Arctic长序列训练技术:百万级Token序列的可扩展高效训练方法
在现实应用场景中,许多AI系统需要处理超过数十万token的长文本序列,例如密集文档分析、长对话理解以及检索增强生成(RAG)管道等。当前大多数语言模型仅在相对较短的文本片段上进行训练。这种训练与应用需求的不匹配,类似于要求模型仅通过阅读小说的一页内容就能完成整本书的总结任务。虽然模型可能捕获到文本的语调和风格特征,但往往会遗漏关键的内容逻辑和故事脉络。因此要实现有效的长上下文推理能力,模型必须在长序列数据上进行充分训练。
尽管Llama 3.x和Qwen 2.5 32B等先进模型已经支持128k-token序列处理,部分Llama变体甚至可以扩展到1000万token,但在这种极长序列上进行针对特定任务的微调对于大多数数据科学从业者而言仍然难以实现。主要制约因素在于GPU内存限制。现有的训练管道主要针对短序列进行优化,缺乏处理百万级token输入的能力。这使得大规模长序列训练仅限于具备复杂企业级训练系统的少数团队。
Arctic长序列训练(Arctic Long Sequence Training, ALST)技术的开源发布有效解决了这一技术鸿沟。该技术是一套模块化的开源解决方案,能够在4个H100节点上对Meta的Llama-8B模型进行高达1500万token序列的训练,完全基于Hugging Face Transformers和DeepSpeed框架实现,无需修改底层建模代码。ALST使得长序列训练在标准GPU集群甚至单个GPU上都能实现快速、高效且易于部署的执行。
通过应用这些技术方法,研究团队在单个H100 GPU上成功训练了500K token的序列,在单节点配置下达到3.7M token,在Llama-8B模型上仅使用四个节点就实现了1500万token的训练能力。与标准Hugging Face训练管道相比,这些结果分别实现了16倍、116倍和469倍的性能提升。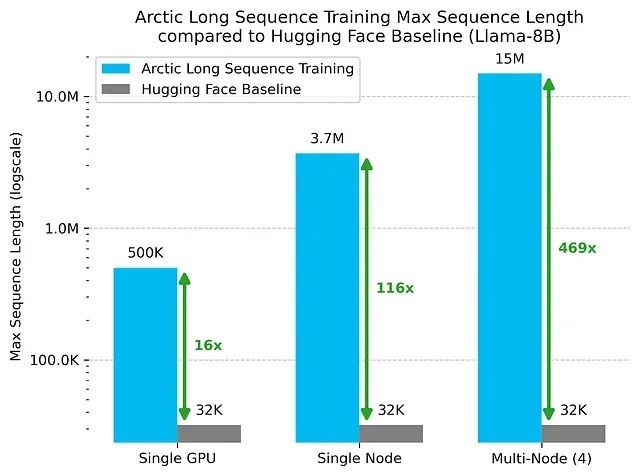
图1:Arctic长序列训练与Hugging Face基线相比,在单GPU、单节点和多节点配置下实现的最大序列长度对比,结果基于Llama-8B模型测试
完整的方法论细节和可重现性基准测试可参考ALST技术论文。本文将深入分析长序列训练面临的技术挑战、Arctic长序列训练的核心工作原理,以及该技术的实际应用方法。
https://avoid.overfit.cn/post/eeb4a35742314854a83956d93d00b5de

 浙公网安备 33010602011771号
浙公网安备 33010602011771号