

数据采集与融合技术第二次作业
152301219李志阳第二次作业
一.天气预报
代码
点击查看代码
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con = sqlite3.connect("weathers.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("""
create table weathers (
wId int,
wCity varchar(16),
wDate varchar(16),
wWeather varchar(64),
wTemp varchar(32),
constraint pk_weather primary key (wCity,wDate)
)
""")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, id, city, date, weather, temp):
try:
self.cursor.execute("""
insert into weathers (wId, wCity, wDate, wWeather, wTemp)
values (?, ?, ?, ?, ?)
""", (id, city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print(f"{'序号':^6}{'地区':^10}{'日期':^12}{'天气信息':^30}{'温度':^12}")
print("-" * 6 + "+" + "-" * 10 + "+" + "-" * 12 + "+" + "-" * 30 + "+" + "-" * 12)
for row in rows:
print(f"{row[0]:^6}{row[1]:^10}{row[2]:^12}{row[3]:^30}{row[4]:^12}")
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
self.cityCode = {
"北京": "101010100",
"上海": "101020100",
"广州": "101280101",
"深圳": "101280601"
}
self.global_id = 1
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
high_temp = li.select('p[class="tem"] span')[0].text
low_temp = li.select('p[class="tem"] i')[0].text
temp = f"{high_temp}/{low_temp}"
self.db.insert(self.global_id, city, date, weather, temp)
self.global_id += 1
except Exception as err:
print(f"解析单条数据错误:{err}")
except Exception as err:
print(f"爬取{city}错误:{err}")
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
print("completed")

心得体会
这个任务主要是需要找到包含城市代码的URL。在请求时,必须添加User-Agent请求头来模拟浏览器。同时,由于网站编码可能在utf-8和gbk之间切换,使用了UnicodeDammit来智能判断和转码,确保BeautifulSoup能正确解析,中国天气网(weather.com.cn)的城市天气预报页面采用了 “固定域名 + 城市代码” 的 URL 格式。例如:北京的天气预报页面是:http://www.weather.com.cn/weather/101010100.shtml,上海的天气预报页面是:http://www.weather.com.cn/weather/101020100.shtml,可以发现,不同城市的 URL 仅差异在于中间的数字串(如101010100、101020100),这个数字串就是城市唯一编码,用于区分不同城市的天气数据页面。
任务二.股票
点击查看代码
import requests
import re
import json
import sqlite3
class EastmoneyDB:
def openDB(self):
self.con = sqlite3.connect("stocks.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("""
create table eastmoney (
eId integer primary key AUTOINCREMENT,
code text, -- 代码
name text, -- 名称
last_price real, -- 最新价
change_rate real, -- 涨跌幅(%)
change_amount real, -- 涨跌额
volume_hand integer, -- 成交量(手)
amount_wan real, -- 成交额(万)
amplitude real, -- 振幅(%)
high real, -- 最高
low real, -- 最低
open real, -- 今开
close real, -- 昨收
volume_ratio real, -- 量比
turnover_rate real, -- 换手率(%)
pe real, -- 市盈率(动态)
pb real -- 市净率
)
""")
except:
self.cursor.execute("delete from eastmoney")
self.cursor.execute("delete from sqlite_sequence where name='eastmoney'")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, data):
try:
self.cursor.execute("""
insert into eastmoney (
code, name, last_price, change_rate, change_amount,
volume_hand, amount_wan, amplitude, high, low,
open, close, volume_ratio, turnover_rate, pe, pb
) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""", (
data["f12"], # 代码
data["f14"], # 名称
data["f2"], # 最新价
data["f3"] / 10, # 涨跌幅(‰转%)
data["f4"], # 涨跌额
data["f5"] // 100, # 成交量(股转手,1手=100股)
data["f6"] / 10000, # 成交额(元转万)
data["f10"] / 10, # 振幅(‰转%)
data["f17"], # 最高
data["f18"], # 最低
data["f15"], # 今开
data["f16"], # 昨收
data["f7"], # 量比
data["f23"] / 10, # 换手率(‰转%)
data["f8"], # 市盈率(动态)
data["f9"] # 市净率
))
except Exception as err:
print(f"插入数据失败:{err}(股票代码:{data.get('f12', '未知')})")
def show(self):
self.cursor.execute("select * from eastmoney")
rows = self.cursor.fetchall()
print(f"""
{'序号':^6}{'代码':^10}{'名称':^10}{'最新价':^8}{'涨跌幅(%)':^7}{'涨跌额':^7}{'成交量(手)':^7}{'成交额(万)':^7}{'振幅(%)':^10}{'最高':^6}{'最低':^6}{'今开':^6}{'昨收':^8}{'量比':^6}{'换手率(%)':^10}{'市盈率(动态)':^12}{'市净率':^8}
""")
for row in rows:
print(f"""
{row[0]:^6}{row[1]:^10}{row[2]:^12}{row[3]:^8.2f}{row[4]:^10.2f}{row[5]:^8.2f}{row[6]:^10.0f}{row[7]:^12.2f}{row[8]:^8.2f}{row[9]:^8.2f}{row[10]:^8.2f}{row[11]:^8.2f}{row[12]:^8.2f}{row[13]:^6.2f}{row[14]:^10.2f}{row[15]:^12.2f}{row[16]:^8.2f}
""", end="")
class EastmoneyCrawler:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8"
}
self.url = "https://push2.eastmoney.com/api/qt/clist/get?np=1&fltt=1&invt=2&cb=jQuery37107464837063116043_1761720328340&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A81%2Bs%3A262144%2Bf%3A!2&fields=f12%2Cf14%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6%2Cf10%2Cf17%2Cf18%2Cf15%2Cf16%2Cf7%2Cf23%2Cf8%2Cf9&fid=f3&pn=1&pz=20&po=1&dect=1&ut=fa5fd1943c7b386f172d6893dbfba10b&wbp2u=%7C0%7C0%7C0%7Cweb&_=1761720328342"
def crawl(self):
try:
response = requests.get(self.url, headers=self.headers)
json_str = re.findall(r'\((.*?)\)', response.text)[0]
data_dict = json.loads(json_str)
if "data" in data_dict and "diff" in data_dict["data"]:
return data_dict["data"]["diff"]
else:
print("未获取到数据,接口可能失效")
return []
except Exception as err:
print(f"爬取失败:{err}")
return []
def process(self):
self.db = EastmoneyDB()
self.db.openDB()
data_list = self.crawl()
for data in data_list:
self.db.insert(data)
self.db.show()
self.db.closeDB()
crawler = EastmoneyCrawler()
crawler.process()

