CUDA性能优化实战:7个步骤让并行归约算法提升10倍效率
本文深入探讨了一个经典的并行计算算法——并行归约(Parallel Reduction)的性能优化过程,通过七个渐进式的优化步骤,展示了如何将算法性能提升至极致。这项研究基于Mark Harris在NVIDIA网络研讨会中提出的优化方法,在重现这些优化技术的同时,进一步简化了概念阐述以便于理解。配套的GitHub代码库提供了完整的实现细节,为读者深入研究提供了详实的技术支撑。
算法原理分析
并行归约算法是CUDA编程中的一个重要数据并行原语,其核心思想是利用GPU的线程层次结构对向量、矩阵或张量进行并行计算。该算法通过sum()、min()、max()或avg()等操作对数据进行聚合处理。本文将重点使用sum()操作进行数据集归约。尽管这些操作在概念上相对简单,但它们在众多应用场景中发挥着关键作用,因此需要高度优化以避免成为性能瓶颈。
在并行化实现过程中,算法采用基于树的方法,计算任务分布在GPU的各个线程块中。这里面临一个核心技术挑战:如何在线程块之间高效传递部分计算结果?最直观的解决方案是采用全局同步机制——让各个块完成计算后进行全局同步,然后递归继续处理。CUDA架构并不支持全局同步,主要原因是硬件成本过高,且会限制程序员只能使用少量线程块以避免死锁,从而显著降低整体计算效率。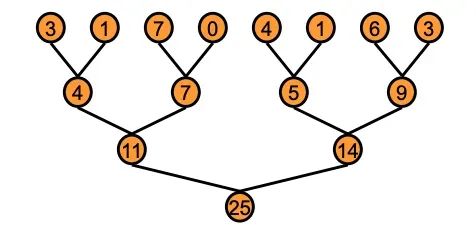
基于树的归约 | 来源:NVIDIA
解决线程块间部分结果通信问题的实用方法是采用内核分解技术。内核分解将大规模的内核任务分解为多个较小的、可管理的子任务,这些子任务可以在不同的线程或块中独立执行。这种方法最大限度地减少了硬件和软件开销,实现了更灵活高效的GPU资源利用,同时降低了同步需求并提升了整体计算性能。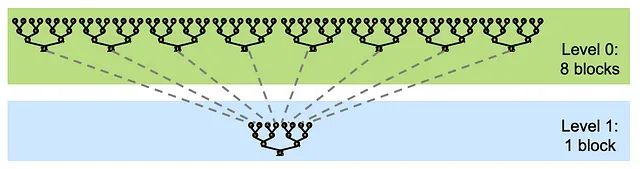
内核分解 | 来源:NVIDIA
https://avoid.overfit.cn/post/af59d0a6ce474b8fa7a8eafb2117a404

 浙公网安备 33010602011771号
浙公网安备 33010602011771号