R-Zero:通过自博弈机制让大语言模型无需外部数据实现自我进化训练
R-Zero框架实现了大语言模型在无外部训练数据条件下的自主进化与推理能力提升。
当前的LLM改进方法高度依赖大规模人工标注数据,这种范式虽然取得了显著成果但面临两个根本性限制:人类生成数据的有限性将导致训练瓶颈,以及人工数据的智能上界制约了模型超越人类能力的可能性。
针对这一挑战,研究人员提出了一个关键问题:是否存在让LLM自主识别缺陷、生成训练数据并据此改进的方法?最新发表在ArXiv上的研究给出了肯定答案。研究团队提出的R-Zero框架是一个完全自主的训练系统,能够使LLM从零开始生成自身训练数据并实现持续改进。
实验结果显示,R-Zero在多个数学推理和通用领域推理基准测试中显著提升了LLM的推理性能。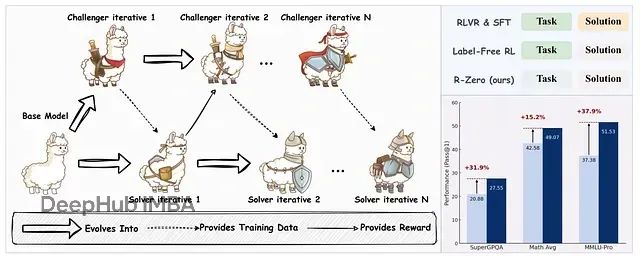
R-Zero框架示意图及其在Qwen3–4B-Base模型上实现的性能提升
https://avoid.overfit.cn/post/d18d62b217dd4ad6a87599757579e450

 浙公网安备 33010602011771号
浙公网安备 33010602011771号