[04] 高级映射 association和collection
之前我们提到的映射,都是简单的字段和对象属性一对一,假设对象的属性也是一个对象,即涉及到两个表的关联,此时应该如何进行映射处理?
先看两张表,author 和 book:
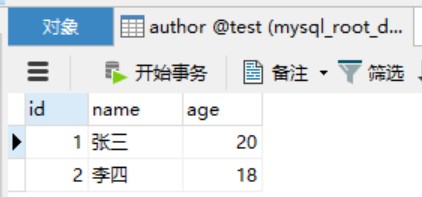
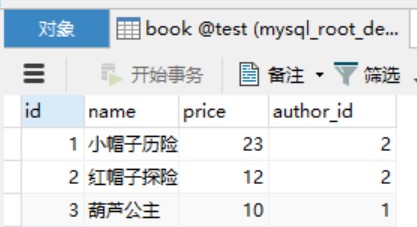
业务上对应关系为,一个作者能写多本书,但是一本书只有一个作者。对应的Java类如下:
public class Book {
private long id;
private String name;
private int price;
private Author author;
//... getter and setter
}8
1
public class Book {2
private long id;3
private String name;4
private int price;5
private Author author;6
7
//... getter and setter8
}public class Author {
private long id;
private String name;
private int age;
private List<Book> bookList;
//... getter and setter
}8
1
public class Author {2
private long id;3
private String name;4
private int age;5
private List<Book> bookList;6
7
//... getter and setter8
}1、association 关联
现在我们希望通过查询得到一个Book类,且该类中的author属性要求同时获取出来,这时候已经不是简单的数据库字段和对象属性的一对一映射,而涉及到两张表,此时我们就要用到 association 关键字。
association 表示一个复杂类型的关联,可以将许多结果包装成这种类型。它是 resultMap 中的标签属性,这意味着当你需要使用嵌套查询返回结果,那么你的结果映射只能选择 resultMap,而不能再使用 resultType。
1.1 method1
使用起来和resultMap的基本结构无异,所以如上我们提到的查询需求,在mapper中可以这样写:
<mapper namespace="dulk.learn.mybatis.dao.BookDao">
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">
<id property="id" column="id" />
<result property="name" column="name" />
<result property="price" column="price" />
<!--关联属性-->
<association property="author" javaType="dulk.learn.mybatis.pojo.Author">
<!--注:此处column应为book中外键列名-->
<id property="id" column="author_id" />
<!--注:避免属性重名,否则属性值注入错误-->
<result property="name" column="authorName" />
<result property="age" column="authorAge" />
</association>
</resultMap>
<!--嵌套查询,结果映射只能使用resultMap-->
<select id="findBookById" parameterType="long" resultMap="bookResultMap">
SELECT
b.*,
a.name AS 'authorName',
a.age AS 'authorAge'
FROM book b, author a
WHERE b.author_id = a.id
AND b.id = #{id}
</select>
</mapper>28
1
<mapper namespace="dulk.learn.mybatis.dao.BookDao">2
3
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">4
<id property="id" column="id" />5
<result property="name" column="name" />6
<result property="price" column="price" />7
<!--关联属性-->8
<association property="author" javaType="dulk.learn.mybatis.pojo.Author">9
<!--注:此处column应为book中外键列名-->10
<id property="id" column="author_id" />11
<!--注:避免属性重名,否则属性值注入错误-->12
<result property="name" column="authorName" />13
<result property="age" column="authorAge" />14
</association>15
</resultMap>16
17
<!--嵌套查询,结果映射只能使用resultMap-->18
<select id="findBookById" parameterType="long" resultMap="bookResultMap">19
SELECT20
b.*,21
a.name AS 'authorName',22
a.age AS 'authorAge'23
FROM book b, author a24
WHERE b.author_id = a.id25
AND b.id = #{id}26
</select>27
28
</mapper>可以看到 association 最基本的两个属性:
- property - 关联对象在类中的属性名(即Author在Book类中的属性名,author)
- javaType - 关联对象的Java类型
而association中的结构,则和resultMap无异了,同样是id和result,但是仍然有两个需要注意的点:
- id中的column属性,其值应该尽量使用外键列名,主要是对于重名的处理,避免映射错误
- 同样的,对于result中的column属性的值,也要避免重名带来的映射错误,如上例若 a.name 不采用别名 "authorName",则会错误地将 b.name 赋值给Author的name属性
1.2 method2
之前有提到,说 association 中结构和resultMap无异,事实上我们也可以直接引用其他的resultMap,如下(注意修改id别名):
<mapper namespace="dulk.learn.mybatis.dao.BookDao">
<!--author的resultMap-->
<resultMap id="authorResultMap" type="dulk.learn.mybatis.pojo.Author">
<id property="id" column="authorId"/>
<result property="name" column="authorName"/>
<result property="age" column="authorAge"/>
</resultMap>
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="price" column="price"/>
<!--引用author的resultMap-->
<association property="author" resultMap="authorResultMap" />
</resultMap>
<!--注意这里a.id的别名和authorResultMap中相对应-->
<select id="findBookById" parameterType="long" resultMap="bookResultMap">
SELECT
b.*,
a.id AS 'authorId',
a.name AS 'authorName',
a.age AS 'authorAge'
FROM book b, author a
WHERE b.author_id = a.id
AND b.id = #{id}
</select>
</mapper>29
1
<mapper namespace="dulk.learn.mybatis.dao.BookDao">2
3
<!--author的resultMap-->4
<resultMap id="authorResultMap" type="dulk.learn.mybatis.pojo.Author">5
<id property="id" column="authorId"/>6
<result property="name" column="authorName"/>7
<result property="age" column="authorAge"/>8
</resultMap>9
10
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">11
