
数据采集与融合技术第三次作业
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
代码逻辑:
点击查看代码
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
ID = "152301219"
PAGE_LIMIT = int(ID[-2:]) # 19 页
IMG_LIMIT = int(ID[-3:]) # 219 张
BASE_URL = "http://www.weather.com.cn"
START_URL = "http://www.weather.com.cn/"
SAVE_DIR = "single_thread_images"
os.makedirs(SAVE_DIR, exist_ok=True)
def fetch_page(url):
try:
resp = requests.get(url, timeout=5)
resp.encoding = resp.apparent_encoding
return resp.text
except:
return ""
def extract_images(html, base_url):
soup = BeautifulSoup(html, "html.parser")
imgs = []
for img in soup.find_all("img"):
src = img.get("src")
if src:
imgs.append(urljoin(base_url, src))
return imgs
def download_image(url, idx):
try:
ext = url.split(".")[-1][:4]
filename = os.path.join(SAVE_DIR, f"img_{idx}.{ext}")
r = requests.get(url, timeout=5)
with open(filename, "wb") as f:
f.write(r.content)
print(f"Downloaded {filename}")
except:
pass
def single_thread_crawl():
print("=== 单线程爬取开始 ===")
to_visit = [START_URL]
visited = set()
page_count = 0
img_count = 0
while to_visit and page_count < PAGE_LIMIT and img_count < IMG_LIMIT:
url = to_visit.pop(0)
if url in visited:
continue
visited.add(url)
html = fetch_page(url)
if not html:
continue
page_count += 1
print(f"[Single] Visiting page {page_count}: {url}")
imgs = extract_images(html, BASE_URL)
for img in imgs:
if img_count >= IMG_LIMIT:
break
download_image(img, img_count)
img_count += 1
soup = BeautifulSoup(html, "html.parser")
for a in soup.find_all("a"):
href = a.get("href")
if href and href.startswith("http") and BASE_URL in href:
to_visit.append(href)
print("=== 单线程爬取结束 ===")
if __name__ == "__main__":
single_thread_crawl()
点击查看代码
import os
import threading
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
ID = "152301219"
PAGE_LIMIT = int(ID[-2:]) # 19 页
IMG_LIMIT = int(ID[-3:]) # 219 张
BASE_URL = "http://www.weather.com.cn"
START_URL = "http://www.weather.com.cn/"
SAVE_DIR = "multi_thread_images"
os.makedirs(SAVE_DIR, exist_ok=True)
def fetch_page(url):
try:
resp = requests.get(url, timeout=5)
resp.encoding = resp.apparent_encoding
return resp.text
