
HDFS分布式文件系统
HDFS分布式文件系统是一个部署在廉价机器上基于POSIX约束的高容错性、高吞吐量的大规模分布式文件管理系统;它适合于大文件的存储,应用于“一次写入多次读取”的文件模型。
架构
HDFS采用的是Master/Slave架构,一个HDFS集群由一个NameNode和一定数目的Datanotes组成,NameNode是一个中心服务器,负责管理文件系统的命名空间以及客户端对文件的访问,DataNote负责具体的文件存储。
一个文件通常被分为一个或者多个数据块,这些数据块存储在一组Datanotes上;NameNode管理者整个文件系统的元数据(文件名、路径、文件的副本数量),同时也负责具体数据块到Datanote节点的映射。
Datanote负责处理文件系统的客户端读写请求,并在NameNode的调度下完成数据块的创建、删除、复制。Datanote通过心跳告知NameNode自己的工作状态信息和块状态信息;
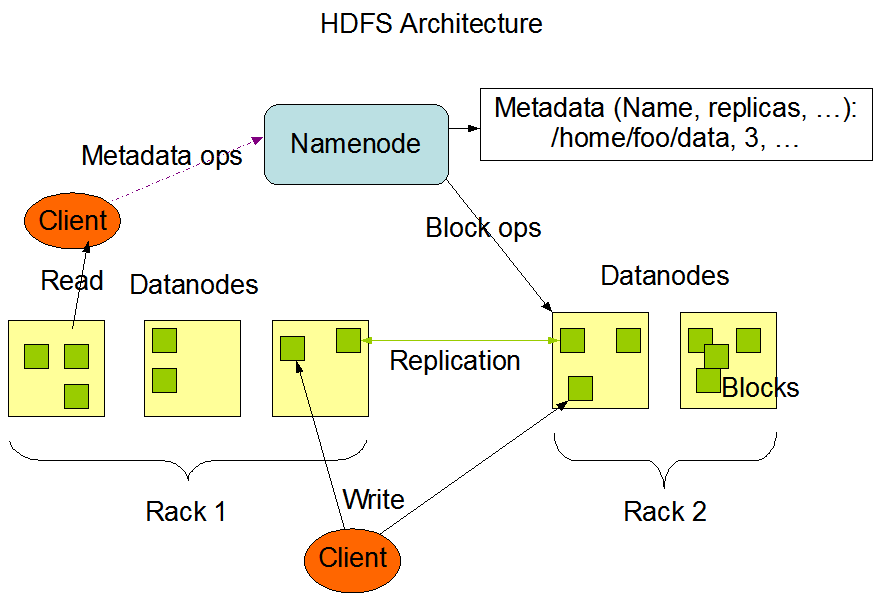
在Master/Slave架构里,所有的Slave节点都必须使用Master做协调,必然会导致Master成为系统瓶颈和单一故障点;
HDFS在不借助于Zookeeper多数票选举机制的情况下,Namenode依然存在脑裂的问题。
特点
智能化的副本控制
文件写
为了保证文件系统的高可用性,HDFS会为每个文件存放多个副本(副本数量可通过dfs.replication自定义配置),并通过机架感知策略将副本均匀分布在集群中,如保证不同的机架、数据中心都存放有副本;
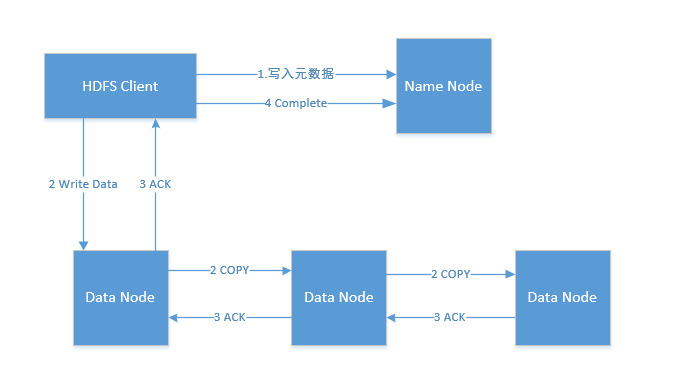
写入多少个副本表示成功,取决于dfs.namenode.replication.min的配置(默认为1);
写入文件的内容,并非立刻可见,而是当写入数据的长度超过一个数据块的时候,才会被刷新的磁盘上
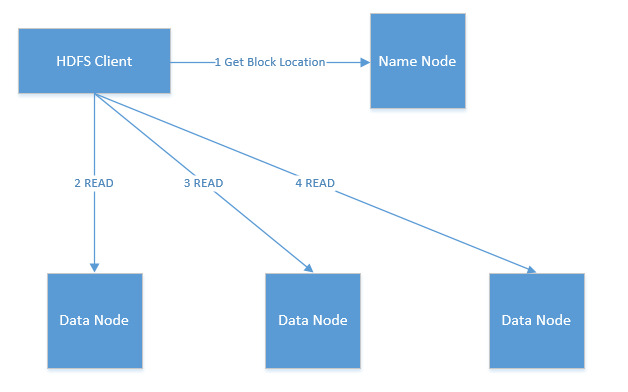
文件读
为了减少带宽和延迟,HDFS优先让客户端读取离它最近的副本,比如同一个机架上的副本或同一个数据中心的副本;
集群负载均衡
如果某个Datanote节点上的空闲空间低于设定的临界点时,按照负载均衡策略会自动将数据从这个Datanote移动到其他空闲的Datanote;
数据完整性
每个Datanote都会保存每一个数据块的校验和日志,客户端读取Datanote的数据块时,会校验从Datanote获取的数据与相应的校验和文件中的校验和是否相匹配;如果不匹配,客户端可以选择从其他的Datanote获取该数据块的副本;
每个Datanote也会在一个后台线程中运行一个DataBlockScanner,从而定期校验存储在这个Datanote上的所有数据块;如果校验失败,则会通过其他的数据副本来修复损坏的数据块,从而得到一个新的、完好无损的副本;
创作不易,转载请注明作者JosenZHANG和出处 https://www.cnblogs.com/defectfixer/p/15749351.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号