<id property="id" column="id"/>12
<result property="name" column="name"/>13
<result property="price" column="price"/>14
<!--引用author的resultMap-->15
<association property="author" resultMap="authorResultMap" />16
</resultMap>17
18
<!--注意这里a.id的别名和authorResultMap中相对应-->19
<select id="findBookById" parameterType="long" resultMap="bookResultMap">20
SELECT21
b.*,22
a.id AS 'authorId',23
a.name AS 'authorName',24
a.age AS 'authorAge'25
FROM book b, author a26
WHERE b.author_id = a.id27
AND b.id = #{id}28
</select>29
</mapper>1.3 method3
最后,还有一种方式,就是我们先查询出author,再将其放到book中去,相当于查询语句分为两次,只是最终结果交给MyBatis来帮我们组装,这种方式利用了 association 的 select 属性,同时还需要另写 author 的查询sql,book 的查询sql也可以不用再联表。这种方式相当于两次查询,性能和效率较低,并不提倡。如上例使用这样的方式,则如下:
<mapper namespace="dulk.learn.mybatis.dao.BookDao">
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="price" column="price"/>
<!--使用select属性进行查询关联-->
<association property="author" column="author_id" javaType="dulk.learn.mybatis.pojo.Author" select="findAuthorById"/>
</resultMap>
<!--简化了book的查询语句,不再需要与其他表关联-->
<select id="findBookById" parameterType="long" resultMap="bookResultMap">
SELECT b.*
FROM book b
WHERE b.id = #{id}
</select>
<!--新增了author表的查询语句,将会被调用获取结果并组装给book-->
<select id="findAuthorById" parameterType="long" resultType="dulk.learn.mybatis.pojo.Author">
SELECT *
FROM author
WHERE id = #{id}
</select>
</mapper>25
1
<mapper namespace="dulk.learn.mybatis.dao.BookDao">2
3
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">4
<id property="id" column="id"/>5
<result property="name" column="name"/>6
<result property="price" column="price"/>7
<!--使用select属性进行查询关联-->8
<association property="author" column="author_id" javaType="dulk.learn.mybatis.pojo.Author" select="findAuthorById"/>9
</resultMap>10
11
<!--简化了book的查询语句,不再需要与其他表关联-->12
<select id="findBookById" parameterType="long" resultMap="bookResultMap">13
SELECT b.*14
FROM book b15
WHERE b.id = #{id}16
</select>17
18
<!--新增了author表的查询语句,将会被调用获取结果并组装给book-->19
<select id="findAuthorById" parameterType="long" resultType="dulk.learn.mybatis.pojo.Author">20
SELECT *21
FROM author22
WHERE id = #{id}23
</select>24
25
</mapper>2、collection 集合
有了对 association 的认识,使用 collection 其实也就无非是依葫芦画瓢了,同样只能是 resultMap,同样需要注意列名重复的问题,同样可以引用resultMap或者使用select。下面索性直接看个例子吧,即获取一个Author作者,其中包含属性 List<Book>:
<mapper namespace="dulk.learn.mybatis.dao.AuthorDao">
<resultMap id="authorResultMap" type="dulk.learn.mybatis.pojo.Author">
<id property="id" column="id"/>
<result property="name" column="name" />
<result property="age" column="age" />
<!--使用collection属性,ofType为集合内元素的类型-->
<collection property="bookList" ofType="dulk.learn.mybatis.pojo.Book" columnPrefix="book_">
<id property="id" column="id"/>
<result property="name" column="name" />
<result property="price" column="price" />
</collection>
</resultMap>
<select id="findById" parameterType="long" resultMap="authorResultMap">
SELECT a.*, b.id AS 'book_id', b.name AS 'book_name', b.price AS 'book_price'
FROM author a, book b
WHERE a.id = b.author_id
AND a.id = #{authorId}
</select>
</mapper>22
1
<mapper namespace="dulk.learn.mybatis.dao.AuthorDao">2
3
<resultMap id="authorResultMap" type="dulk.learn.mybatis.pojo.Author">4
<id property="id" column="id"/>5
<result property="name" column="name" />6
<result property="age" column="age" />7
<!--使用collection属性,ofType为集合内元素的类型-->8
<collection property="bookList" ofType="dulk.learn.mybatis.pojo.Book" columnPrefix="book_">9
<id property="id" column="id"/>10
<result property="name" column="name" />11
<result property="price" column="price" />12
</collection>13
</resultMap>14
15
<select id="findById" parameterType="long" resultMap="authorResultMap">16
SELECT a.*, b.id AS 'book_id', b.name AS 'book_name', b.price AS 'book_price'17
FROM author a, book b18
WHERE a.id = b.author_id19
AND a.id = #{authorId}20
</select>21
22
</mapper>另外延伸一下关于避免字段重名的方式,如上例 select 中,列名的别名都增加了前缀 "book_",那么在collection中进行映射描时,就有两种方式:
- 第一种即 column 的值和列名完全一致,如 column="book_id"
- 第二种也就是推荐的方式,在 collection 中使用属性 columnPrefix 来定义统一前缀,在接下来的 column 中就可以减少工作量了,如上例中 columnPrefix = "book_",column = "id",它们的效果等同于 column = "book_id"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号