except:
return ""
def extract_images(html, base_url):
soup = BeautifulSoup(html, "html.parser")
imgs = []
for img in soup.find_all("img"):
src = img.get("src")
if src:
imgs.append(urljoin(base_url, src))
return imgs
def download_image(url, idx):
try:
ext = url.split(".")[-1][:4]
filename = os.path.join(SAVE_DIR, f"img_{idx}.{ext}")
r = requests.get(url, timeout=5)
with open(filename, "wb") as f:
f.write(r.content)
print(f"[Thread] Downloaded {filename}")
except:
pass
def multi_thread_crawl():
print("=== 多线程爬取开始 ===")
to_visit = [START_URL]
visited = set()
page_count = 0
img_count = 0
threads = []
while to_visit and page_count < PAGE_LIMIT and img_count < IMG_LIMIT:
url = to_visit.pop(0)
if url in visited:
continue
visited.add(url)
html = fetch_page(url)
if not html:
continue
page_count += 1
print(f"[Multi] Visiting page {page_count}: {url}")
imgs = extract_images(html, BASE_URL)
for img in imgs:
if img_count >= IMG_LIMIT:
break
t = threading.Thread(target=download_image, args=(img, img_count))
t.start()
threads.append(t)
img_count += 1
soup = BeautifulSoup(html, "html.parser")
for a in soup.find_all("a"):
href = a.get("href")
if href and href.startswith("http") and BASE_URL in href:
to_visit.append(href)
for t in threads:
t.join()
print("=== 多线程爬取结束 ===")
if __name__ == "__main__":
multi_thread_crawl()
心得体会:
代码通过BeautifulSoup 库解析网页:在extract_images函数中,先将 HTML 文本加载为soup对象,然后调用soup.find_all("img")遍历页面所有图片标签,提取每个标签的src属性,并通过urljoin方法将相对路径拼接为绝对 URL,最终得到可直接访问的图片链接列表。此外,在页面遍历环节,同样通过BeautifulSoup解析标签,提取符合条件的页面链接,用于后续爬虫的页面拓展。但单线程模式在处理大量页面和图片时效率明显不足,随着PAGE_LIMIT和IMG_LIMIT增大,耗时会线性增长,所以用多线程爬虫能加快速度
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
代码逻辑:
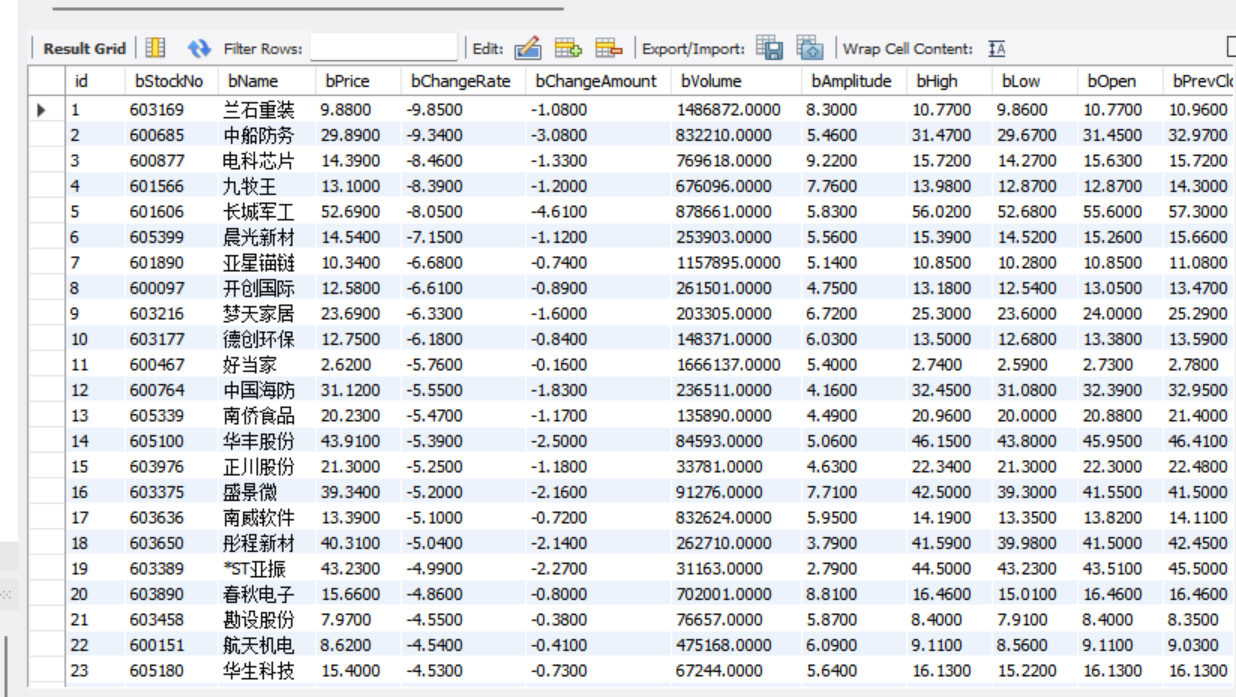
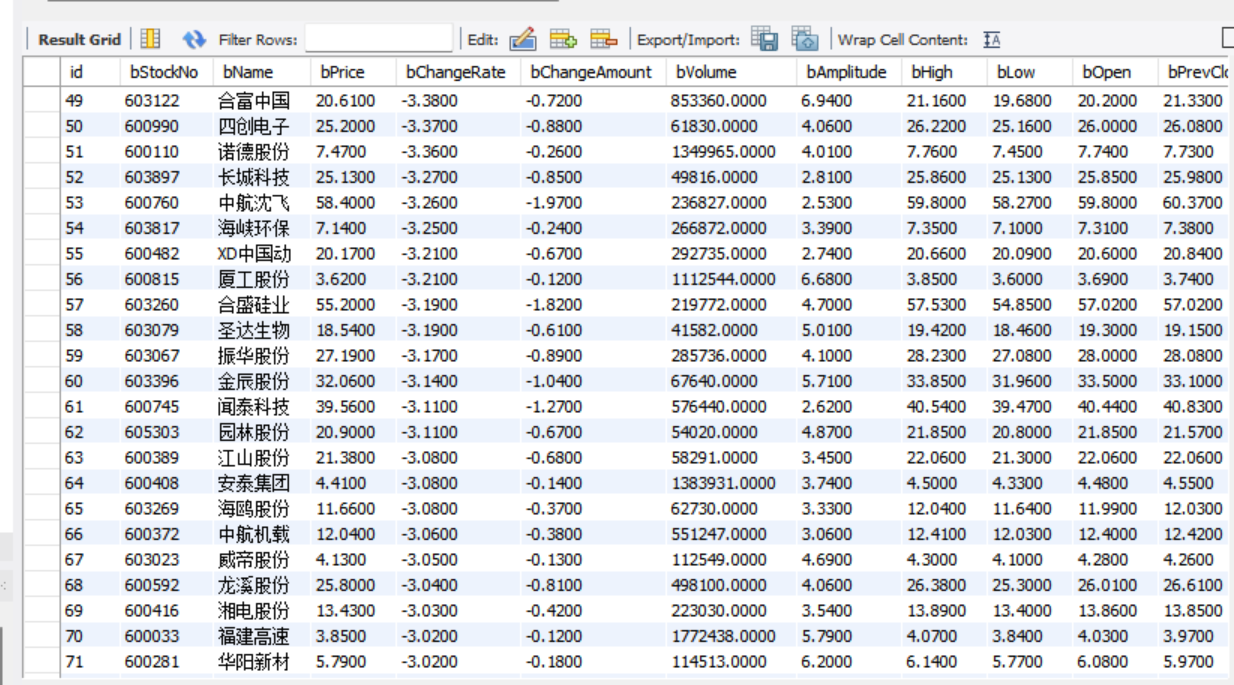
定义StockItem类,声明需爬取的字段(如bStockNo股票代码、bPrice价格等),规范数据格式。
点击查看代码
import scrapy
class StockItem(scrapy.Item):
id = scrapy.Field()
bStockNo = scrapy.Field()
bName = scrapy.Field()
bPrice = scrapy.Field()
bChangeRate = scrapy.Field()
bChangeAmount = scrapy.Field()
bVolume = scrapy.Field()
bAmplitude = scrapy.Field()
bHigh = scrapy.Field()
bLow = scrapy.Field()
bOpen = scrapy.Field()