心得体会
直接对接东方财富网的JSONP 格式 API 接口(URL 中含cb=jQueryxxx参数)—— 这类接口返回的是 “jQuery 回调包裹的 JSON 数据”(如jQueryxxx({"data": {...}}))。代码通过re.findall(r'((.*?))', response.text)[0]精准提取括号内的 JSON 字符串,再用json.loads转换为字典,完美适配了接口数据格式,这是金融类网站常见的数据获取方式,比 HTML 解析更高效。
任务三.大学排名
代码
点击查看代码
import requests
import json
import sqlite3
class UniversityDB:
def openDB(self):
self.con = sqlite3.connect("university_rank_2021.db")
self.cursor = self.con.cursor()
self.cursor.execute("DROP TABLE IF EXISTS university")
self.cursor.execute("""
create table university (
rank integer,
name text,
province text,
category text,
score real
)
""")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, data):
# 提取接口中的实际排名(ranking)和总分(score)
try:
rank = int(data.get("ranking", 0)) # 确保排名是整数
score = float(data.get("score", 0)) # 确保总分是浮点数
except (ValueError, TypeError):
rank = 0
score = 0.0
try:
self.cursor.execute("""
insert into university (rank, name, province, category, score)
values (?, ?, ?, ?, ?)
""", (
rank,
data.get("univNameCn", "未知学校"),
data.get("province", "未知省市"),
data.get("univCategory", "未知类型"),
score
))
except Exception as err:
print(f"插入失败:{err}(学校:{data.get('univNameCn', '未知')})")
def show(self):
self.cursor.execute("SELECT * FROM university ORDER BY rank ASC")
rows = self.cursor.fetchall()
print(f"\n{'排名':^6}{'学校名称':^16}{'省市':^8}{'类型':^8}{'总分':^8}\n")
for row in rows:
print(
f"{row[0]:^6}" # 实际排名(1、2、3...)
f"{row[1]:^16}" # 学校名称
f"{row[2]:^8}" # 省市
f"{row[3]:^8}" # 类型
f"{row[4]:^8.1f}" # 总分
)
class UniversityCrawler:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Referer": "https://www.shanghairanking.cn/rankings/bcur/2021"
}
self.url = "https://www.shanghairanking.cn/api/pub/v1/bcur?bcur_type=11&year=2021"
def crawl(self):
try:
response = requests.get(self.url, headers=self.headers)
data_dict = response.json()
return data_dict.get("data", {}).get("rankings", [])
except Exception as err:
print(f"爬取失败:{err}")
return []
def process(self):
self.db = UniversityDB()
self.db.openDB()
for data in self.crawl():
self.db.insert(data)
self.db.show()
self.db.closeDB()
if __name__ == "__main__":
crawler = UniversityCrawler()
crawler.process()

