微软rStar2-Agent:新的GRPO-RoC算法让14B模型在复杂推理时超越了前沿大模型
Microsoft Research最近发布的rStar2-Agent展示了一个令人瞩目的结果:一个仅有14B参数的模型在AIME24数学基准测试上达到了80.6%的准确率,超越了671B参数的DeepSeek-R1(79.8%)。这不是简单的参数效率提升,而是AI推理的进步。
过去几年,大语言模型的发展主要依赖Chain-of-Thought(CoT)提示技术,让模型"展示工作过程"。这催生了"思考更久"的训练范式——通过更长的推理链条来提升性能。OpenAI的o系列和DeepSeek-R1都证明了这条路径在强化学习加持下的有效性。
但这个方向存在明显的天花板。在竞赛数学这类真正困难的问题上,长CoT模型容易犯细微错误,缺乏灵活调整策略的能力,即使发现错误也难以有效自我纠正。就像一个学生能写出100步解题过程,却没有足够的理解力意识到第三步就错了。
rStar2-Agent的突破在于从"思考更久"转向"思考更聪明"。这个模型不仅能使用Python工具进行计算验证,更重要的是学会了如何高效地探索解题路径、自我纠错,并在工具使用中保持简洁性。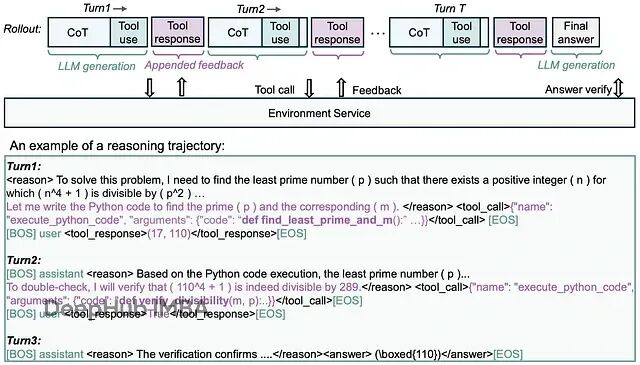
rStar2-Agent训练LLMs在专用执行环境中原生使用Python编程工具,为复杂问题解决实现更高级和有效的推理。
https://avoid.overfit.cn/post/fec33d06dbf34c0aba06fb78e3b465bf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号