bPrevClose = scrapy.Field()
点击查看代码
import pymysql
from scrapy.utils.project import get_project_settings
class StockScrapyPipeline:
def __init__(self):
settings = get_project_settings()
self.host = settings.get('MYSQL_HOST')
self.user = settings.get('MYSQL_USER')
self.password = settings.get('MYSQL_PASSWORD')
self.db_name = settings.get('MYSQL_DB')
self.table_name = settings.get('MYSQL_TABLE')
self.conn = None
self.cursor = None
def open_spider(self, spider):
self.conn = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.db_name,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
self.cursor = self.conn.cursor()
spider.logger.info("MySQL Connection Established.")
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS {self.table_name} (
id INT PRIMARY KEY,
bStockNo VARCHAR(20) NOT NULL UNIQUE,
bName VARCHAR(100),
bPrice DECIMAL(10, 4),
bChangeRate DECIMAL(10, 4),
bChangeAmount DECIMAL(10, 4),
bVolume DECIMAL(20, 4),
bAmplitude DECIMAL(10, 4),
bHigh DECIMAL(10, 4),
bLow DECIMAL(10, 4),
bOpen DECIMAL(10, 4),
bPrevClose DECIMAL(10, 4)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
self.cursor.execute(create_table_sql)
self.conn.commit()
def process_item(self, item, spider):
insert_sql = f"""
INSERT INTO {self.table_name} (
id, bStockNo, bName, bPrice, bChangeRate, bChangeAmount,
bVolume, bAmplitude, bHigh, bLow, bOpen, bPrevClose
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
bName=VALUES(bName),
bPrice=VALUES(bPrice),
bChangeRate=VALUES(bChangeRate),
bChangeAmount=VALUES(bChangeAmount),
bVolume=VALUES(bVolume),
bAmplitude=VALUES(bAmplitude),
bHigh=VALUES(bHigh),
bLow=VALUES(bLow),
bOpen=VALUES(bOpen),
bPrevClose=VALUES(bPrevClose);
"""
values = (
item.get("id"),
item.get("bStockNo"),
item.get("bName"),
item.get("bPrice"),
item.get("bChangeRate"),
item.get("bChangeAmount"),
item.get("bVolume"),
item.get("bAmplitude"),
item.get("bHigh"),
item.get("bLow"),
item.get("bOpen"),
item.get("bPrevClose"),
)
self.cursor.execute(insert_sql, values)
self.conn.commit()
return item
def close_spider(self, spider):
if self.conn:
self.conn.close()
spider.logger.info("MySQL Connection Closed.")
