Adaptive-k 检索:RAG 系统中自适应上下文长度选择的新方法
本文介绍 Adaptive-k 检索技术,这是一种通过相似性分布分析动态确定最优上下文规模的即插即用方法,该技术在显著降低 token 消耗的同时实现了检索增强生成系统的性能提升。
在检索增强生成(RAG)技术快速发展的当前阶段,一个核心问题始终困扰着研究人员和工程师:如何确定最优的上下文长度?
上下文过少可能导致关键信息的缺失,而上下文过多则会引入噪声并大幅增加 token 消耗。随着长上下文语言模型(LCLM)技术边界的不断拓展,这一挑战变得更加突出。尽管这些模型理论上可以处理数百万个 token,但实际应用中,随着上下文长度的增加,模型性能往往出现下降,同时成本急剧上升,延迟也变得不可接受。
针对这一技术挑战,研究人员提出了 Adaptive-k 检索技术——一种能够根据查询特征自动确定最优上下文检索数量的方法。该方法无需模型微调、迭代提示或访问模型内部状态,具有显著的实用价值。
固定检索策略的技术局限性
传统 RAG 系统采用固定规模检索策略,通常检索前 k 个文档(如前 5、前 10 个),而不考虑查询复杂度或相关信息的分布特征。这种方法存在根本性的设计缺陷。
考虑两种典型的查询场景:事实性查询(如"法国的首都是什么?")仅需要一个精确的事实信息,而聚合性查询(如"加州哪些大学的学生人数超过 10,000 人?")则需要全面的证据收集。现有系统对这两种查询类型采用相同的处理策略,无论所需信息密度如何,都检索相同数量的上下文。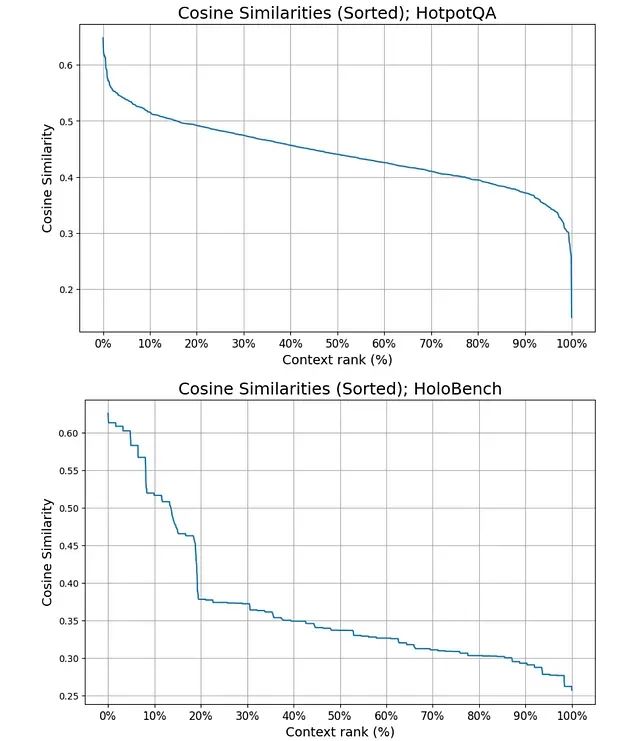
图为HELMET (Yen et al., 2025) 中包含的长上下文版本 HotpotQA (Yang et al., 2018)(包含 1,000 个上下文文档,顶部)和 HoloBench (Maekawa et al., 2025)(包含 10% 相关信息量,底部)的已排序余弦相似性示例分布。使用 BAAI 的 bge-large-en-v1.5 作为嵌入模型。
这种策略导致的问题包括:计算资源在不相关上下文上的浪费、信息过载导致的性能下降、不同查询类型结果的不一致性,以及随着上下文窗口扩展而产生的可扩展性问题。
https://avoid.overfit.cn/post/6ad4c8a71bb146c89f1c987f0d3a6aed

 浙公网安备 33010602011771号
浙公网安备 33010602011771号