

第一次个人编程作业
前言
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024/homework/13136 |
|---|---|
| 这个作业的目标 | 完成论文查重系统 |
1.github链接:https://github.com/LooooooooJ/3221003139/tree/main
2.PSP表格:
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| Estimate | 估计这个任务需要多少时间 | 2240 | 2110 |
| Development | 开发 | 1200 | 1000 |
| Analysis | 需求分析 (包括学习新技术) | 240 | 360 |
| Design Spec | 生成设计文档 | 60 | 30 |
| Design Review | 设计复审 | 30 | 25 |
| Coding Standard | 代码规范 | 30 | 30 |
| Design | 具体设计 | 60 | 40 |
| Coding | 具体编码 | 200 | 240 |
| Code Review | 代码复审 | 60 | 50 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 80 |
| reporting | 报告 | 90 | 90 |
| Test Report | 测试报告 | 60 | 80 |
| Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 50 |
| 总计 | 2240 | 2095 |
3.计算模块接口的设计与实现过程
考虑使用simHash算法,此算法共有5个步骤:分词、hash、加权、合并、降维。
-
关键函数
main.py里有四个函数:
1.def splitWords(text) —— 分词
2.def getSimh(s) —— hash、加权、合并、降维
3.def getSimilarity(simh1, simh2) —— 计算海明距离和相似度
4.def test()
simHash算法:首先文本的内容经过splitWords函数进行分词操作,之后getSimh函数计算分词过后文本的hash值,并进行加权、合并和降维操作,最后通过调用getSimilarity函数,其中以getSimh处理过后的hash值作为传参,得到海明距离,从而计算出相似度。
simHash算法的独特之处在于,相较于其他传统的hash算法,simHash算法计算出两个文本之间的hash值差距比较小,这样能够
更加精确的计算出文本之间的相似度。
-
simhash算法的代码实现:
点击查看代码
def getSimh(s):
i = 0
weight = len(s)
fv = [0] * 128 # feature vector
for word in s: # 计算各个特征向量的hash值
m = hashlib.md5() # 获取一个md5加密算法对象
m.update(word.encode("utf-8"))
hashc = bin(int(m.hexdigest(), 16))[2:] # 获取加密后的二进制字符串,并去掉开头的'0b'
if len(hashc) < 128: # hash值需在低位以0补齐128位
dif = 128 - len(hashc)
for d in range(dif):
hashc += '0'
for j in range(len(fv)): # 给所有特征向量进行加权
if hashc[j] == '1': # 合并特征向量的加权结果
fv[j] += (10 - (10 * i / weight))
else:
fv[j] -= (10 - (10 * i / weight))
i += 1
simh = ''
for k in range(len(fv)): # 降维
if fv[k] >= 0: # 对于n-bit签名的累加结果,大于0则置1,否则置0
simh += '1'
else:
simh += '0'
return simh
-
命令行测试
格式:python main.py [原文文件] [抄袭版论文的文件] [答案文件]