点击查看代码
import scrapy
import json
from stock_scrapy.items import StockItem
class StocksSpider(scrapy.Spider):
name = "stocks"
custom_settings = {
'DOWNLOAD_DELAY': 0.5,
}
api_url = (
"http://push2.eastmoney.com/api/qt/clist/get?"
"pn=1&pz=1000&np=1&fltt=2&fid=f3&fs=m:1+t:2"
"&fields=f2,f3,f4,f5,f6,f7,f8,f9,f12,f13,f14,f15,f16,f17,f18"
)
start_urls = [api_url]
def parse(self, response):
try:
data = json.loads(response.text)
stocks = data.get("data", {}).get("diff", [])
except json.JSONDecodeError as e:
self.logger.error(f"JSON decoding failed: {e}")
return
for idx, s in enumerate(stocks, start=1):
item = StockItem()
item["id"] = idx + (1 - 1) * 1000 # 假设 pn=1, pz=1000
item["bStockNo"] = s.get("f12") # 股票代码
item["bName"] = s.get("f14") # 股票名称
item["bPrice"] = s.get("f2") # 最新价
item["bChangeRate"] = s.get("f3") # 涨跌幅
item["bChangeAmount"] = s.get("f4") # 涨跌额
item["bVolume"] = s.get("f5") # 成交量
item["bAmplitude"] = s.get("f7") # 振幅
item["bHigh"] = s.get("f15") # 最高价
item["bLow"] = s.get("f16") # 最低价
item["bOpen"] = s.get("f17") # 开盘价
item["bPrevClose"] = s.get("f18") # 昨收价
if item["bStockNo"] and item["bName"]:
yield item
else:
self.logger.warning(f"Skipping item due to missing key data: {s}")
心得体会:
这次股票数据爬虫项目,目标是将 Scrapy 采集的数据高效地存入 MySQL 数据库,整个过程让我对数据流的工程化有了更深的理解。
在爬虫逻辑方面,我主要完成了对东方财富 API 数据的结构化提取。将 API 返回的简写字段(如 f12、f2)准确映射到我们定义的 StockItem 字段是基础,这个过程确保了数据在进入 Pipeline 前的清晰度。核心是 StocksSpider 通过 yield item 将数据对象推送下去,这种解耦设计非常高效。
