实现上都存在着严重的问题,通过蒙特卡洛dropout的话,需要对同一输入进行多次推理;通过模型融合的话,需要经过多个模型。无论在显存占用或者推理时间上,都难以接受。
数据不确定性
直接预测不确定性
在论文《Learning Confidence for Out-of-Distribution Detection in Neural Networks》中,提出了一种新的方法:直接学习神经网络中的置信度估计。如下图所示,在模型的输出处,不仅输出类别置信度,还输出置信度估计(经过sigmoid后,范围在$[0,1]$)。用此置信度估计来判断类别概率是否可信,这个置信度估计的阈值设定应该是一个经验值。
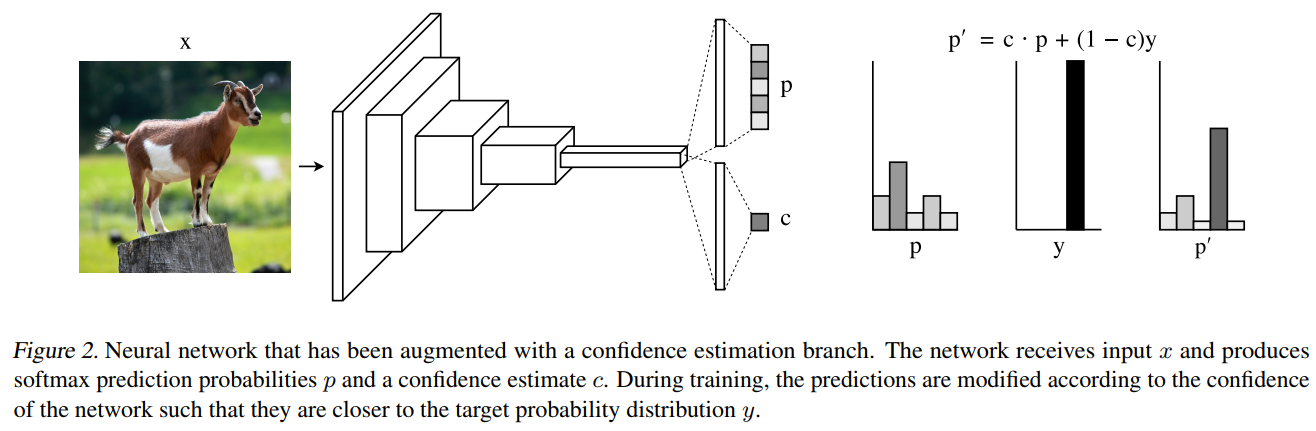
具体而言,需要将类别概率$p$与置信度估计$c$进行融合,得到${p}'=c\cdot p+(1-c)y$。然后此${p}'$来进行损失计算。当$c$接近于1时,表示对此类别概率有很强的把握,因此${p_i}'$接近于$p$;当$c$接近于1时,表示对此类别概率不太确定,因此${p_i}'$接近于$y$,且$log(c)$的值会占主导。
$$L=L_t+\lambda L_c=-\sum _{i=1}^Mlog({p_i}')y_i-log(c) \tag{2}$$
此方法思想和做法都很简单,同时也取得了很不错的效果。
PFE
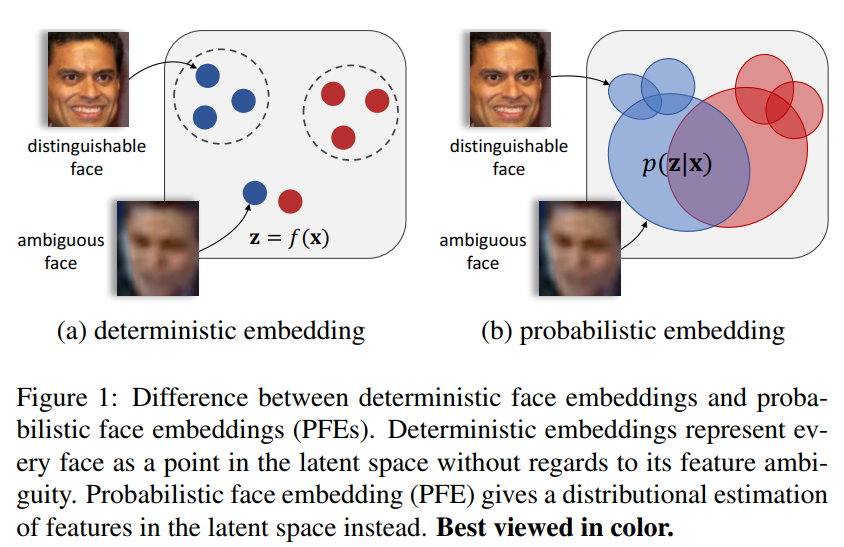
该方法出自于论文《Probabilistic Face Embeddings》中,其核心思想是,用概率分布来代替传统的embedding特征。PFE引入了不确定性,认为输出向量是一个概率分布,具有均值$\mu $和方差$\sigma $,而不再是确定的向量。如下图所示,左图传统的方法,预测出来的embedding是固定的数值,其会带来一个问题:如果输入图片比较模糊,那么该图像对应的embedding可能会发生偏移,产生错误识别;右图是PFE的方法,认为网络预测出来的特征是一个分布(椭圆形),均值代表图像的embedding,方差描述了模型对输入的不确定度。该方法希望同时估计$\mu $和$\sigma $,并且$\sigma $能够根据输入图像的质量、包含噪声的程度进行自适应的学习。
