差分隐私机器学习:通过添加噪声让模型更安全,也更智能
在敏感数据训练的机器学习模型中,个人信息通过推理攻击泄露的风险日益凸显。本文探讨如何在模型训练过程中平衡实用性与形式化隐私保证这一关键问题。我们采用带有噪声梯度更新的模拟DP-SGD算法实现差分隐私机器学习。实验结果表明,该模型在保持71%准确率和0.79 AUC的同时,展现出良好的泛化能力,但在少数类预测精度方面有所折衷。研究证明DP-SGD算法能够有效支持隐私感知学习,但需要在设计阶段进行精细的参数调优和权衡考量。
2020年,研究人员发现一个已部署的机器学习模型存在严重的隐私泄露风险:通过精心设计的查询序列,攻击者能够逐步推断出训练数据中的个人信息,而无需直接访问原始数据集。这一发现揭示的不是传统意义上的加密或访问控制失效,而是一个更为根本的设计缺陷。在机器学习实践中,我们通常从准确性、效率和泛化能力等维度评估模型性能。然而,在数据隐私法规日趋严格和恶意应用风险不断增加的当前背景下,一个关键问题亟待解答:模型应当提供何种程度的隐私保护?更为重要的是,如何在设计阶段就将隐私保护机制有机融入模型架构?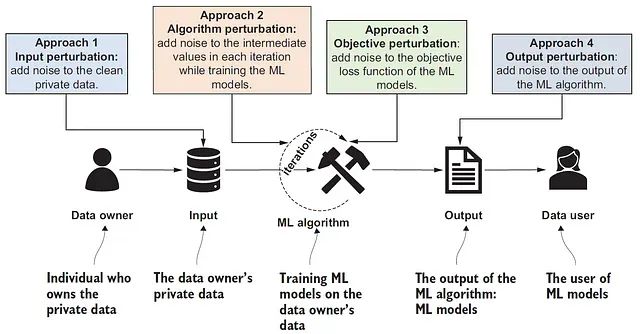
差分隐私的核心理念在于:隐私保护并非简单的信息屏蔽,而是训练模型在表达学习到的数据模式的同时,避免暴露具体的个人信息。
https://avoid.overfit.cn/post/f26a46bb143d4e3a87b957c3f00b2c4a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号