但在项目实战中,我遇到了两个关键的逻辑问题,需要深刻反思:
反爬挑战:爬虫在第一次请求时就被 robots.txt 规则阻止。虽然技术上可以通过修改 ROBOTSTXT_OBEY 解决,但这提醒我,爬虫逻辑设计必须考虑到反爬策略,如 User-Agent 管理和代理池,以应对真实环境中的复杂性。
数据完整性缺失:我的爬虫逻辑目前仅执行了一次请求,只能获取到数据集的一个子集。这是最大的逻辑缺陷——缺乏分页机制。一个合格的爬虫必须能够根据 API 响应中的总数信息,动态构造并发出下一页请求,形成一个完整的循环,确保全量数据的覆盖。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
代码逻辑:
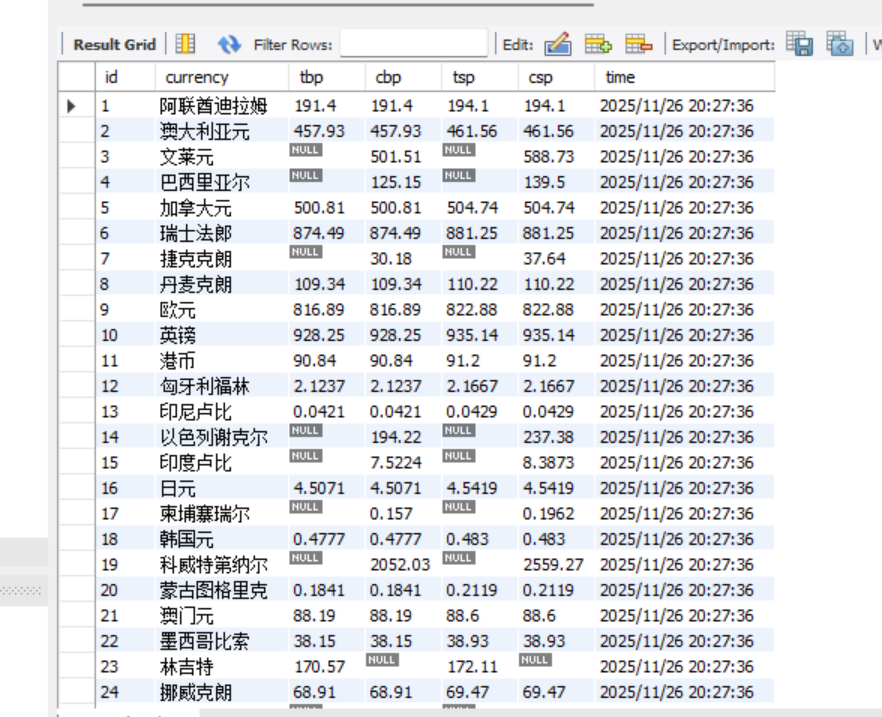
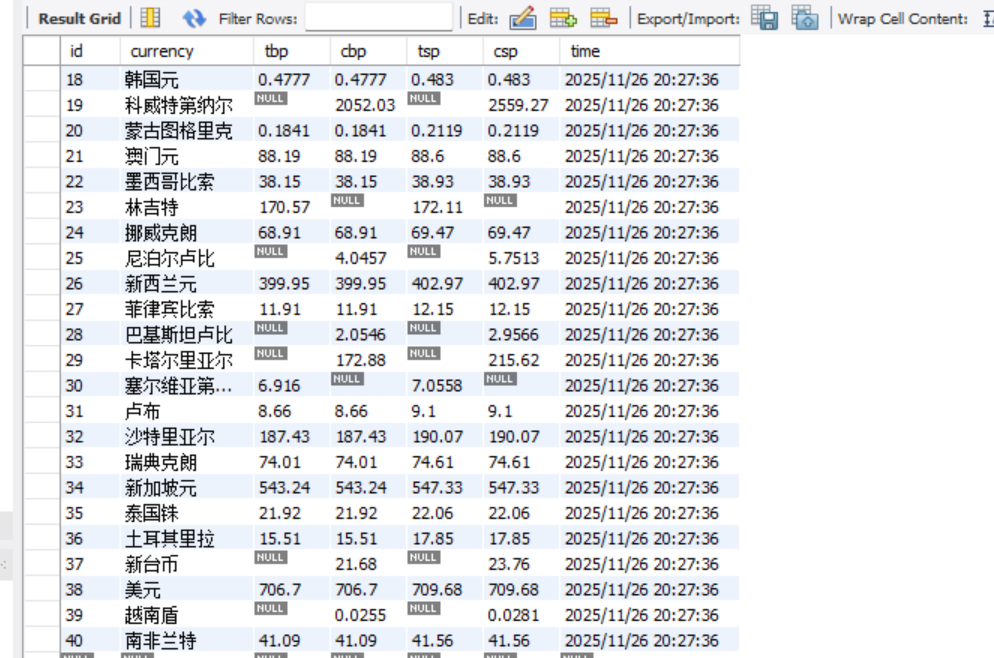
item封装
点击查看代码
import scrapy
class BocFxItem(scrapy.Item):
# 货币名称
Currency = scrapy.Field()
# 现汇买入价 (TBP: Telegraphic Transfer Buying Price)
TBP = scrapy.Field()
# 现钞买入价 (CBP: Cash Buying Price)
CBP = scrapy.Field()
# 现汇卖出价 (TSP: Telegraphic Transfer Selling Price)
TSP = scrapy.Field()
# 现钞卖出价 (CSP: Cash Selling Price)
CSP = scrapy.Field()
# 发布时间
Time = scrapy.Field()
点击查看代码
import pymysql
from scrapy.utils.project import get_project_settings
from itemadapter import ItemAdapter
class BocFxPipeline:
def __init__(self):
settings = get_project_settings()
self.host = settings.get('MYSQL_HOST')
self.user = settings.get('MYSQL_USER')
self.password = settings.get('MYSQL_PASSWORD')
self.db_name = settings.get('MYSQL_DB')
self.table_name = settings.get('MYSQL_TABLE')
self.conn = None
self.cursor = None
def open_spider(self, spider):
spider.logger.info("正在连接 MySQL 数据库...")
