近端策略优化算法PPO的核心概念和PyTorch实现详解
近端策略优化(Proximal Policy Optimization, PPO)作为强化学习领域的重要算法,在众多实际应用中展现出卓越的性能。本文将详细介绍PPO算法的核心原理,并提供完整的PyTorch实现方案。
PPO算法在强化学习任务中具有显著优势:即使未经过精细的超参数调优,也能在Atari游戏环境等复杂场景中取得优异表现。该算法不仅在传统强化学习任务中表现出色,还被广泛应用于大语言模型的对齐优化过程。因此掌握PPO算法对于深入理解现代强化学习技术具有重要意义。
本文将通过Lunar Lander环境演示PPO算法的完整实现过程。文章重点阐述算法的核心概念和实现细节,通过适当的修改,本实现方案可扩展至其他强化学习环境。本文专注于高层次的算法理解,为读者提供系统性的技术资源。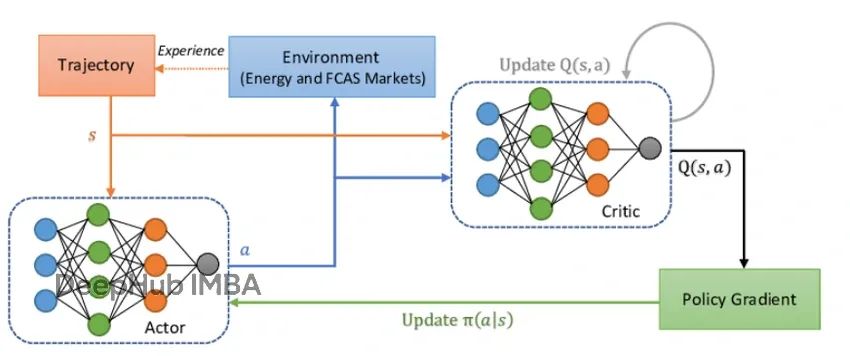
PPO算法核心组件
PPO算法由四个核心组件构成:环境交互模块、智能体决策系统、优势函数计算以及策略更新裁剪机制。每个组件在算法整体架构中发挥着关键作用。
https://avoid.overfit.cn/post/a0f561df40ad474db2a7749abb573aeb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号