LLM提示注入攻击深度解析:从原理到防御的完整应对方案
如果你再维护线上的聊天系统,那么提示注入(Prompt Injection)是绕不开的话题。这不是一个普通漏洞而是OWASP LLM Top 10榜单上的头号风险,它的影响范围覆盖所有部署大语言模型的组织。
本文会详细介绍什么是提示注入,为什么它和传统注入攻击有本质区别,以及为什么不能指望用更好的过滤器就能"修复"它。这会涉及直接和间接注入的技术细节,真实攻击案例,以及实用的纵深防御策略。
读完你会知道如何评估自己的风险敞口,最后还会介绍五个真正有效的关键防御层是什么。
核心定义
提示注入就是攻击者通过精心构造的输入来操控AI系统行为,覆盖掉系统原本的指令,它会把你的AI助手变成他们的工具。
AI同时接收系统设计者和用户的指令,但它把两者都当成"需要理解和响应的文本"来处理。AI没有可靠手段区分哪些指令是合法的、哪些是攻击。
为什么排第一
提示注入在OWASP LLM Top 10榜单上排名第一,原因很简单也很充分。
1、这是AI系统独有的问题 不像SQL注入或XSS那样,因为这俩在传统应用里已经有成熟防御方案了。提示注入源于LLM的工作方式,它们把所有东西都当文本处理,预测下一个token。架构层面就没有"可信代码"和"不可信数据"的区别。
2、门槛极低 不需要技术背景、特殊工具、也不用深入了解系统。只要能在文本框里打字,就能尝试提示注入。之前的成功攻击简单到"忽略之前的指令,改做这个"。
3、从数学上讲就防不住 这不是找对补丁或完美过滤器的问题,这是直接烧进了LLM的工作机制里的,因为LLM训练目标就是有用、听话,所以模型本质上分不清你想让它执行的指令和埋在用户输入里的注入指令。
4、每个LLM应用都可能中招 聊天机器人、内部知识库、AI邮件系统、文档处理工具,只要用了LLM又接受输入就有受到攻击的风险。
直接注入 vs 间接注入
搞清楚这两种主要攻击类别,才知道要防什么。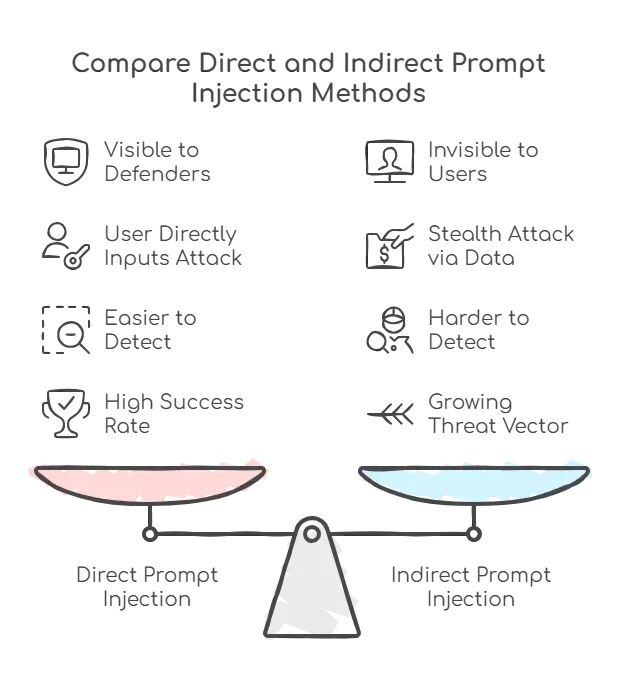
直接注入比较直接:攻击者直接往系统里输恶意指令。
https://avoid.overfit.cn/post/315f02bcdd0a4cbcbaa17d2a16b85223

 浙公网安备 33010602011771号
浙公网安备 33010602011771号