文中给出了一个在人脸识别中的例子,如下图所示,(a)表示同一ID,但相似度较低的图片,可以看出,其主要原因是姿态过大,遮挡或者模糊;(b)是不同ID,但相似度很高的图片。

其具体的做法也比较简单,基于原有的人脸识别系统,固定其不变化,认为embedding就是均值$\mu $;同时新增一个分支,用于预测方差$\sigma $;最后使用一个新的计算相似度的方法mutual likelihood score(MLS):
$$s(x_i,x_j)=-\frac{1}{2}\sum_{l=1}^{D}\left ( \frac{(\mu _i^{(l)}-\mu _j^{(l)})^2}{\sigma _i^{2(l)}+\sigma _j^{2(l)}} +log\left ( \sigma _i^{2(l)}+\sigma _j^{2(l)} \right )\right )-const \tag{3}$$
论文中给出了一个使用传统余弦相似度和MLS的对比图,如下图所示。蓝色线条表示对两张相同图片中的一张图片施加高斯模糊后,两张图片的相似度变化;红色线条表示对两张不同的图片共同使用高斯模糊后,两张图片的相似度变化。左图是传统方法和利用余弦相似度的结果,随着模糊程度增加,相同图片的相似度越来越低,不同ID的图片的相似度越来越高,表明模糊图片很容易误识别成另外一个ID;右图是PFE方法和利用MLS计算距离,可以看到随着模糊程度增大,相同图片的距离不会变得很小,不同ID的图片的距离也不会变得很大,表明PFE的方法对于低质量的图片更具有优势。

但是,PFE依然存在以下不足:
- 需要额外存储方差信息;
- MLS计算比较复杂;
- 数据的不确定性并没有真正用于影响模型中特征的学习。
对于PFE,我还存在一点疑问:对于封闭场景而言,注册照一般是高清图片。如果用模糊图片来进行识别,当然是希望模糊图片与高清图片的相似度尽可能为0,这样能降低误识别的风险。如果用PFE来处理这种封闭场景的话,一方面会降低识别率,同时也会增加误识别的风险。所以,PFE这种方式一般是适合公开场景?图片较为模糊的场景?