4.性能分析及改进
- 性能分析
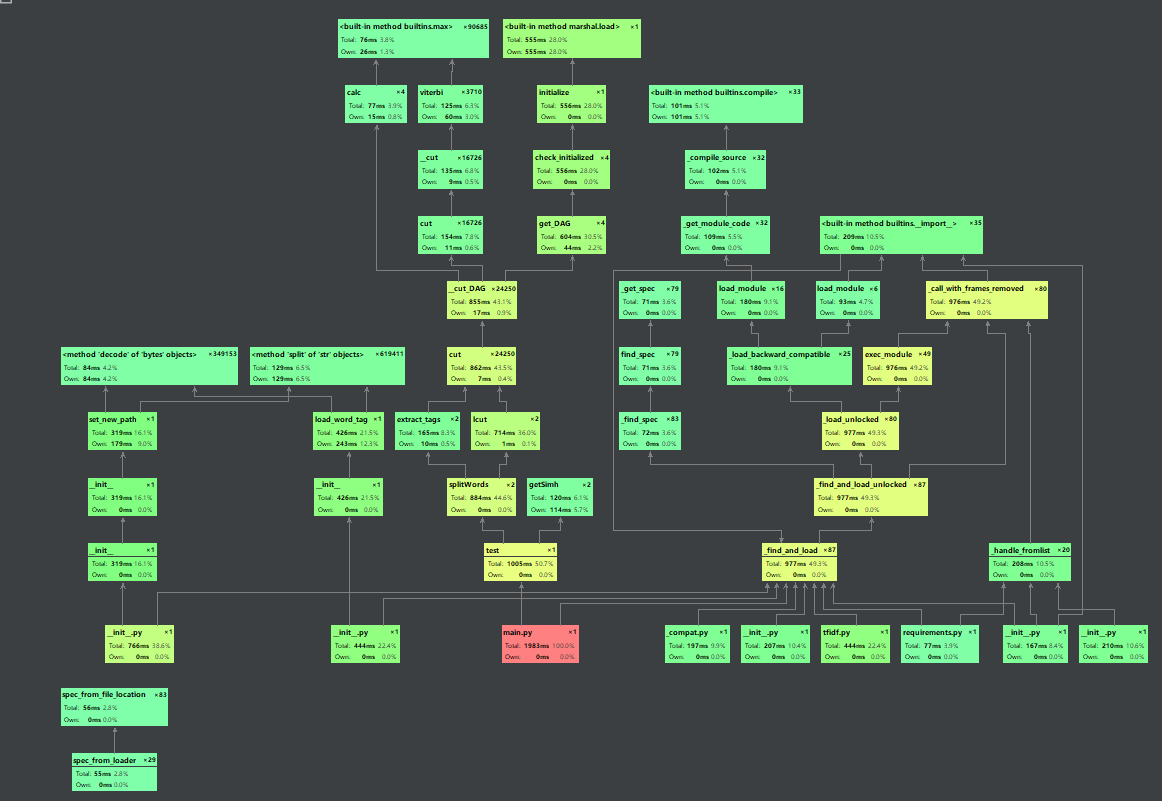
使用pycharm自带的profile方法进行性能分析
![]()
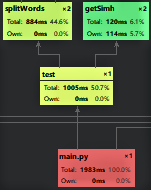
- 性能改进
![]()
可以看出splitWords函数耗时较多,故用正则表达式匹配过滤对其改进。 - 原始代码:
点击查看代码
def splitWords(text):
with open(text, 'r', encoding='UTF-8') as f1:
f2 = f1.read()
f1.close()
length = len(list(jieba.lcut(f2)))
s = jieba.analyse.extract_tags(f2, topK=length)
return s
- 改进代码:
点击查看代码
def splitWords(text):
with open(text, 'r', encoding='UTF-8') as f1:
f2 = f1.read()
pattern = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]")
s = pattern.sub("", f2)
f1.close()
length = len(list(jieba.lcut(s)))
string = jieba.analyse.extract_tags(s, topK=length)
return string
5.单元测试
- 为了方便测试,将test函数修改为:
点击查看代码
def test():
+ eventlet.monkey_patch()
+ with eventlet.Timeout(5, False):
+ time.sleep(10)
+ input()
path1 = ','.join(sys.argv[1:2])
path2 = ','.join(sys.argv[2:3])
path3 = ','.join(sys.argv[3:])
+ if not os.path.exists(path1):
+ print("论文原文不存在!")
+ exit()
+ if not os.path.exists(path2):
+ print("抄袭论文不存在!")
+ exit()
simhash1 = getSimh(splitWords(path1))
simhash2 = getSimh(splitWords(path2))
s1 = getSimilarity(simhash1, simhash2)
s2 = round(s1, 2)
print('文章相似度为:%f' % s2)
with open(path3, 'a', encoding='utf-8')as f:
f.write(path2 + '与原文的相似度为:')
f.write(json.dumps(s2, ensure_ascii=False) + '\n')
return s2
- 新建单元测试文件test.py
点击查看代码
import unittest
from main import test
class MyTestCase(unittest.TestCase):
def test_something1(self):
self.assertEqual(test(), 0.70)
def test_something2(self):
self.assertEqual(test(), 0.71)
def test_something3(self):
self.assertEqual(test(), 0.79)
def test_something4(self):
self.assertEqual(test(), 0.65)
def test_something5(self):
self.assertEqual(test(), 0.55)
if __name__ == '__main__':
unittest.main()
- 测试结果
6.参考文献
- 相似度算法——SimHash算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号