MoR vs MoE架构对比:更少参数、更快推理的大模型新选择
Google DeepMind 近期发布了关于递归混合(Mixture of Recursion)架构的研究论文,这一新型 Transformers 架构变体在学术界和工业界引起了广泛关注。该架构通过创新的设计理念,能够在保持模型性能的前提下显著降低推理延迟和模型规模。
本文将深入分析递归混合(MoR)与专家混合(MoE)两种架构在大语言模型中的技术特性差异,探讨各自的适用场景和实现机制,并从架构设计、参数效率、推理性能等多个维度进行全面对比。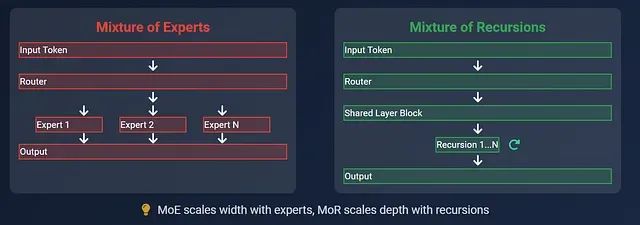
https://avoid.overfit.cn/post/c95f03d8ad3049ada1c41e71094e2fd5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号