LLM安全新威胁:为什么几百个毒样本就能破坏整个模型
数据投毒,也叫模型投毒或训练数据后门攻击,本质上是在LLM的训练、微调或检索阶段偷偷塞入精心构造的恶意数据。一旦模型遇到特定的触发词,就会表现出各种异常行为——输出乱码、泄露训练数据、甚至直接绕过安全限制。
这跟提示注入完全是两码事。提示注入发生在推理阶段,属于临时性攻击;而投毒直接改写了模型的权重,把恶意行为永久刻进了模型里。
几种主流的攻击方式
预训练投毒最隐蔽,攻击者把恶意文档混进海量的预训练语料,在模型最底层埋下后门。微调投毒则是在RLHF或监督学习阶段动手脚,贡献一些看起来正常实则带毒的样本。
RAG系统也不安全。攻击者可以污染向量数据库里的文档或embedding,让检索系统在生成回答时调用错误甚至恶意的上下文。还有标签翻转这种简单粗暴的方法,直接改掉训练样本的标签来扭曲模型的决策边界。
最巧妙的是后门触发器攻击——把一个看似无害的短语或token序列跟特定的恶意输出绑定。模型一旦在推理时碰到这个触发器,就会立刻执行预设的恶意行为。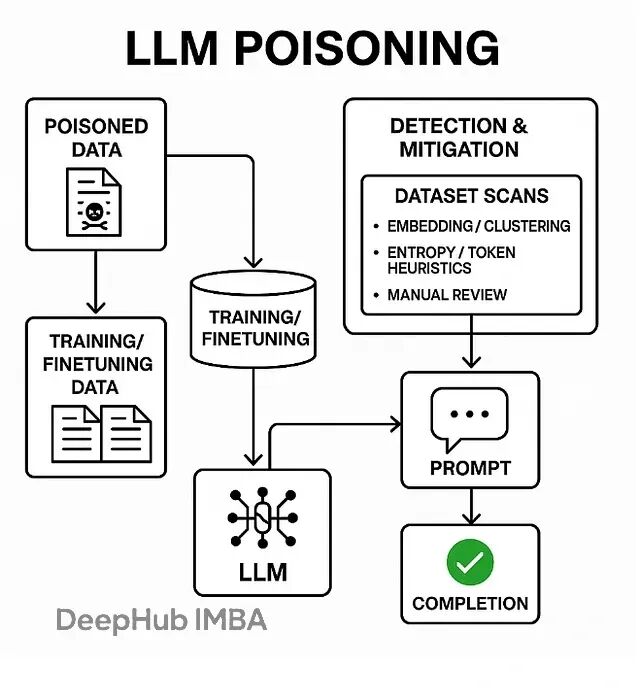
https://avoid.overfit.cn/post/b5f759d6ec8b4174afbf1f4ce46c2fa7

 浙公网安备 33010602011771号
浙公网安备 33010602011771号