小模型当老师效果更好:借助RLTs方法7B参数击败671B,训练成本暴降99%
Sakana AI提出的强化学习教师模型(Reinforcement-Learned Teachers, RLTs)代表了一种全新的训练范式。该方法颠覆了传统强化学习需要模型从零开始通过稀疏奖励信号解决问题的训练方式,转而从已知答案出发,训练小型"教师"模型以适合学生模型学习的方式解释解决方案。
实验结果表明,仅有7B参数的教师模型在推理教学效果上超越了671B参数的大型模型,同时显著降低了训练成本和时间开销。本文将深入分析RLT的工作机制,与RLHF、监督微调及传统知识蒸馏等方法进行对比,并提供详细的代码实现示例以及基于Docker和Kubernetes的部署方案。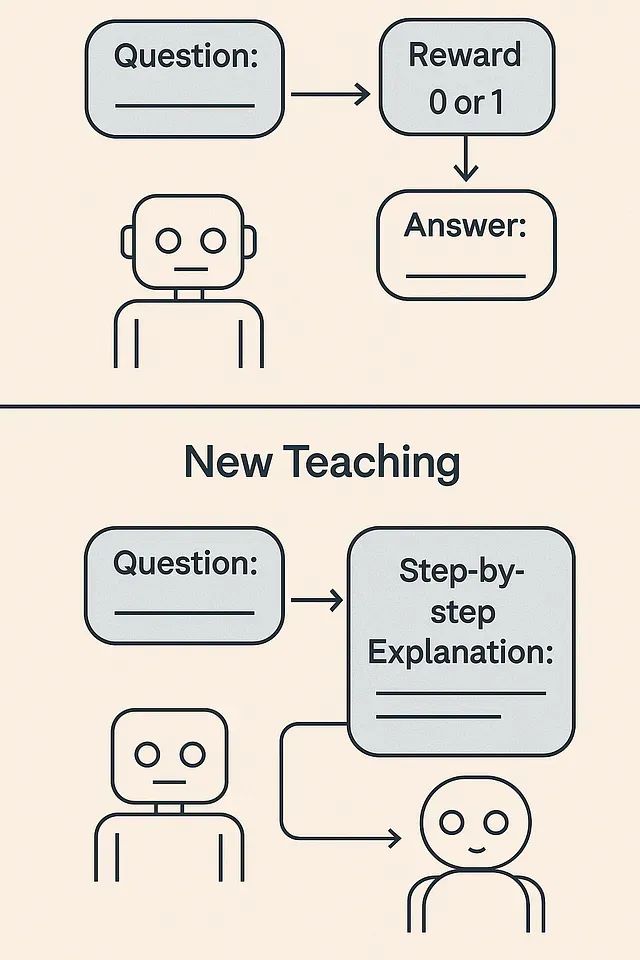
传统强化学习在推理任务中的局限性
传统强化学习在语言模型训练中面临诸多挑战,特别是在复杂推理任务方面。在经典的RL推理训练框架中,大型模型需要与环境(如数学问题集或编程挑战)进行交互,仅在得出正确答案时才能获得奖励。这种"学习求解"的方法要求模型通过试错过程自主发现解决方案,在随机尝试获得正确答案之前往往无法获得任何奖励信号。
传统RL方法的主要问题包括:首先是奖励稀疏性和长序列依赖问题。解决复杂数学问题或编写程序涉及多个步骤,但传统RL通常只在最终结果处提供二元奖励(正确或错误)。这种极其稀疏的信号使得模型无法识别其长推理过程中哪些部分是有益的或有害的。
其次是探索效率低下的问题。如果模型的初始能力不足,它几乎不可能通过随机探索获得正确解决方案来获取奖励。正如Sakana团队所指出的,基于一次性正确性的RL训练"依赖于语言模型在初始化时具备一定概率探索并解决任务的能力"。换言之,在困难任务上开始RL训练需要一个具备相当基础能力的大型模型。
第三个问题是过拟合到狭窄任务分布。那些成功通过此类训练的模型往往会过度适应狭窄的任务分布,在训练问题上表现出色,但在该领域之外的泛化能力有限。我们在专门的数学和编程LLM中观察到这种现象——它们在基准测试中表现优异,但在其他场景下的通用性不足。
为应对这些挑战,业界通常采用两阶段训练流程:首先通过RL在困难任务上训练巨型教师模型,然后利用该教师的解决方案来指导学生模型的训练(知识蒸馏)。例如,DeepMind的DeepSeek R1(具有671B参数)经过RL训练来解决问题,其生成的推理轨迹经过过滤后用于训练更小的模型。虽然这种方法有效,但存在明显的效率问题。
这种传统方法需要一个巨大且成本极高的模型来完成RL阶段。教师模型的训练目标(解决问题)与实际需求(生成易于学生学习的解释)之间存在不一致。此外,巨型教师的输出通常需要大量后处理工作(甚至需要GPT-4进行清理)才能成为合适的教学材料。
从工程实践角度来看,这种方法包含大量计算资源浪费、人工干预的过滤步骤,以及清理输出的外部API调用。显然需要更精简高效的解决方案。
https://avoid.overfit.cn/post/86bb83c383014a5692090b7b6aae971e

 浙公网安备 33010602011771号
浙公网安备 33010602011771号