REFRAG技术详解:如何通过压缩让RAG处理速度提升30倍
RAG(检索增强生成)现在基本成了处理长文档的标准流程,但是它问题也很明显:把检索到的所有文本段落统统塞进LLM,这样会导致token数量爆炸,处理速度慢不说,还费钱。
meta提出了一个新的方案REFRAG:与其让LLM处理成千上万个token,不如先用轻量级编码器(比如RoBERTa)把每个固定大小的文本块压缩成单个向量,再投影到LLM的token嵌入空间。
他在论文中说可以提速30倍,我们来看看是怎么做的:
输入序列长度大幅缩短,每个文本块变成一个向量而不是几十个token。计算可以重用,块嵌入在检索阶段就能预计算好,避免重复编码。注意力机制变得更稀疏,LLM现在只需要关注块级别的信息,而不是每个token。
更有意思的是,REFRAG保留了自回归解码的灵活性。它可以在上下文的任意位置进行压缩,通过一个学习策略将压缩嵌入和真实token嵌入混合使用。在实际应用中,基于强化学习的选择策略会挑选少数"重要"块展开为完整token序列,其他块继续保持压缩状态。这和传统RAG形成鲜明对比——后者会把每个检索段落的每个token都完整输入解码器,在无关或冗余文本上浪费大量计算资源。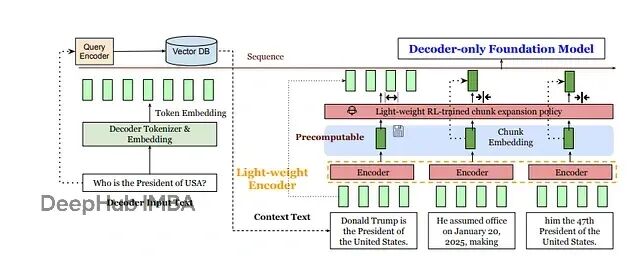
REFRAG的整体流程非常好理解。检索到的上下文先被拆分成固定大小的块,送入轻量编码器;强化学习策略决定哪些块需要展开为完整token;最后解码器接收查询token和块嵌入的混合输入。
https://avoid.overfit.cn/post/2675cf1a065745c9bc44d755d5141a0d

 浙公网安备 33010602011771号
浙公网安备 33010602011771号