self.conn = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.db_name,
charset='utf8mb4',
cursorclass=pymysql.cursors.Cursor
)
self.cursor = self.conn.cursor()
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS {self.table_name} (
id INT AUTO_INCREMENT PRIMARY KEY,
currency VARCHAR(50) UNIQUE,
tbp VARCHAR(50),
cbp VARCHAR(50),
tsp VARCHAR(50),
csp VARCHAR(50),
time VARCHAR(50)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
self.cursor.execute(create_table_sql)
self.conn.commit()
spider.logger.info(f"MySQL 连接成功,表 '{self.table_name}' 准备就绪。")
def process_item(self, item, spider):
adapter = ItemAdapter(item)
insert_sql = f"""
INSERT INTO {self.table_name} (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
tbp = VALUES(tbp),
cbp = VALUES(cbp),
tsp = VALUES(tsp),
csp = VALUES(csp),
time = VALUES(time);
"""
data = (
adapter.get('Currency', ''),
adapter.get('TBP', ''),
adapter.get('CBP', ''),
adapter.get('TSP', ''),
adapter.get('CSP', ''),
adapter.get('Time', '')
)
self.cursor.execute(insert_sql, data)
self.conn.commit()
return item
def close_spider(self, spider):
if self.conn:
self.conn.close()
spider.logger.info("MySQL 数据库连接已关闭。")
点击查看代码
import scrapy
from boc_fx.items import BocFxItem
class BocSpiderSpider(scrapy.Spider):
name = "boc_spider"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
self.logger.info(f"成功访问页面,状态码: {response.status}")
rows = response.xpath('//div[@class="publish"]/div/table/tr[position()>1]')
if not rows:
self.logger.warning("未找到表格数据,可能是页面结构变化或反爬拦截。")
for row in rows:
item = BocFxItem()
# 提取货币名称并做非空判断
currency_name = row.xpath('./td[1]/text()').extract_first()
if not currency_name:
continue
item['Currency'] = currency_name.strip()
tbp_text = row.xpath('./td[2]/text()').extract_first()
item['TBP'] = tbp_text.strip() if tbp_text else None
cbp_text = row.xpath('./td[3]/text()').extract_first()
item['CBP'] = cbp_text.strip() if cbp_text else None
tsp_text = row.xpath('./td[4]/text()').extract_first()
item['TSP'] = tsp_text.strip() if tsp_text else None
csp_text = row.xpath('./td[5]/text()').extract_first()
item['CSP'] = csp_text.strip() if csp_text else None
time_text = row.xpath('./td[7]/text()').extract_first()
item['Time'] = time_text.strip() if time_text else None
yield item
心得体会:
开发时最考验细心的是 XPath 定位 —— 刚开始因漏看表格行索引导致数据提取空值,后来加了非空判断才稳定。用 SQLite 存数据时,遇到过插入失败的情况,通过事务回滚和异常捕获解决了问题。整个过程让我明白,爬虫不仅要精准解析页面,数据存储的健壮性也同样重要,细节处理直接影响最终结果的可靠性
该项目基于 Scrapy 框架爬取中国银行外汇牌价数据。首先,boc_spider.py定义爬虫类,指定目标网址和解析规则,通过 XPath 定位网页表格中的货币名称、现汇 / 现钞买卖价及时间等信息,封装成BocFxItem(定义在items.py)。随后,BocFxPipeline处理 Item,在爬虫启动时连接 SQLite 数据库并创建表,爬取过程中将数据插入数据库,结束时关闭连接,完成数据持久化。
gitee地址:https://gitee.com/li-zhiyang-dejavu/2025_crawl_project/tree/master/3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号