DUL
DUL方法出自旷视的《Data Uncertainty Learning in Face Recognition》。DUL的工作是基于PFE进行改进的,使得网络同时能优化均值和方。如下图的(c)所示,模型会预测概率分布,同一ID之间的样本的均值的距离会靠近,不同ID之间的样本的均值的距离会拉开。
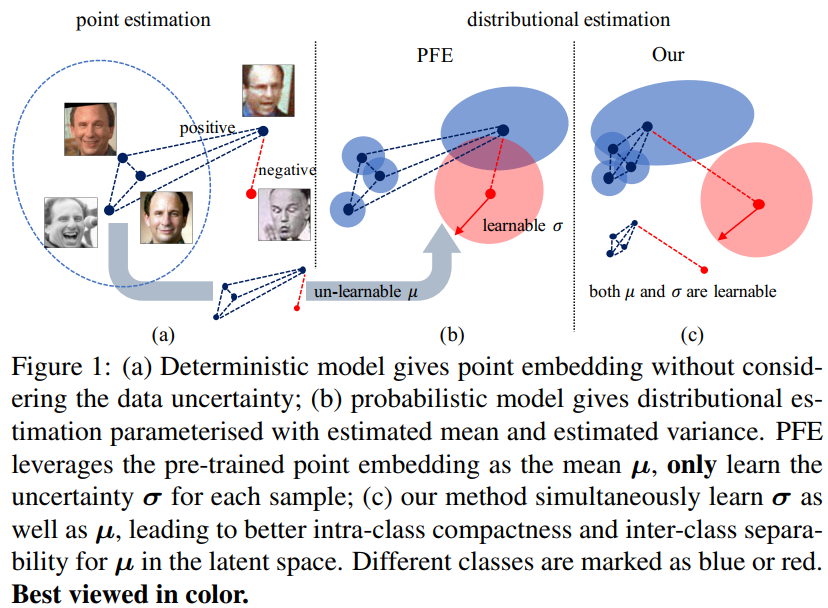
在论文中,使用了两种方法来实现这个原理:基于分类的和基于回归的。
- 基于分类的DUL
如下图所示,在模型的backbone后会有两条分支,分别用于预测均值$\mu $和方差$\sigma $。对于每个样本的每一次迭代而言,都随机采样一个$\epsilon $。通过这种方式得到的新样本特征$s_i=\mu _i+\epsilon \sigma _i$就是遵从均值$\mu $、方差为$\sigma $的高斯分布采出的值,它可以模拟一个服从高斯分布的特征。通过这种简单的重新采样的技巧,就可以很好进行模型训练。在测试的时候不再需要采样,仅需要将已经得到的均值$\mu $作为特征来计算相似度即可。
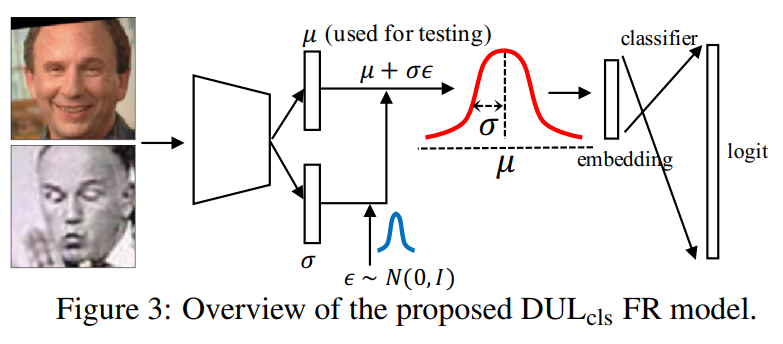
同时,损失函数也进行了相应的修改:
$$L_{cls}=L_{softmax}+\lambda L_{kl}=\frac{1}{N}\sum _i ^N-log\frac{e^{w_{y_i}s_i}}{\sum _c ^C e^{w_cs_i}}-\frac{1}{2}(1+log\sigma ^2-\mu ^2-\sigma ^2) \tag{4}$$
当不确定度$\sigma $较小时,$L_{kl}$就会增加;当$\sigma $较大时,会对$\mu $造成较大影响,从而使$L_{softmax}$增加。因此较大的$\sigma $对应着质量较差的图片,较小的$\sigma $对应着高质量的图片。
- 基于回归的DUL