......
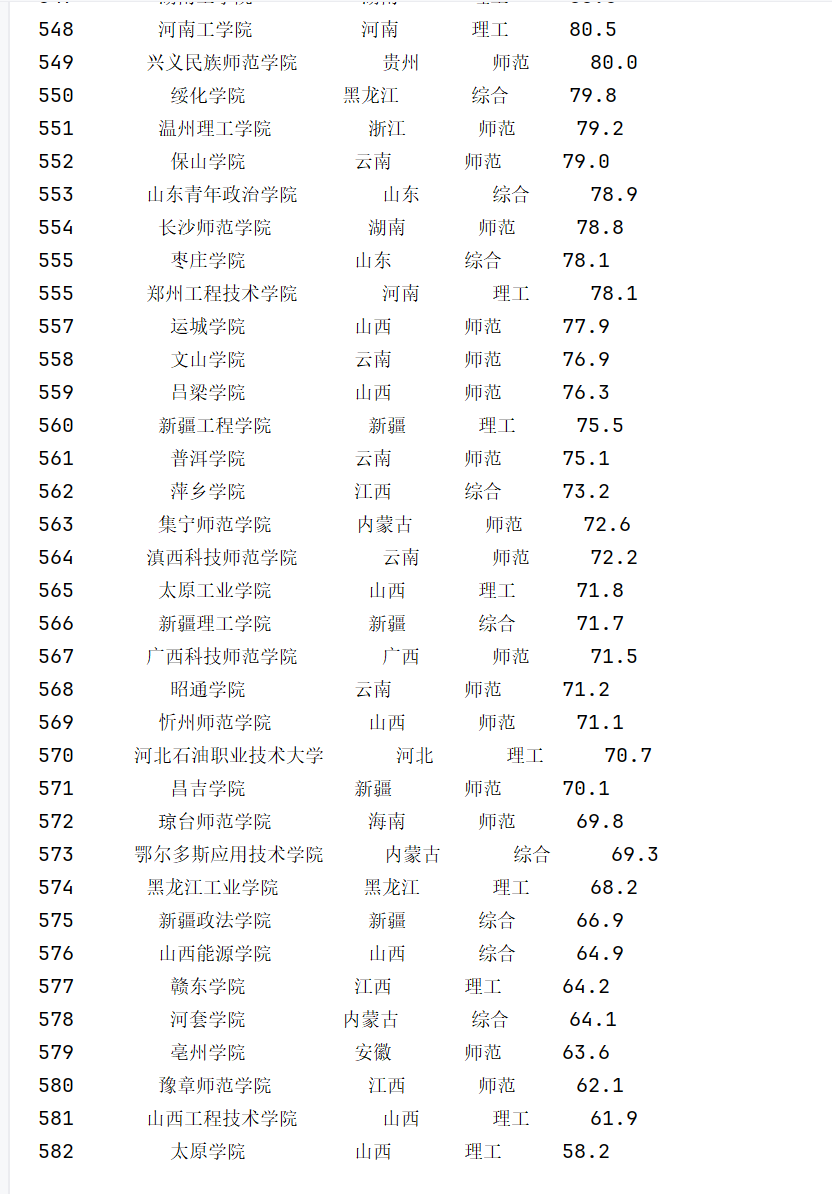

心得体会
主要是运用结构化 API 接口的精准利用,核心逻辑围绕 “直接请求目标数据接口 + 解析 JSON 响应” 展开,具体手段可拆解为以下几点:
直接使用了上海软科(Shanghairanking)发布的 2021 年中国大学排名官方 API 接口:https://www.shanghairanking.cn/api/pub/v1/bcur?bcur_type=11&year=2021。分析网页加载过程:通过浏览器 “开发者工具 - 网络” 面板,监控页面加载时的 XHR/JSON 请求,找到返回排名数据的接口(如该接口返回包含学校名称、排名、分数等字段的 JSON 数据);解析接口参数:URL 中的bcur_type=11(可能代表 “中国大学排名类型”)和year=2021(指定年份)是关键参数,通过调整参数可获取不同年份或类型的排名数据。
gitee地址:https://gitee.com/li-zhiyang-dejavu/2025_crawl_project/tree/master/2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号