基于内存高效算法的 LLM Token 优化:一个有效降低 API 成本的技术方案
在使用 OpenAI、Claude、Gemini 等大语言模型 API 构建对话系统时,开发者普遍面临成本不断上升的挑战。无论是基于检索增强生成(RAG)的应用还是独立的对话系统,这些系统都需要维护对话历史以确保上下文的连贯性,类似于 ChatGPT 对历史对话的记忆机制。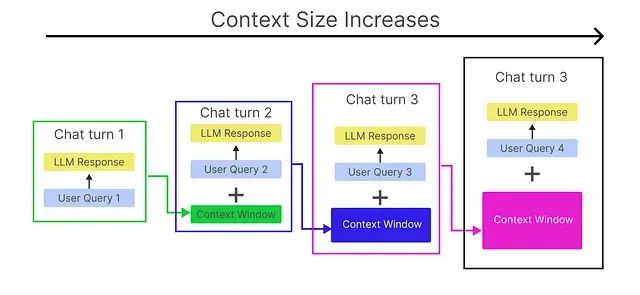
这种历史记忆机制虽然提升了对话质量,但同时导致了 Token 消耗的指数级增长。本文提出一种内存高效算法,通过智能化的内存管理策略,将 Token 使用量减少高达 40%,从而显著降低 LLM 推理的运营成本。
https://avoid.overfit.cn/post/5feb4f4f31ed41d1850a01e6d7a78e6a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号