如下图所示,利用一个已经训练好的人脸识别系统,冻结其backbone,利用其分类层中的权重矩阵$W$,其中,$w\in \mathbb{R}^{D\times C}$,$w_i\in w$可以被认为相同类别的embedding的中心。后续步骤与基于分类的DUL一致,然后新训练两条分支,一条分支用于预测均值 ,回归$w_c$的样本类中心;另一条分支用于预测方差。
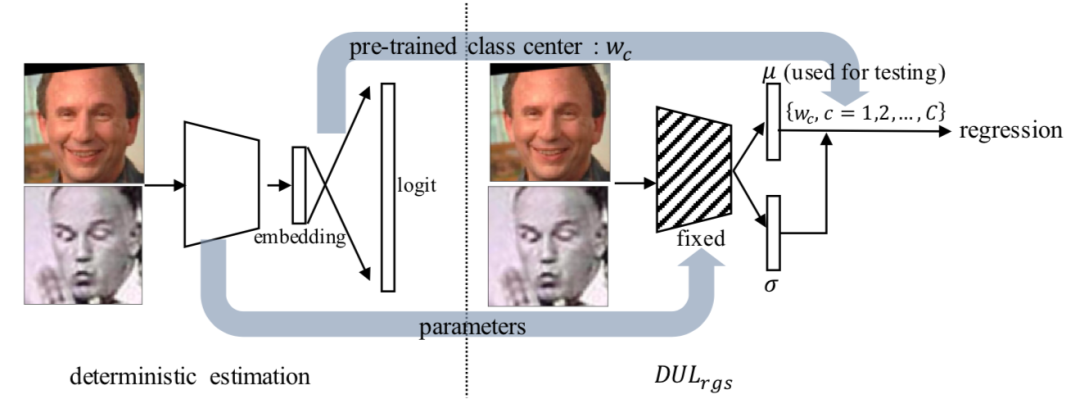
同时,损失函数变为了:
$$L_{reg}=-\frac{1}{N}\sum_{i}^{N}\left ( \frac{\left ( w_c-\mu _{i\in c} \right )^2}{2\sigma _i^2}+\frac{1}{2}ln\sigma _i^2+\frac{1}{2}ln2\pi \right ) \tag{5}$$
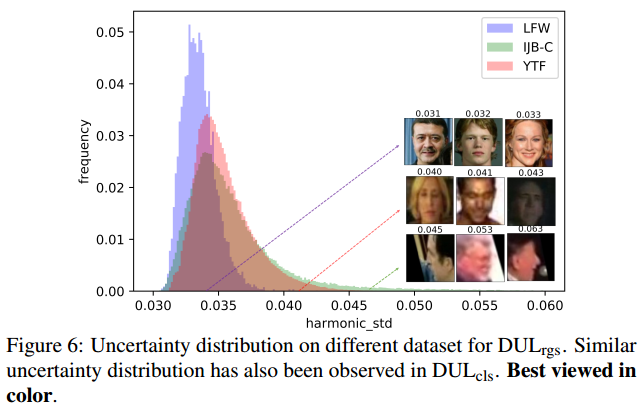
DUL方法在图片质量不是特别高的情况,效果会优于其他方式。但通篇论文看完,存在点小疑问:预测出来的方差$\sigma $应该是一个可以运用的信息,但文中只给出利用方差构成的调和平均数示意图,如下图所示。或许方差可以用于对抗性场景,例如假脸攻击,out-of-distribution检测。
综上所述,在计算机视觉中引入不确定估计,让我们知道模型对于预测结果的把握程度,对可信AI系统有一定帮助,同时也能有助于提高面向公开场景的模型的性能。但是该理论发展还不够迅速,还存在很多疑问,感觉使用起来不是特别广泛,这方面的论文还是值得持续关注。
参考资料:
- 贝叶斯深度学习(bayesian deep learning)
- R TALK | 旷视危夷晨:不确定性学习在视觉识别中的应用
- CVPR 2020 | 旷视研究院提出数据不确定性算法 DUL,优化人脸识别性能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号